《HPC高性能计算工程师》专题
-
SQL-计算预测平均值
问题内容: 我正在尝试根据前三个月的实际情况或预测来计算销售预测。 假设我要计算 每个 公司未来18个月的预测。 我正在查看去年的数据。一些公司有例如2个月的数据,而其他12个月等等。 我已经搜索并找到了许多不同的解决方案,但是所有这些解决方案都只考虑了实际情况。 我认为我必须进行递归CTE,但我无法弄清楚。 请帮忙 :) 问题答案: 因此,您想要基于先前的移动平均线的移动平均线:)我认为,在SQ
-
在Tensorflow中计算jacobian矩阵
问题内容: 我想通过Tensorflow计算Jacobian矩阵。 是)我有的: 是损失函数,都是可训练的变量,并且是许多数据。 但是,如果我们增加数据数量,则需要花费大量时间来运行该功能。有任何想法吗? 问题答案: 假设和是Tensorflow张量,并且取决于: 结果具有形状,并提供的每个元素相对于的每个元素的偏导数。
-
如何在python中计算skipgrams?
问题内容: k跳过图是一个ngram,它是所有ngram和每个(ki)跳过图直到(ki)== 0(包括0个跳过克)的超集。那么,如何在python中有效地计算这些skipgram? 以下是我尝试过的代码,但未达到预期的效果: 上面的代码无法正确渲染,但是打印后输出如下 [[‘this’,’happened’,’more’],[‘happened’,’more’,’or’],[‘more’,’or’
-
AngularJS:计算过滤的项目
问题内容: 如果选中了复选框,我将显示列表的子集。我想将复选框旁边的X替换为与选择标准匹配的列表的计数。我有一个笨拙的人,除了在这里计算子集之外,什么都做。 我的控制器如下所示: 我的看法如下所示: 问题答案: 您可以在绑定数据时在视图模型本身中设置该计数,或者在作用域上只有一个返回计数的方法。 并将其用作:- 普伦克 如果您在页面上时列表不变,我建议您找出长度并将其绑定到视图模型本身的属性中,然
-
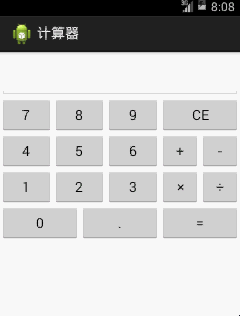 Android计算器编写代码
Android计算器编写代码本文向大家介绍Android计算器编写代码,包括了Android计算器编写代码的使用技巧和注意事项,需要的朋友参考一下 其实这个安卓计算机,所有的后台思想与《C#计算器编写代码》是一模一样的。Win窗体程序移植到安卓,从C#到Java其实很简单的,因为两者的基本语法都很相像,唯一的难点是安卓的xml布局部分,不像C#窗体能够直接拖。 还是如下图一个能够完成基本四则运算的计算器: 先在res\v
-
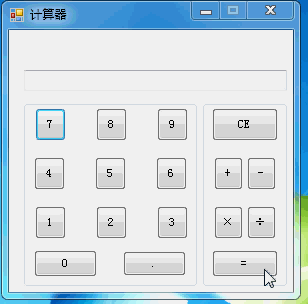 C#计算器编写代码
C#计算器编写代码本文向大家介绍C#计算器编写代码,包括了C#计算器编写代码的使用技巧和注意事项,需要的朋友参考一下 利用C#编写一个计算器。如下图,能够完成基本的四则运算。 当然这个程序甚至还不上Windows附件那个自带的多功能计算器。 不过这个程序的逻辑还是非常值得思考的,首先你要考虑好用户按+ - * / =等运算符号、数字键之后计算器的状态记录问题。 然后要防止多次按某一个键的问题。比如小数点.就不应
-
 js实现简单计算器
js实现简单计算器本文向大家介绍js实现简单计算器,包括了js实现简单计算器的使用技巧和注意事项,需要的朋友参考一下 参考部分资料,编写一个简单的计算器案例,虽然完成了正常需求,但是也有不满之处,待后续实力提升后再来补充,先把不足之处列出: 1:本来打算只要打开页面,计算器的输入框会显示一个默认为0的状态,但是在输入框加入默认显示为0的时候,选择数据输入时,该0会显示输入数字的前面,例如”0123“,由于能力有
-
本地计算机生成CSR
