《英特尔》专题
-
 英特尔FLEX_SE面经
英特尔FLEX_SE面经本人背景算法工程师,cv方向论文两篇,nlp实习经历。 一轮 25min 自我介绍 询问项目论文 问题:resnet架构、c++程序执行过程 反问 二轮 40min 自我介绍 询问项目论文(论文很细致,结构、损失、数据集、实验结果、创新点) 问题:Transformer架构、核心公式以及采用什么的正则化、BN和LN的区别。其实大部分是根据论文内容发散 反问 三轮HR面 25min 没有自我介绍 问
-
Hotspot7 hsdis PrintAssembly英特尔语法
问题内容: 每次与Hotspot一起使用时,都不得不烦恼我,不得不阅读可怕的AT&T语法。 有没有办法告诉它使用英特尔语法? 问题答案: 您所需要做的就是将一些选项解析到dis-asm.h和binutils代码上 对于Intel Asm(我也更喜欢),只需添加以下内容 如果您需要组合选项,请像这样用逗号分隔 任何未被识别为hsdis选项的内容都将被提供给反汇编程序,这些选项与您从中看到的选项相同
-
什么是英特尔微码?
问题内容: 从我读到的内容来看,它用于修复CPU中的错误,而无需修改BIOS。根据我对汇编的基本知识,我知道汇编指令在内部由CPU分解为微代码,并相应地执行。但是intel以某种方式可以在系统启动和运行时进行一些更新。 有人有更多信息吗?是否有关于微码可以做什么以及如何使用的文档? 编辑:我读过维基百科的文章:没弄清楚我怎么能自己写一些,以及它有什么用。 问题答案: 在较早的时期,微代码在CPU中
-
英特尔伽利略和C REST SDK
我已经成功地设置了我的英特尔伽利略板(第2代)与最新的Windows IoT映像(2/12/2014)。我可以引导图像没有任何问题,telnet到它和运行'眨眼'应用程序罚款。 我试着运行“卡萨布兰卡”样本,并按照http://ms-iot.github.io/content/Casablanca.htm.当我远程登录Galileo板并尝试运行控制台应用程序时,我根本没有得到任何输出。尝试从Vis
-
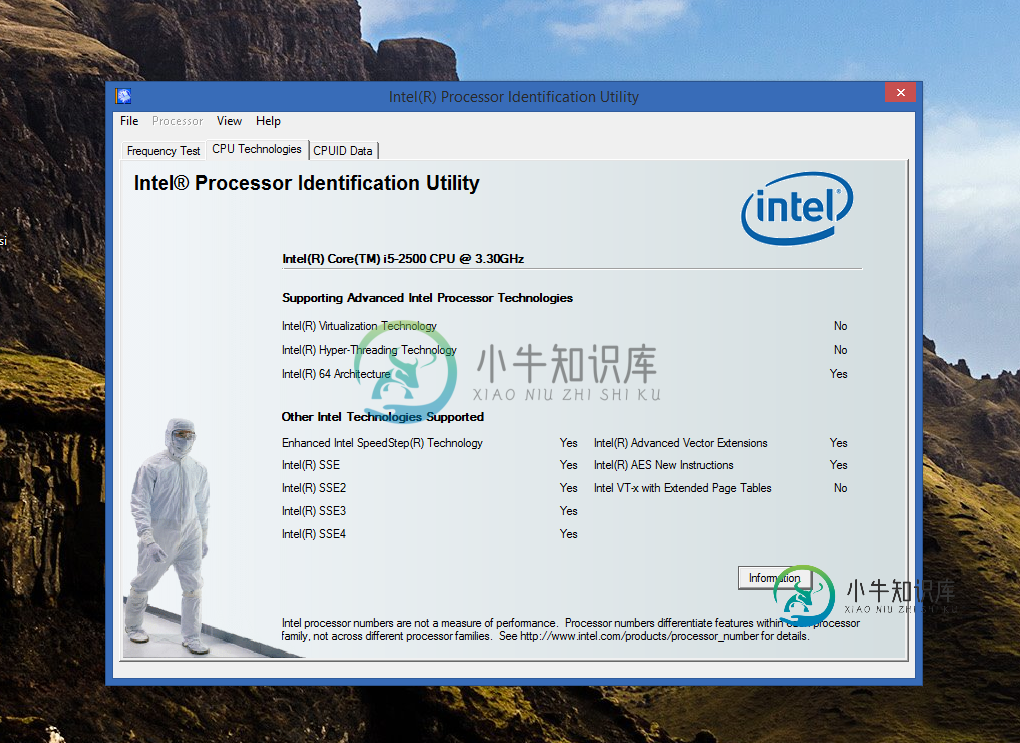 启用英特尔虚拟化技术
启用英特尔虚拟化技术我想安装英特尔 HAXM(使 Android 模拟器更快),但安装程序显示我的计算机“不支持虚拟化技术 (VT-x)”。 在BIOS中,我看到我启用了虚拟化技术,并且我还有运行良好的Windows Phone模拟器(需要这项技术)。 我下载了Intel Identification Utility,它说我的Processor不支持这项技术(尽管上面的事实和互联网上的搜索表明我的i5确实支持这项科技
-
如何在Java中使用英特尔AVX?
