《知识图谱》专题
-
Java命名实体识别库
问题内容: 我正在寻找Java的简单但“足够好”的命名实体识别库(和字典),我正在处理电子邮件和文档并提取一些“基本信息”,例如:名称,地点,地址和日期 我一直在环顾四周,大多数似乎都是沉重的一面和完整的NLP项目。 有什么建议吗? 问题答案: 顺便说一句,我最近遇到了OpenCalais,它似乎具有我要照顾的功能。
-
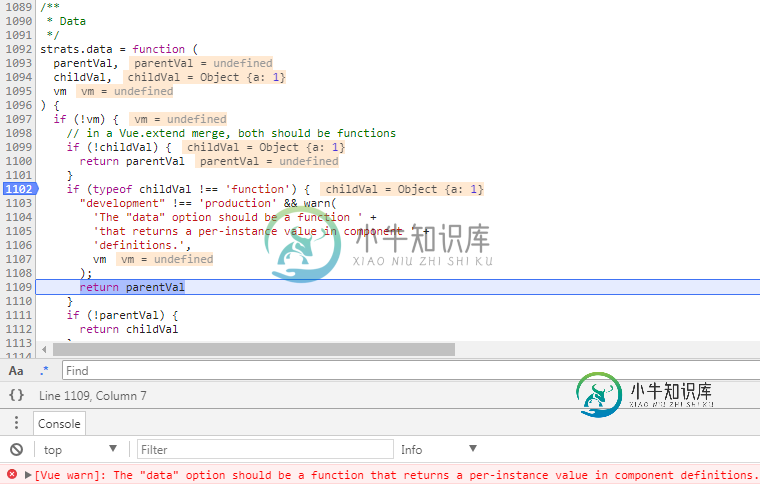 初识 Vue.js 中的 *.Vue文件
初识 Vue.js 中的 *.Vue文件本文向大家介绍初识 Vue.js 中的 *.Vue文件,包括了初识 Vue.js 中的 *.Vue文件的使用技巧和注意事项,需要的朋友参考一下 什么是Vue.js? vue.js是一套构建用户界面的渐进式框架,它采用自底向上增量开发的设计。(自底向上设计方法是根据系统功能要求,从具体的器件、逻辑部件或者相似系统开始,凭借设计者熟练的技巧和丰富的经验,通过对其进行相互连接、修改和扩大,构成所要求的系
-
Flink和动态模板识别
我们计划使用Flink CEP根据一些动态模板处理大量事件。系统必须识别事件链(有时是带有条件和分组的复杂链)。模板将由用户创建。换句话说,我们必须在不接触代码的情况下创建复杂的模板。是否可以使用Apache Flink解决此问题?Filnk是否支持动态模板?
-
ORA-00904:“strdef”:无效标识符
ORA-00904:“strdef”:无效标识符 > Oracle数据库版本为: Oracle Database 11g Enterprise Edition版本11.2.0.4.0-64位Production PL/SQL版本11.2.0.4.0-Production“Core 11.2.0.4.0 Production”TNS for Linux:版本11.2.0.4.0-Production
-
SQL Server:更改标识种子
我试着用谷歌搜索如何做到这一点,但是我所有的谷歌搜索都得到了结果,人们想要更改标识列的内容,而不仅仅是更改标识种子号。有没有一个简单的查询我可以用来完成我想要做的事情?
-
ORA-00904:“STRDEF”:无效标识符
我得到这个错误,而在Oracle数据库中执行查询: ORA-00904:“STRDEF”:无效标识符 > Oracle Database 11g Enterprise Edition 11.2.0.4.0版-64位生产PL/SQL 11.2.0.4.0版-生产“CORE 11.2.0.4.0生产”Linux版TNS:11.2.0.4.0版-生产NLSRTL 11.2.0.4.0版-生产 STRDE
-
印度地名识别模型
我计划使用命名实体识别(NER)技术从给定文本中识别人名(大部分是印度名字)。我已经从斯坦福NLP探索了基于CRF的NER模型,但是它在识别印度名字方面并不十分准确。因此,我决定通过监督培训创建自己的自定义NER模型。我对如何使用斯坦福大学的NER CRF创建自己的NER模型有一个大致的想法,但创建一个带有手动注释的大型训练语料库是我想避免的事情,因为这对个人来说是一项巨大的工作,其次,从印度不同
-
Azure kubernetes-多个托管标识?