如何在cmd上运行csr生成命令。exe openssl req-节点-newkey rsa: 2048-keyoutwww_mydomain_com.key-outwww_mydomain_com.csr-subj"/C=BB/ST=CCC/L=DDD/O=EEE。/OU=IT/CN=mydomain.com"
-
PHP:计算一个stdClass对象
问题内容: 我有一个从json_decode创建的stdClass对象,当我运行count($ obj)函数时不会返回正确的数字。该对象具有30个属性,但count()函数的返回值为1。 有任何想法吗? 以下是其中一个对象的示例。(我正在从Twitter请求每日趋势信息)。如果此对象具有多个属性,则count($ obj)等于1。 问题答案: 问题在于count的目的是对数组中的索引进行计数,而不
-
在Django QuerySet上计算vs len
问题内容: 在Django中,假设我要遍历并打印结果,那么计算对象的最佳选择是什么?还是? (此外,考虑到在同一迭代中对对象进行计数也不是一个选择。) 问题答案: 尽管Django文档建议使用而不是: 注意:如果要确定的是记录集中的记录数,请不要在QuerySet上使用。使用SQL的在数据库级别处理计数效率更高,而Django为此提供了一种方法。 由于无论如何都要迭代此QuerySet,结果将被缓
-
 Vue实现手机计算器
Vue实现手机计算器本文向大家介绍Vue实现手机计算器,包括了Vue实现手机计算器的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了Vue制作仿手机计算器的具体代码,供大家参考,具体内容如下 1.首先是把样式做出来,按钮是0-9,还有加减乘除,百分号,清除按钮,小数点,等号、等等 2.把官方网站的JS插件引用,cn.vuejs.org/v2/guide/ 页面视图 JS 以上就是本文的全部内容,希望对大家
-
 python GUI计算器的实现
python GUI计算器的实现本文向大家介绍python GUI计算器的实现,包括了python GUI计算器的实现的使用技巧和注意事项,需要的朋友参考一下 01 实现 我们几乎每个人都用过计算器,大家对于计算器应该都是比较熟悉的,计算器整体也是比较简单的,主要包括:显示器、键盘、运算的逻辑处理等,计算器的图形界面我们使用 tkinter 库实现,下面看一下具体实现过程。 首先,我们画一个主窗口,代码实现如下: 看一下效果:
-
Vue中的方法vs计算
Vue中和之间的主要区别是什么。js? 它们看起来一样,可以互换。
-
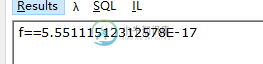 浅谈c# 浮点数计算
浅谈c# 浮点数计算本文向大家介绍浅谈c# 浮点数计算,包括了浅谈c# 浮点数计算的使用技巧和注意事项,需要的朋友参考一下 给大家看个计算题,看看大家的算术能力。 0.1 +0.1 +0.1 - 0.3 等于几? 大家可能会说这么简单的问题,是不是看不起我?肯定等于0啊。 如果大家直接算的是没有问题的,但是如果用计算机呢? 见证奇迹的时刻到了,看代码: 运行结果: 这是因为计算机的精度的问题,在计算机的内部存储和运算
-
python字符串,数值计算
本文向大家介绍python字符串,数值计算,包括了python字符串,数值计算的使用技巧和注意事项,需要的朋友参考一下 Python是一种面向对象的语言,但它不像C++一样把标准类都封装到库中,而是进行了进一步的封装,语言本身就集成一些类和函数,比如print,list,dict etc. 给编程带来很大的便捷 Python 使用#进行单行注释,使用 ''' 或 """ 进行多行注释 数值计算 字