《中邮消费金融有限公司》专题
-
骆驼中程jpa消费者
我在JPA上遇到了以下问题,但这可能更像是一个关于骆驼的概念问题。 我需要一个基于cron的石英消费者。但如果触发了,我想选择JPA组件作为第一步。 但是如果我用“to”调用JPA组件,那么它被用作生产者,而不是消费者。我可以以某种方式使用JPA组件来处理这个问题吗,或者我必须遵循服务激活器(基于bean的)逻辑并将JPA组件留在后面? 提前谢谢你,葛格利
-
JMS-从一个消费者到多个消费者
问题内容: 我有一个JMS客户端,它正在生成消息并通过JMS队列发送到其唯一的使用者。 我想要的是不止一个消费者收到这些消息。我想到的第一件事是将队列转换为主题,以便现有用户和新用户都可以订阅并将相同的消息传递给他们。 显然,这将涉及在生产者和消费者方面修改当前的客户代码。 我还要查看其他选项,例如创建第二个队列,这样就不必修改现有的使用者。我相信这种方法有很多优点,例如(如果我错了,请纠正我)在
-
Kafka控制台消费者未从主题消费
我们有一个服务器,负责处理消息的生成和消费。我们有4台笔记本电脑,所有带有confluent的Mac都运行相同的命令行。。。 /kafka avro控制台使用者--从一开始--引导服务器0.0.0.0:9092,0.0.0.0:9092--主题主题名称--属性schema.registry.url=http://0.0.0.0:8081 4台笔记本电脑中有3台没有问题使用这些消息,但是第四台不会。
-
在Kafka中,当分区多于消费者时,消息是如何被消费的?
这是一个关于Kafka和信息如何被消费的非常基本的问题,但不幸的是,我在这一点上找不到任何答案。 假设我想过度分区,那么我将得到比消费者多10倍的分区。过度分区是必需的,因为我希望能够扩展(在未来并行处理更多的消息)。 1 个主题分为 1000 个分区,由 100 个使用者使用 =- 我的问题是: > 消息是如何为每个消费者消费的:它是以循环方式完成的吗?如果不是,分发是如何完成的? 有没有保证消
-
Kafka 0.10Java消费者没有从主题阅读消息
我有一个简单的java制作人,如下所示 我正在尝试读取如下数据 但消费者并没有从Kafka那里读到任何信息。如果我在处添加以下内容 然后消费者开始从题目开始阅读。但是每次消费者重新启动时,它都从我不想要的主题开始读取消息。如果我在启动消费程序时添加了以下配置 然后,它从主题中读取消息,但是如果消费者在处理所有消息之前重新启动,那么它不会读取未处理的消息。 有人可以让我知道出了什么问题,我该如何解决
-
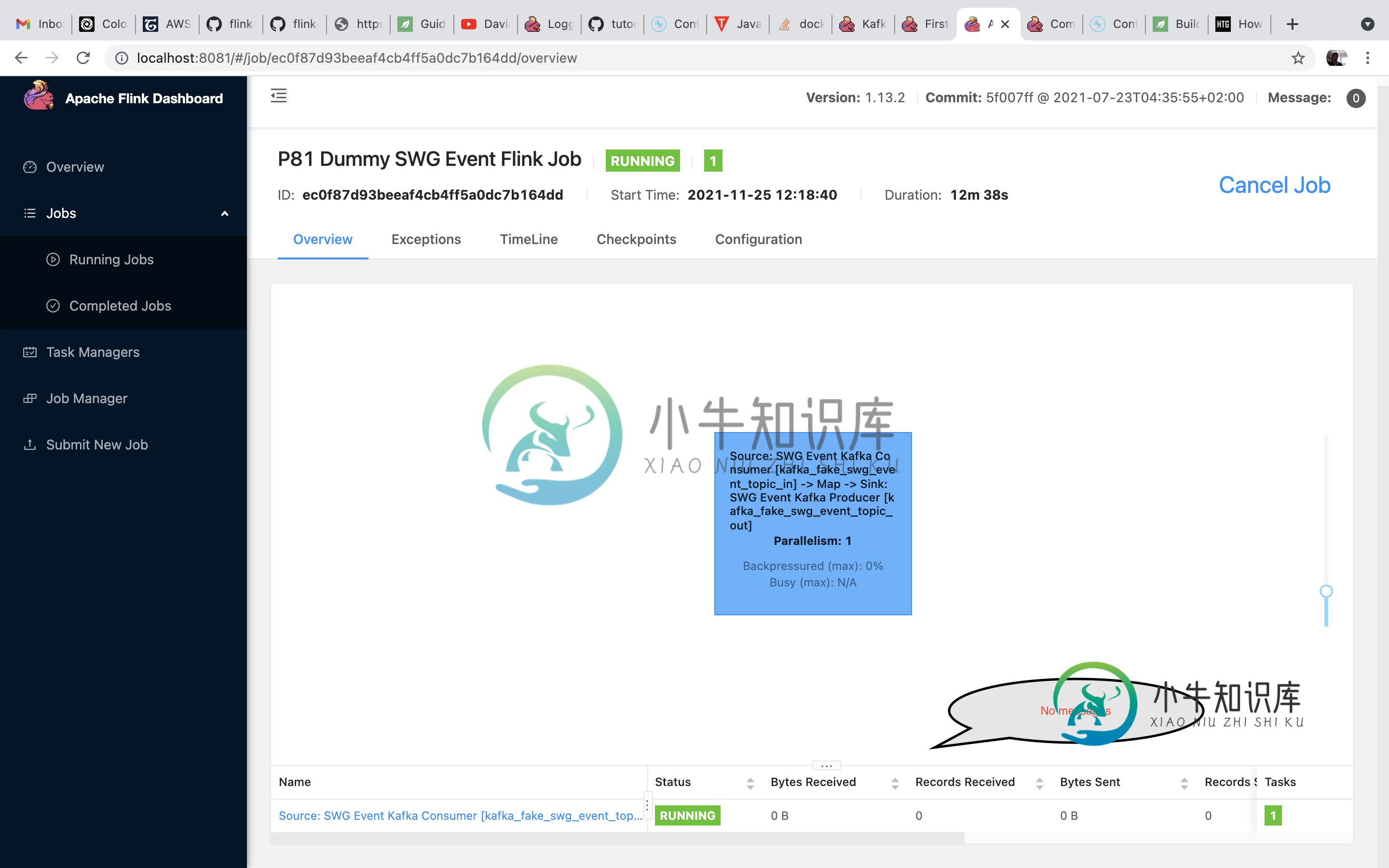 Flink.Kafka消费者没有收到来自Kafka的消息
Flink.Kafka消费者没有收到来自Kafka的消息我在mac上运行Kafka和Flink作为docker容器。 我已经实现了Flink作业,它应该消耗来自Kafka主题的消息。我运行一个向主题发送消息的python生产者。 工作开始时没有问题,但没有收到任何消息。我相信这些消息被发送到了正确的主题,因为我有一个能够使用消息的python消费者。 flink作业(java): Flink作业日志: 生产者作业(python):(在主机上运行-不是d
-
消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果不正确,那么有没有什么hack的手段?*
本文向大家介绍消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果不正确,那么有没有什么hack的手段?*相关面试题,主要包含被问及消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?如果不正确,那么有没有什么hack的手段?*时的应答技巧和注意事项,需要的朋友参考一下 不正确,通过自定义分区分配策略,可以将一个c
