《中邮消费金融有限公司》专题
-
GitHub错误消息-权限被拒绝(公钥)
我正在使用终端,我在根,GitHub存储库存在,我不知道现在该做什么。
-
 金山办公一面
金山办公一面服务端开发工程师 40min 自我介绍 golang用了多久 对Map并发读写会有问题吗 怎么安全并发读写Map(sync.Map,锁) go的锁使用怎么写,信号量有什么了解 channel有了解过吗 链表成环怎么判断 怎么找第k大个数,时间复杂段是多少,通过树结构可以处理吗 Slice的底层实现,扩容机制 HTTP和HTTPS的区别 TLS/SSL在哪一层协议 应用层有什么协议 ICMP是做什么
-
 金山办公 一面
金山办公 一面C++,不用开摄像头 1、自我介绍 2、拷打项目 3、dynamic_cast与static_cast 4、虚函数和普通成员函数的性能开销 5、引用和指针,引用作为函数参数占内存吗 6、迭代器失效 7、结构体、类区别 8、lambda捕获指针,指针可能失效,如何解决 9、什么情况用智能指针,用哪种智能指针 10、c++11之前,如何禁用类的某些函数 11、map和unordered_map 12、
-
 金山办公hr面
金山办公hr面1.怎么接触前端的,如何学习的 2.研究生三年做了什么,时间线 3.对wps的了解 4.代码风格,代码规范相关 5.和同事如何协作的,如何获取用户的需求 6.通过什么渠道了解最新的前端前沿知识 7.实习项目面向哪些用户,你认为toB和toC有什么区别 8.有哪些offer 9.实习为你带来了什么 10.为什么两段实习没有留用 11.反问 当场oc,说两天左右审批,许愿来个offer!
-
Apache Kafka消费者组和简单消费者
我是Kafka的新手,我对消费者的理解是,基本上有两种类型的实现 1)高级消费者/消费者群体 2)简单消费者 高级抽象最重要的部分是当Kafka不关心处理偏移量,而Simple消费者对偏移量管理提供了更好的控制时使用它。让我困惑的是,如果我想在多线程环境中运行consumer,并且还想控制偏移量,该怎么办。如果我使用消费者组,这是否意味着我必须读取存储在zookeeper中的最后一个偏移量?这是我
-
Kafka消费者从一开始就不消费
我在本地机器上安装了Kafka,并启动了zookeeper和一个代理服务器。 现在我有一个单独的主题,描述如下: 我有一个生产者在消费者启动之前产生了一些消息,如下所示: 当我使用--从头开始选项启动消费者时,它不会显示生产者生成的所有消息: 但是,它显示的是新添加的消息。 我在这里怎么了?有什么帮助吗?
-
多消费者从单一Kafka分区消费
null 我在这一页上读到以下内容: 使用者从任何单个分区读取,允许您以与消息生成类似的方式扩展消息消耗的吞吐量。 也可以将使用者组织为给定主题的使用者组-组内的每个使用者从唯一分区读取,并且组作为一个整体使用来自整个主题的所有消息。 如果使用者多于分区,则某些使用者将空闲,因为它们没有可从中读取的分区。 如果分区多于使用者,则使用者将从多个分区接收消息。 如果使用者和分区的数量相等,则每个使用者
-
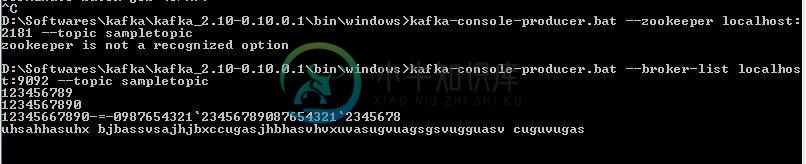 kafka:消费者不消费来自命令行的消息
kafka:消费者不消费来自命令行的消息D: \软件\Kafka\Kafka2.10-0.10.0.1\bin\windows 我使用上面的命令来消费消息,有什么我错过的吗?帮助我: 这个 那些是生产者和消费者......
