《无人车规划算法实习》专题
-
算法题 - hash表算法
第一部分:Top K 算法详解 问题描述 百度面试题: 搜索引擎会通过日志文件把用户每次检索使用的所有检索串都记录下来,每个查询串的长度为1-255字节。 假设目前有一千万个记录(这些查询串的重复度比较高,虽然总数是1千万,但如果除去重复后,不超过3百万个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。),请你统计最热门的10个查询串,要求使用的内存不能超过1G。 必备知识 什么是哈
-
 2023.7.3 科大讯飞提前批 飞凡计划 CV算法 凉经
2023.7.3 科大讯飞提前批 飞凡计划 CV算法 凉经1.自我介绍。主要介绍一下在项目中遇到的一些问题以及解决方式,以及对团队的一些贡献 2.没实习,问了一下研究是横向还是纵向,问了导师的研究方向和实验室的研究方向(可能我的方向有点偏orz) 3.问了一下有论文产出没(被拒在投) 4.介绍一下目前研究方向的背景 5.介绍一下当前研究方向的优势(为啥要研究这个方向) 6.介绍一下NAS相关的算法(项目涉及) 7.问哪里人,能否接受地域(就说平台好就行了
-
JSON语法规则
主要内容:JSON 中的键,JSON 中的值,JSON 与 JavaScript 对象的区别JSON 的语法与 JavaScript 中的对象很像,在 JSON 中主要使用以下两种方式来表示数据: Object(对象):键/值对(名称/值)的集合,使用花括号定义。在每个键/值对中,以键开头,后跟一个冒号,最后是值。多个键/值对之间使用逗号分隔,例如; Array(数组):值的有序集合,使用方括号定义,数组中每个值之间使用逗号进行分隔。 下面展示了一个简单的 JSON 数据: 注意:所有
-
 CSS语法规则
CSS语法规则CSS 样式由一系列规则组成,这些规则由 Web 浏览器解析,然后应用于 HTML 文档相应的元素上。CSS 样式规则由三个部分组成,分别是选择器、属性和值: 选择器:由 HTML 元素的 id、class 属性或元素名本身以及一些特殊符号构成,用来指定要为哪个 HTML 元素定义样式,例如选择器就表示为页面中的所有标签定义样式; 属性:您希望给 HTML 元素设置的样式名称,由一系列关键词组成,
-
python实现淘宝秒杀聚划算抢购自动提醒源码
本文向大家介绍python实现淘宝秒杀聚划算抢购自动提醒源码,包括了python实现淘宝秒杀聚划算抢购自动提醒源码的使用技巧和注意事项,需要的朋友参考一下 说明 本实例能够监控聚划算的抢购按钮,在聚划算整点聚的时间到达时发出提醒(音频文件自己定义位置)并自动弹开页面(URL自己定义)。 同时还可以通过命令行参数自定义刷新间隔时间(默认0.1s)和监控持续时间(默认1800s)。 源码 以上就是本文
-
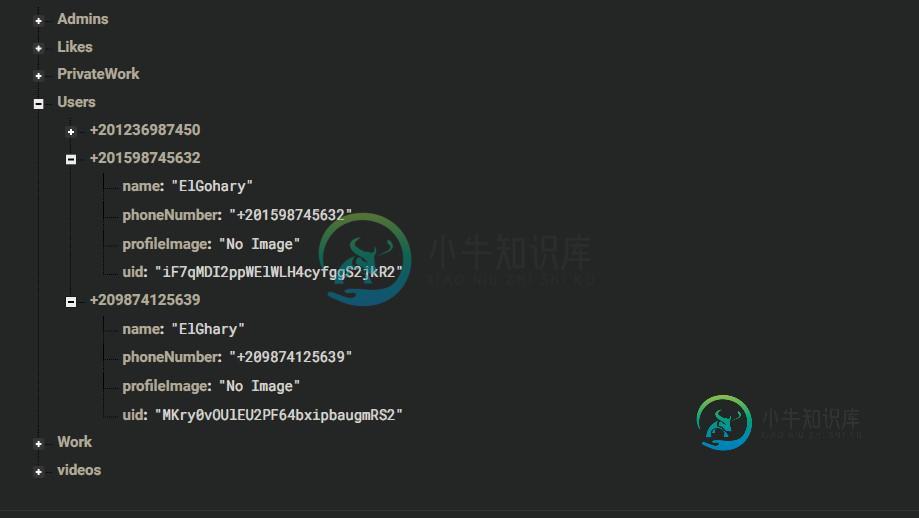 Android:实时Firebase规则
Android:实时Firebase规则我想知道如何确保我的规则。我试着使用
-
无法理解此图形表示(需要算法!)
