《知识图谱》专题
-
Drools:从LHS模式获取标识符
我正在使用Drools 6.3.0决赛。假设我有这样的规则 让我们进一步假设我用这个规则构建了KieSession,添加了一些事实,现在我想知道所有规则/所有与我的事实匹配的规则中使用的标识符。 所以我想在这里得到的是$人和$孩子。 我知道我可以获取使用AgendaEventListener触发的规则,从事件中我可以获取规则的名称,以及$person和$child的对象。但我没有找到从匹配中获取标
-
为什么ReactorMono被识别为空Mono?
这是一段代码 这将向控制台提供以下结果: 这意味着第一个中的链被识别为空链。 另一方面,Reactor具有以下类MonoEmpty,该类由Mono返回。empty()方法。除此之外,该方法还包括以下内容: 没有发出任何项,但我用方法发出了类型化对象。 对此有何解释?
-
如何使用iOS 10语音识别?
如何将音频转录成文本在iOS10使用Speech.framework?
-
使用PocketSphinx识别多个关键字
我已经安装了PocketSphinx演示,它在Ubuntu和Eclipse下运行良好,但是尽管尝试过,我还是不知道如何添加对多个单词的识别。 我只想让代码识别单个单词,然后我可以在代码中,例如“up”、“down”、“left”、“right”。我不想识别句子,只想识别单个单词。 在这方面的任何帮助都将不胜感激。我发现其他用户也有类似的问题,但到目前为止还没有人知道答案。 让我困惑的一件事是,为什
-
 python+opencv实现动态物体识别
python+opencv实现动态物体识别本文向大家介绍python+opencv实现动态物体识别,包括了python+opencv实现动态物体识别的使用技巧和注意事项,需要的朋友参考一下 注意:这种方法十分受光线变化影响 自己在家拿着手机瞎晃的成果图: 源代码: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
JS的事件绑定深入认识
本文向大家介绍JS的事件绑定深入认识,包括了JS的事件绑定深入认识的使用技巧和注意事项,需要的朋友参考一下 一、传统事件模型 传统事件模型中存在局限性。 内联模型以HTML标签属性的形式使用,与HTML混写,这种方式无疑造成了修改以及扩展的问题,已经很少使用了。 脚本模型是将事件处理函数写到js文件中,从页面获取元素进行对应事件函数的绑定以触发执行。但也存在不足之处: 1.一个事件绑定多个事件监听
-
MATLAB使用Profiler识别性能瓶颈
本文向大家介绍MATLAB使用Profiler识别性能瓶颈,包括了MATLAB使用Profiler识别性能瓶颈的使用技巧和注意事项,需要的朋友参考一下 示例 MATLAB Profiler是用于对MATLAB代码进行软件配置的工具。使用探查器,可以获得执行时间和内存消耗的直观表示。 运行Profiler可以通过两种方式完成: .m在编辑器中打开一些文件(在R2012b中添加)时,单击MATLAB
-
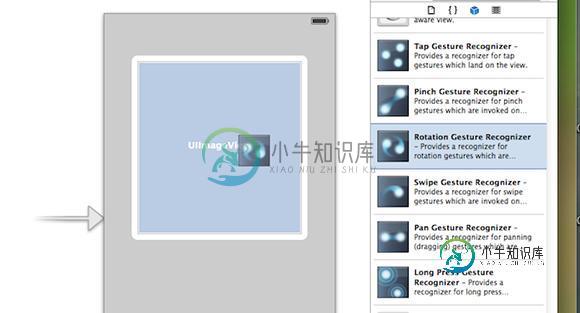 iOS开发之手势识别实例
