《中邮消费金融有限公司》专题
-
Kafka消费者-优先级更高的主题
我正在使用Kafka Consumer阅读多个主题,我需要其中一个具有更高优先级。处理需要很多时间,而且(低优先级)主题中总是有很多消息,但我需要尽快处理来自另一个主题的消息。 这和Kafka是否支持主题或消息的优先级类似?但这一个使用的是旧的API。 在新的API(0.10.1.1)中,有一些方法 但我不清楚,如何有效地检测高优先级主题中有新消息,有必要暂停其他主题的消费。 有什么想法/例子吗?
-
使用@KafkaListener勇敢地追踪Kafka消费者
我正在使用Brave库https://github.com/openzipkin/brave进行跟踪,现在我也想将其用于Kafka消费者。我想避免添加Spring Sleuth,并利用Brave Kafka仪器https://github.com/openzipkin/brave/tree/master/instrumentation/kafka-clients. 对于Kafka消费者,我使用@K
-
 华为消费者bg 交互设计二面
华为消费者bg 交互设计二面1.讲完第一个项目,一问就很懵(是思考问题的角度不同) 他问了下数据这块可能要改,你怎么改,他想要知道的是数据的落地页,比如用可视化的语言表达,我在强调用数据强调设计,然后形式上怎么改,不是突出某一块内容 2.另一个tab栏太像手机了,怎么考虑的(不在于方案,在于他想要的点,就像功能集合,里面也有的,这个是常用功能的集合 3.讲第二个项目 4.讲第三个校园项目,好像对校园项目更感兴
-
迭代器 - 迭代器、适配器、消费者
从for循环讲起 我们在控制语句里学习了Rust的for循环表达式,我们知道,Rust的for循环实际上和C语言的循环语句是不同的。这是为什么呢?因为,for循环不过是Rust编译器提供的语法糖! 首先,我们知道Rust有一个for循环能够依次对迭代器的任意元素进行访问,即: for i in 1..10 { println!("{}", i); } 这里我们知道, (1..10) 其本身
-
消费者负载均衡服务RebalanceService入口
主要内容:1 负载均衡or重平衡的触发,1.1 RebalanceService自动重平衡,1.2 Consumer启动重平衡,1.3 Broker请求重平衡,2 小结基于RocketMQ release-4.9.3,深入的介绍了消费者负载均衡服务RebalanceService入口源码。 RocketMQ一个消费者组中可以有多个消费者,在集群模式下他们共同消费topic下的所有消息,RocketMQ规定一个消息队列仅能被一个消费者消费,但一个消费者可以同时消费多个消息队列。这就涉及到如何将多个
-
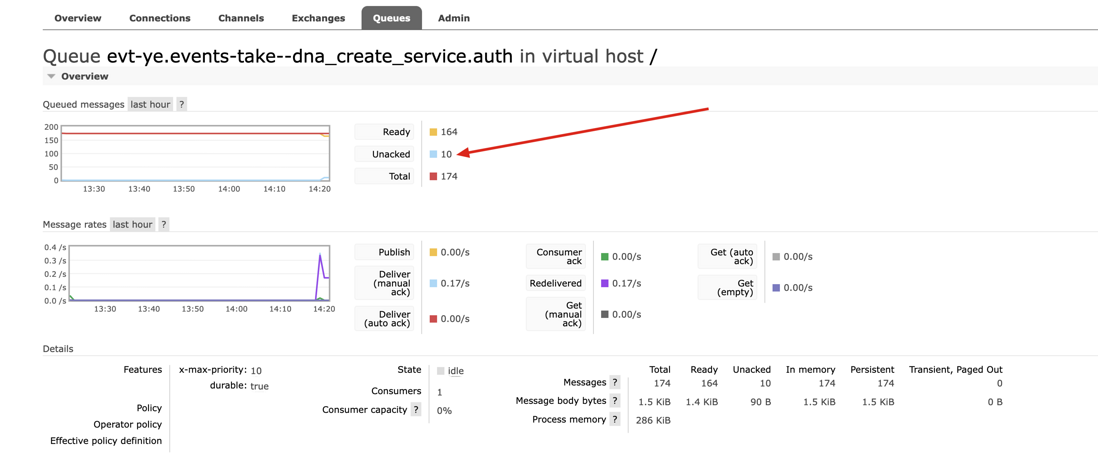 python - 为什么 kombu 的 ConsumerMixin 消费阻塞了?
python - 为什么 kombu 的 ConsumerMixin 消费阻塞了?上面的代码运行后输出 然后就没有然后了,程序没有退出,一直阻塞着 从 rabbitmq 的监控面板看,也一直出于阻塞状态 用 wireshark 抓包看,也没有回复 ack 为什么 ?