我一直在努力理解这个图表演示文稿,但没有任何适当的解决方案。也许有人能想出办法。 我有一个连接的,无周期的图形的演示,其形式如下: < li >逐个删除度数为1(只有一条边)的顶点 < li >如果有多个选项,将移除具有最低值的顶点 < li >当顶点被删除时,它旁边的顶点将被标记 < li >这将继续下去,直到图形只剩下一个顶点 这是一个示例图: 这就是演示文稿的形式: 因此,该图的表示形式为:
-
Windows 2008 R2 任务计划程序无法执行命令
在我的Windows Server 2008 R2计算机上,计划使用任务计划程序运行批处理文件。由于某些原因,仅执行批处理文件中的部分命令;一些命令被忽略。 批处理文件如下所示: 当我通过双击运行批处理文件时,一切都按预期运行;但是当它从任务调度程序执行时,只有部分正确运行。命令似乎没有运行。即使我将命令替换为或或任何其他命令,它也不会运行。 即使我更改批处理文件中命令的顺序,命令也不会运行。但是
-
Dropwizard使用日晷计划作业无法访问会话
我正在尝试使用dropwizer-日记本来安排工作。在我的预定工作中,我需要访问我的DAO。每当我计划的作业运行时,我都会收到以下错误... 我试图使用这个链接中描述的方法,https://github.com/timmolter/XDropWizard在注入全局对象或配置参数到作业一节中 这是我的申请代码: 这是我预定的工作: 我正在获取DAO,它们不是空的,但它们不绑定到任何会话。我该怎么解决
-
火车车次查询
基于网络请求,接受xml,并解析返回的xml,从而得到列车车次信息。 [Code4App.com]
-
 拼多多算法实习三面(主管面)
拼多多算法实习三面(主管面)拼多多算法暑期实习三面,也叫主管面,一共30min就结束,前20min介绍了下之前做的项目,有的模型细节还深入问了下,没答出来 后面直接做算法题:链表的一个合集(快慢指针+反转链表+合并链表) 反问:如果有offer的定岗问题 这一面和上一面隔了好久,一度以为二面挂了 这次面试问了几个细节的问题没答出来 也以为凉了 没想到隔了几天收到HR面的通知了 #面经#
-
 2023暑期实习-拼多多算法面经
2023暑期实习-拼多多算法面经拼多多的算法只有一个岗位,而且是做搜广推相关的,其实方向上不太match,不过还是捞起来面了(不知道是不是笔试还可以,A了3.9/4) 1、代码题 “既然我们是校招,先来做个题吧 ” n个人排队上电梯,每个人有p的概率上电梯,1-p的概率不上电梯,如果他不上排在他后面的人也没法上,问t时刻电梯上人数期望 一开始没明白是代码题,当成数学题做了,如果人数n大于时刻t,那么可以保证每个时刻都有人处于要上
-
 2023暑期实习-字节TikTok算法面经
2023暑期实习-字节TikTok算法面经岗位是计算机视觉-电商业务,具体是做TikTok用户带货能力的预估,会用到一些多模态的技术。 多任务模型多个任务的训练数据是怎样获取的,同一个场景只存在一个任务的标签怎么处理 CenterNet的基本原理,跟其他的Anchor Free方法相比有什么优点 代码题:以一个亿量级的数组为模板,删除掉百万量级数组重复出现的元素(想了半天没想到啥好方法,说用哈希表,然后被追问了一下哈希表的原理) 代码题:
-
 4.17京东供应链算法实习一面
4.17京东供应链算法实习一面个人情况:某C9本硕 本数学 硕统计 熟练使用R,sql。 python水平一般 无任何实习或项目经历。 共1h 总结我是被薄纱。 自我介绍。 项目介绍。(又又又讲的课题) svm相关问题。 lasso相关问题。 判别分析相关问题。(答得稀烂) spark (不会) sql join介绍。 pandas中如何实现同样功能? 数据处理:可视化/特征工程/异常点检验 (我完全没有这方面经验) 非参数方
-
 探探-推荐算法-日常实习面经
探探-推荐算法-日常实习面经一面: 1. 对推荐算法大概有多少了解 2. kaggle比赛用了什么模型,做了什么优化 3. 你是如何把几个模型的分数做融合的 4. 如果这个权重也作为一个变量参与到训练,这种方式和你手动调参相比会有什么样的差异呢 这题我回答的是串行训练会更多耗时,但是参数精度会提高效果会更好,但是总觉得还是没答到点子上 5. 随机森林的具体运行过程 6. 如何判断过拟合和欠拟合,怎么解决 7. 如何解决梯度消