iOS开发之手势识别实例本文向大家介绍iOS开发之手势识别实例,包括了iOS开发之手势识别实例的使用技巧和注意事项,需要的朋友参考一下 感觉有必要把iOS开发中的手势识别做一个小小的总结。下面会先给出如何用storyboard给相应的控件添加手势,然后在用纯代码的方式给我们的控件添加手势,手势的用法比较简单。和button的用法类似,也是目标 动作回调,话不多说,切入今天的正题。 总共有六种手势识别:轻击手势(TapGe
-
远程weblogic服务器标识异常
-
在java中无法识别Unicode字符
我创建了一个java代码来存储上传的文本文档。然后我返回该文件中的文本。所有文本均为“僧伽罗语”。UTF-8编码文本 输出直接发送到jsp页面,在那里显示为'??????????????'。 Windows 8.1、tomcat和java版本7。我已经用僧伽罗字符测试了jsp,它们正在工作。我添加了UTF-8作为内容类型。 我试过这个,这个,还有这个。
-
Android上的长音频语音识别
我想开发一个模块,它将使用Android中的语音到文本支持。我发现了许多与RecogenerIntent等相关的文档和演示。但我发现所有这些演示都只是在10秒左右的时间里播放声音。但我想让我的演示运行5-10分钟以上。如果不是离线运行,我不会有任何问题,因为我的应用程序总是在线运行。 我也看过Android上的Pocketsphinx,但效果不太好。此外,它只支持Android Studio,而不
-
google云语音api实时流识别
我已经实现了云语音API流识别服务。我能够通过FLAC文件并获得输出,但它不能连续识别,也不能发出放着还在说话。一旦我的录音完成,那么只有我从云API得到响应。请建议我如何从谷歌语音API获得连续识别。请帮助我
-
使用CMU Sphinx进行数字识别
Hi识别专家, 我有很多的mp3文件(原创音源流采样是11.025千赫)包含数字(0-9)。 不同的说话者(男性/女性)说“一”、“七”、“三”等,中间有停顿(约2-2.5秒) 我要用CMU Sphinx来识别语音(桌面应用程序)。所以我有一些问题: > 声学模型:如果不对流进行上采样/下采样,如何找到支持11025 kHz的声学模型。如果我这样做,什么是最好的数字模型? 识别模式:我发现转录有两
-
耳语时的简单语音识别
我正在尝试使用pocketsphinx进行简单的语音到文本映射(语法非常简单,例如: 例如: 收益率 我调整了声学模型(考虑到我的外国口音),之后我获得了不错的表现(约94%的准确率)。我使用了约3分钟的训练集。现在我正在尝试做同样的事情,但对麦克风耳语。准确率显着下降到约50%,不需要训练。通过口音训练,我获得了约60%。我尝试了其他想法,包括去噪和提高音量。我阅读了整个文档,但想知道是否有人可
-
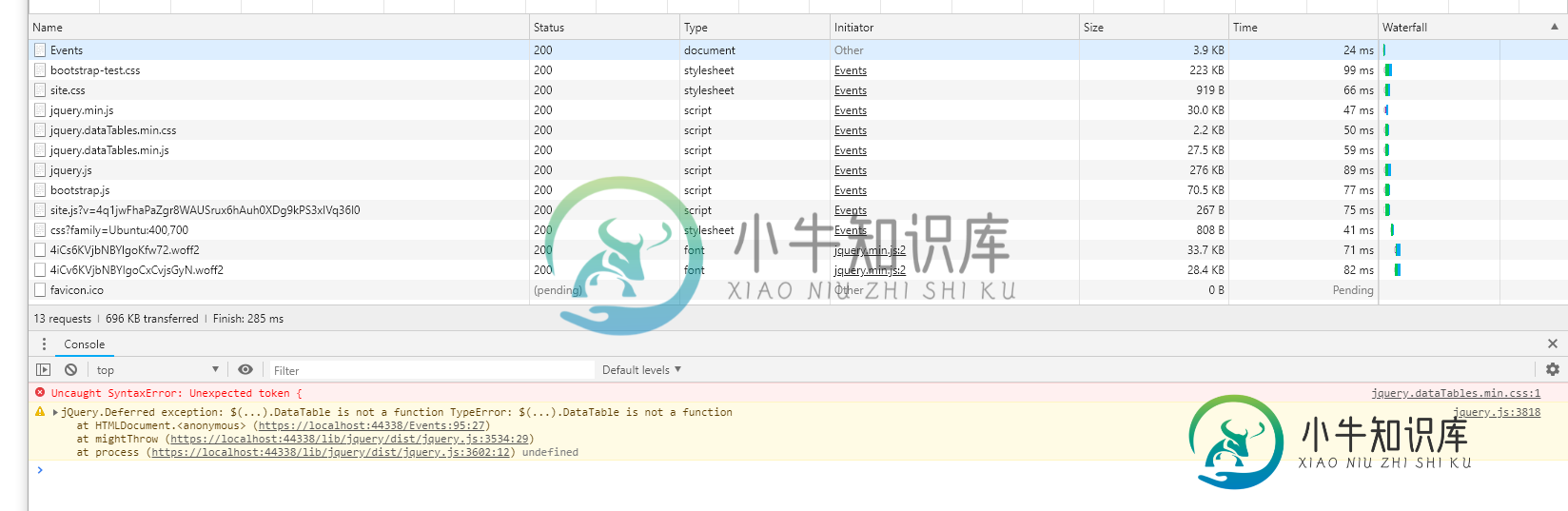 Datatable不是函数,无法识别js
Datatable不是函数,无法识别js我有一个小麻烦使用的日期。 我想我已经先用jquery声明了我的源代码,然后用datatable声明了我的源代码(我在他们的网站上检索包含最新版本的链接),但是当我加载网页时,我总是会收到相同的错误消息: 未捕获的语法错误:意外的标记{jQuery。延迟的异常:$(…)。DataTable不是函数类型错误:$(…)。DataTable不是一个函数 这显然是一个已知的问题,经过一些研究后我意识到了这