-
Discord JDA Bot无限发送消息
我试图使用Discord JDA API发送消息,但是每当我发送一条消息时,它就会无限地发送。 JDA版本:4.2.1_255 我尝试过什么: 使用GuildMessageReceivedEvent而不是MessageReceivedEvent来研究此问题 伪代码: SendPrivate ateMessage():
-
 中金所前端
中金所前端选择题10道还是15道来着,408和前端都有涉及到。算法题前端只有两道,第一题是输入两个数字字符串,不可以用bigint,求他们的乘积,输出也要是一个字符串。第二题是自然数按1 23 456 78910这样的规律排成一个三角形,然后输入一个字符串,里面有三个数字,要你判断这三个数是否在这个三角形里能组成一个等边三角形(比如3,5,6),输出true false。
-
 中金所数据
中金所数据时间:6.20 时长:10min左右 1. 自我介绍 2. 项目中遇到的困难?如何解决?原创还是开源? 3. 八股:栈的大小;虚拟内存空间;new和malloc的区别;malloc相关的一个问题(忘记是什么了,没回答上);左值引用和右值引用;按层遍历二叉树(队列);top K的问题;TCP如何保证传输可靠;STL容器相关问题 4. 为什么投递这个岗位?对中金所的了解?和专业不匹配怎么看?在上海工作
-
LocalDate()在LocalDatejava.time.中具有私有访问权限
我试图理解Java8中引入的新日期和时间API。 我在日志文件中有一个unix时间戳,我需要对它进行处理,以确定它属于今天或昨天的哪个小时。 我遇到了一个不寻常的错误在Android Studio,想更好地理解它。
-
 Kafka消费者无法在偏移提交后读取所有消息(错误=偏移超出范围
Kafka消费者无法在偏移提交后读取所有消息(错误=偏移超出范围我创建了以批处理方式接收消息的ConsumerConfig: Spring启动配置: 侦听器类 : 我在处理消息后使用手动确认。 我找到了一些调试日志: 在上面的调试日志中,***获取偏移量发生在偏移量提交之前,该偏移量未提交,因此它返回offset_OUT_OF_RANGE,之后使用者无法接收任何消息。是否有任何方法处理使用者代码中的此错误,或如何仅在提交后获取偏移量****
-
Kafka消费者的第一次民意调查没有检索主题消息。会出什么问题?
我有一个简单的Kafka 2.4.1(Confluent 5.4.1)安装程序在本地Docker中运行。并且我使用了用Java编写的测试生产者和测试使用者。该代码可在GitHub中获得。 单元测试做: 生成器向单个分区主题生成一条消息 用户订阅该主题并在Kafka中查询可用消息 问题是:使用者的第一次运行将跳过主题中已经生成的可用消息。真正的问题是,那些错过的消息会丢失(从使用者的角度来看:偏移量
-
如何让Kafka的消费者从最后消费的偏移量开始阅读而不是从头开始
我是 kafka 的新手,并试图了解是否有办法从上次使用的偏移量读取消息,但不是从头开始。 我正在写一个例子,这样我的意图就不会偏离。 有没有一种方法可以获取从上次使用的偏移量生成的消息。?
-
Kafka-如何检查消费者是否活着,如果不是如何将消费者带回运行状态?
我目前正在做一个kafka java项目。我是新来的,我发现很难理解与Kafka生产者/消费者设计相关的几个基本概念。 > 比方说,我有一个带有单个分区的主题,我有一个生产者正在写这个主题,一个消费者正在从这个主题中消费。如果我部署同一个应用程序的多个实例,每个实例将运行自己的消费者。在这种情况下,因为所有消费者都属于同一个group pId,所以消息是否会在多个实例上运行的消费者之间平均分配?
-
库伯内特斯kafka-lagom-消费者在超时后被Wakeup异常中断。消息:null
使用Lagom 1.4.11,kafka 0.11与kafka的沟通似乎有效,因为制片人已经制作了一些东西。只有使用者有错误。 看起来我的µService与kafka没有任何联系。我有一个kafka-0 pod,kafka-zooker-0。 我安装了它 是他们能帮忙的人。谢谢你。 添加。 我发现制作人创造了主题: 似乎kafka不存储消息。