我们计划在我们的单个Azure kubernetes集群上部署多个应用程序,每个应用程序都将拥有自己的一组Azure资源-例如:Key vault、Storage。 我计划为每个应用程序提供个人托管身份,并提供对相关资源的访问。 我知道AZURE AAD POD identify是配置POD以使用托管标识访问AZURE资源的方法。 但是,如何将多个托管标识添加到Azure kubernetes集群
-
ELK - Kibana不识别geo_point字段
我正试图在基巴纳创建一个带有地理位置点的平铺地图。出于某种原因,当我尝试创建地图时,我在Kibana上收到以下消息: 没有兼容的字段:“日志”索引模式不包含以下任何字段类型:geo_point 我的设置: Logstash (版本 2.3.1): 当日志输入到达时,我可以看到它按照应该的方式解析它,并且我确实获得了给定IP的地理IP数据: ElasticSearch(版本 2.3.1): GET
-
AmazonDynamoDBv2查询无法识别GSI
当我在GSI上查询时,我对Amazon DynamoDBv2的Amazon DynamoDBAsync.query异步请求的实现返回代码400“查询条件错过了关键模式元素......”。 我尝试使用DynamoDBAttribute名称(“myAttr”)和GSI的实际索引名称(“idx\u global\u myAttr”),并收到相同的错误代码。这与Docker的图片“amazon/dynam
-
离线语音识别失败
在飞行模式下,按下按钮,一个声音退出输入屏幕,输入出现的声音请重新输入,上周可以正常使用,谷歌很长时间找不到解决方案,希望帮助离线谷歌语音已经设置好 公共void onclick1(视图v) { } 受保护的void onActivityResult(int requestCode、int resultCode、Intent data){ }
-
Android语音识别API脱机
有人能帮我吗? 我正在开发一个通过RecognizerIntent进行语音识别的应用程序。 哪一个Android版本正式带来了API对应用程序的离线识别?有什么声明吗 据我所知,如果语音识别将通过在线服务或离线词典完成,开发人员无法选择。我说得对吗?或者是否有任何记录在案的API可以脱机设置 谢谢
-
启用识别连续语音
如何使用REST API(带javascript SDK)Bing语音API实现连续语音识别? 使用do Javascript SDK示例:https://github.com/Microsoft/Cognitive-Speech-STT-JavaScript只能用麦克风转录短句
-
语音相关语音识别
我正在为嵌入式设备的语音相关语音识别解决方案寻找解决方案。我已经研究过Pocketsphinx,但由于我仍然不熟悉它,我想也许更有经验的人可能会知道。是否有可能使用Pocketsphinx来实现这样的语音识别。它应该记录音频,提取其特征,然后将其与所说的任何内容进行匹配,而不是使用声学和语言模型。是否有可能使用Pocketsphinx实现此流程?如果没有,有人能为这样的解决方案指出正确的方向吗?谢
-
谷歌电影语音识别
我用Google API对自然对话的语音识别取得了很好的效果,但是对于Youtube视频或电影中的声音,识别效果很差或根本不存在。 在iPhone 4上录制西班牙语到英语的声音是可以识别的,但在电影中使用同一部手机几乎是不可能的,即使是一个角色在几乎没有背景噪音的情况下说话的场景。只有一次成功。 我试图清理声音与SoX(声音交换)使用噪声和comand efects,没有任何成功。 有什么想法吗?