如何使用Java中的Intel AVX矢量指令集?这是一个简单的问题,但答案似乎很难找到。
-
英特尔SFENCE有发布语义学吗?
似乎获得和释放语义学的公认定义是这样的:(引用自http://msdn.microsoft.com/en-us/library/windows/hardware/ff540496(v=vs.85). aspx) 如果其他处理器总是在任何后续操作的效果之前看到其效果,则该操作具有acquire语义。如果其他处理器在操作本身的效果之前看到前面每个操作的效果,则操作具有释放语义。 我简单地读过关于半记忆
-
英特利杰抱怨JDK位置
第一张图片 第二图像 当我附上两张图片时,我在运行用groovy编写的spring boot gradle项目时遇到了问题。 我一打开项目,intellij就试图构建项目,但失败了,它说Gradle Sync失败了。 因为它在jdk设置中抱怨java home,所以我试图像我的intellij所期望的那样更改路径。但是一旦我更改它,它就告诉我它找不到android sdk位置。我不知道它为什么关心
-
OpenGL 3.3在Ubuntu 14.04(LinuxMint 17.1)英特尔显卡LWJGL
我试图运行用LWJGL和GLSL 3.3构建的OpenGL软件,但在Linux Mint 17.1和Intel Ivy Bridge(HD4000)Mesa 10.6.0-devel下运行时遇到了问题。 据我所知,Mesa 10.1应该支持Sandry Bridge和更新的Intel CPU的OpenGL和GLSL 3.3。 glxinfo | grep OpenGL返回: (我猜我需要OpenG
-
Docker需要哪些英特尔虚拟化技术?
Docker需要哪些英特尔虚拟化技术? 在英特尔cpu上运行的Linux系统上,英特尔需要哪些虚拟化技术来完成Docker容器的执行?例如,有VT-X、… 或者没有必要使用这样的技术,因为Docker与现有的虚拟化解决方案(如VirtualBox)有所不同。在这种情况下,为什么没有必要?
-
英特尔未能向雄猫部署爆炸战争
我有一个Java web应用程序,我正在IntelliJ中开发,并使用Apache Tomcat进行部署。我定义了一些在团队中每个人之间共享的运行配置。这些运行配置定义为将分解的war工件部署到本地tomcat中。其他团队成员能够很好地部署和运行,但我遇到以下错误: IntelliJ似乎不想创建分解/项目。war目录。如果我手动创建这些目录,我不会收到该错误消息,但WAR内容都不会放入该目录。 我
-
英特尔的RDRAND是否有任何合法用途?
今天我想:好吧,即使人们对NIST SP 800-90A的RDRAND实现有很大的怀疑,它仍然是伪随机数生成器(PRNG)的硬件实现,对于非敏感应用程序来说必须足够好。所以我想在我的比赛中使用它,而不是Mersenne Twister。 因此,为了查看使用该指令是否有任何性能提升,我比较了以下两个代码的时间: 和 通过运行这两个,我得到: 所以,Mersenne Twister在我的CPU上比RD
-
如何禁用英特尔至强phi协处理器?
我有一个带有四个麦克风卡(mic0-mic3)的服务器,它工作得很好。我想禁用一些麦克风,例如mic3,现在只有mic0-mic2可用。我该怎么办?
-
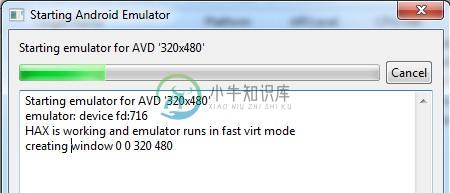 英特尔x86模拟器启动但Android不启动
英特尔x86模拟器启动但Android不启动我想使用Intel HAX技术在模拟器api级别10上运行我的应用程序。我已经从sdk管理器下载了HAXM包并安装了它。我还在BIOS设置中启用了“虚拟化技术”(阅读此线程),但启动时模拟器屏幕保持黑色,android不会启动/启动。这是关于启动模拟器的Avd消息: 请帮帮我,我不知道怎么了! (我的电脑配置:Windows 7-64位,4gig内存,英特尔M 520 2.4 GHz,在eclip
-
为什么NaN-NaN==0.0与英特尔C编译器?
众所周知,NaN在算术中传播,但我找不到任何演示,所以我写了一个小测试: 这个例子(在这里实时运行)基本上产生了我所期望的(消极有点奇怪,但它有点道理): 2015年MSVC奥运会产生了类似的东西。然而,英特尔C 15生产: 具体来说,。 这...不可能是对的,对吧?相关标准(ISO C,ISO C,IEEE 754)对此有什么说法,为什么编译器之间的行为会有差异?