-
暂停和恢复后,Kafka消费者未消费消息
我正在使用这个库来实现节点kafka与消费者暂停和恢复方法来处理背压。我已经创建了一个小演示,我可以在其中和,但问题是在后它停止了消费消息。 这是我的代码。 任何人都可以帮助我,我在恢复消费者时做错了什么?当我启动使用者时,它只接收一条消息,并且在恢复后仍然不消耗任何其他消息。
-
Spring Kafka消费者有时停止接收消息
我想这个话题发生了什么...偏移坏了还是我不知道... 有人知道会发生什么吗?谢谢
-
ConsumeMessageOrderlyService顺序消费消息
主要内容:1 start启动服务定时锁定消息队列,1.2 lockAll锁定所有消息队列,2 submitConsumeRequest提交消费请求,3 ConsumeRequest执行消费任务,3.1 tryLockLaterAndReconsume尝试延迟加锁并重新消费,3.2 takeMessages拉取消息,4 processConsumeResult处理消费结果,4.1 commit提交消息,4.2 checkReconsumeTimes检查重试次数,,,基于RocketMQ relea
-
ConsumeMessageConcurrentlyService并发消费消息
主要内容:1 start启动服务定时清理过期消息,1.1 cleanExpireMsg清理过期消息,1.2cleanExpiredMsg清理过期消息,2 submitConsumeRequest提交消费请求,2.2 submitConsumeRequestLater延迟提交,2.2 consumeMessageBatchMaxSize和pullBatchSize,3 ConsumeRequest执行消费任务,,,,基于RocketMQ release-4.9.3,深入的介绍了ConsumeMes
-
基于 Seata Saga 设计更有弹性的金融应用
Seata 意为:Simple Extensible Autonomous Transaction Architecture,是一套一站式分布式事务解决方案,提供了 AT、TCC、Saga 和 XA 事务模式,本文详解其中的 Saga 模式。 项目地址:https://github.com/seata/seata 金融分布式应用开发的痛点 分布式系统有一个比较明显的问题就是,一个业务流程需要组合一
-
为什么在kafka python中,消费者最后提交的消息在消费者重启后再次被消费?
我将python kafka consumer的< code>auto_commit设置为< code>False,我正在手动提交消息。然而,重启后,消费者再次消费来自每个分区的最后一条消息。只有最后一个,不能再多。 这就是所展示的: 不知道为什么会显示滞后,whu当前偏移设置为最后一条消息而不是下一条?当我提交偏移量3时,当前偏移量不应该移动到4吗? 我提交我使用的每条消息,但是在重启时,它总是
-
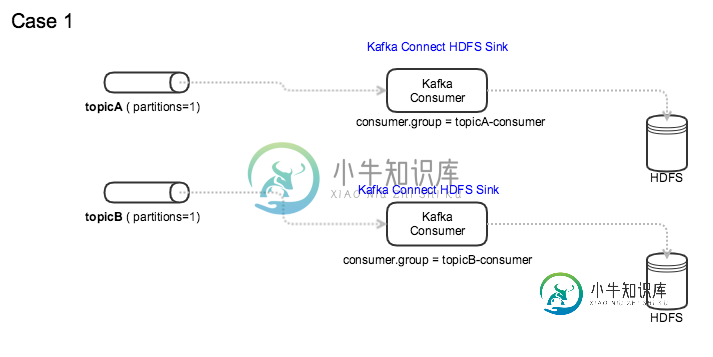 Kafka:使用公共消费者组访问多个主题
Kafka:使用公共消费者组访问多个主题我们的集群运行Kafka0.11并且对使用消费者组有严格的限制,我们不能使用任意的消费者组,所以Admin必须创建所需的消费者组。 我们运行Kafka连接HDFS接收器,从主题读取数据并写入HDFS。所有主题只有一个分区。 在Kafka HDFS接收器中使用消费者组时,我可以考虑遵循两种模式。 我知道,当一个主题有多个分区时,如果一个使用者失败,同一使用者组中的另一个使用者将接管该分区。 我的问题