-
Kafka消费绩效
我的Kafka集群有下一个配置。 Kafka版本集群(V1.1.0)3个代理 一个主题(“FARA”),包含5个分区和3个副本 每个分区中有10000000条消息。总共50.000.0000 我使用的是Kafka-Consumer-Perf,测试用的是下面使用ConsumerPerformance的decro。 null 我定期运行下面的命令 ./kafka-run-class.sh kafka.
-
Quarkus SQS消费者
我正在查看关于使用Quarkus从SQS消费的指南。 问题是我想在无休止的循环中执行它,例如每10秒获取一次新消息,并使用Hibernate Reactive从消息中插入一些数据到数据库中。 我创建了一个Quarkus调度程序,但由于它不支持返回Uni,我不得不阻止Hibernate Responsive的响应,因此出现了这个错误 使用Quarkus和reactive实现我所需的最佳方法是什么?
-
Kafka消费群体
我是Kafka的新手,正在学习Kafka内部知识。请根据需要随时更正我的理解。。 这是我的实时场景..感谢所有的回复: 我有一个接收数据文件的实时FTP服务器…比如索赔文件。 我将把这些数据发布到一个主题中.让我们把这个主题称为claims_topic(2个分区). 我需要订阅这个claims_topic,阅读消息并将它们写入Oracle和Postgres表。让我们将oracle表称为Otable
-
用Java消费restapi
我有一个管理Web应用程序位于远程服务器上。这个应用程序是使用MEAN堆栈编写的,我有一个连接到网络应用程序所需的所有RESTful路由的列表。 我正在编写一个Java客户端应用程序,它需要从这个管理应用程序发送和接收数据。如果我有服务器的IP地址和REST路由,如何将客户端连接到web应用程序? 我想我需要提供一个到服务器和RESTAPI文件的URL连接,然后只需调用路由函数,如和。
-
1.5.1 消费者端
将Pact用于消费者与提供者的契约测试,而不是对提供者的功能测试 功能测试是确保提供者在某个请求下执行正确的动作。这些测试代码属于提供者团队,不应该由消费者团队完成。 而契约测试的目的是确保消费者团队和提供者团队对请求和响应达成共识。 Pact测试应该关注于: 检查消费者如何构建请求以及处理响应时所暴露出的bug 检查提供者的行为,消除理解上的偏差 Pact测试不应该关注于: 提供者内部所暴露的b
-
 站酷网科技有限公司1面4.12
站酷网科技有限公司1面4.12上来自我介绍 1.选一个自己的项目展开介绍下。 2.webpack打包优化。 3.类组件和hook区别。 4.hook实现生命周期。 5用过哪些hook,说下usememo的优点 6.usestate闭包问题。 7.canvas压缩图片上传。 8.动画相关,transition和animation区别 9.移动端适配的方案,vw,rem,的媒体查询的一些用法 10.ts相关,问了下命名空间,和泛型
-
 楚兴技术有限公司 面经薪资
楚兴技术有限公司 面经薪资1、面试状态:已拿offer 2、面试地点:线下,武汉华美达线下面 3、面试过程: 面试岗位:机器学习算法工程师 面试流程:先技术面,当场出结果,如果通过继续综合面,然后回去等消息 面试心态:没有怎么认真准备,随缘来面的 1)技术面:问了梯度下降、随机梯度下降、MDP、指针、数组、深度学习的相关知识,优化考的比较多 2)综合面:C中的全局变量和局部变量的使用方法,然后问了一些C。之后就是基本的,为
-
 深圳众创空间信息有限公司
深圳众创空间信息有限公司#面经# 1.讲一讲什么是nio? 2.Redis如何进行内存优化? 3.SpringCloud有哪些组件? 4.Rabbitmq的5种消息模型 5.Java有哪些线程安全的类 6.Rabbit如何在Springboot项目中进行使用? 7.Redis的缓存策略有哪些?