《中邮消费金融有限公司》专题
-
Tomcat中的Kafka消费者关闭
我们正在tomcat服务器中部署kafka消费者。消费者是使用Spring-Kafka2.1.7构建的。每个tc容器可以有多个属于同一个使用者组的使用者(使用ConcurrentKafkaListenerContainerFactory)。作为一般模式,在我的使用案例中,使用者以事务性的方式从一个主题读取并生产到另一个主题。tc服务器由通常的启动和关闭shell脚本启动和停止。如果要优雅地关闭co
-
在Kafka中生产和消费JSON
我们将在项目中部署Apache Kafka2.10,并通过JSON对象在生产者和消费者之间进行通信。 到目前为止,我想我需要: 实现自定义序列化程序以将JSON转换为字节数组 实现自定义反序列化器,将字节数组转换为JSON对象 生成消息 读取消费者类中的消息 然而,到目前为止,有问题的2-4分。我在自定义反序列化程序中尝试了这样的操作: 在我的消费者身上,我试着: 我以为这将生成一个正确的原始js
-
消费者/生产者AWS SQS akka scala与synchrone消费者
我的应用程序有一个生产者和一个消费者。我的生产者不定期地生成消息。有时我的队列会是空的,有时我会有一些消息。我想让我的消费者监听队列,当有消息在其中时,接受它并处理这条消息。这个过程可能需要几个小时,如果我的消费者没有完成处理当前消息,我不希望他接受队列中的另一条消息。 我认为AKKA和AWS SQS可以满足我的需求。通过阅读文档和示例,akka-camel似乎可以简化我的工作。 我在github
-
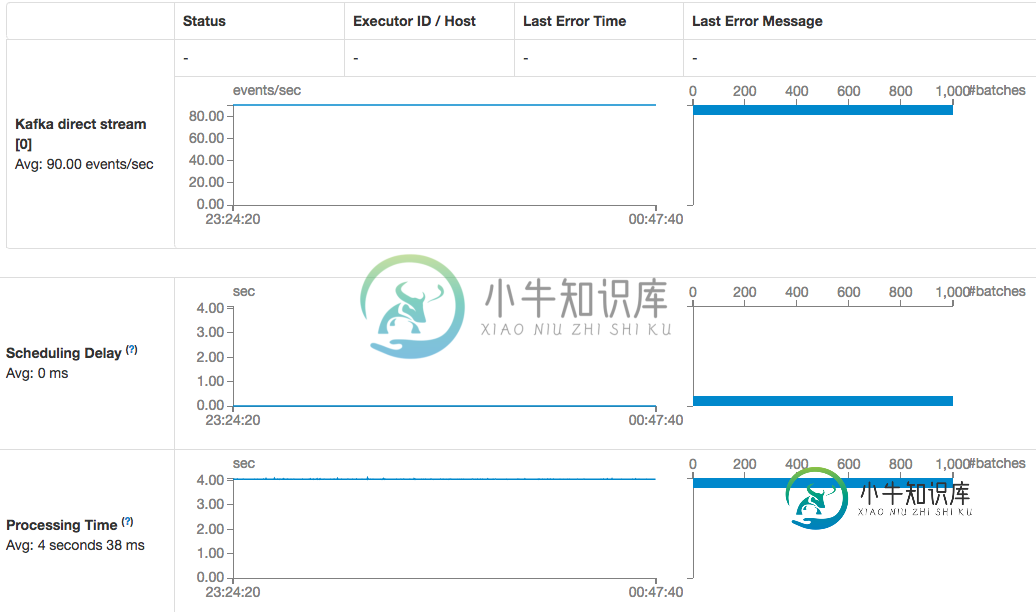 火花流Kafka直接消费者消费速度下降
火花流Kafka直接消费者消费速度下降我使用的是运行在AWS中的spark独立集群(spark and spark-streaming-kafka version 1.6.1),并对检查点目录使用S3桶,每个工作节点上没有调度延迟和足够的磁盘空间。 没有更改任何Kafka客户端初始化参数,非常肯定Kafka的结构没有更改: 也不明白为什么当直接使用者描述说时,我仍然需要在创建流上下文时使用检查点目录?
-
未调用Kafka侦听器方法。消费者不消费。
这是创建ListenerContainerFactory的类 这是我用@KafKalistener注释的Listener类 这是KafkaListenerConfig类,它接受引导服务器、主题名称等。
-
如何删除消费者已经消费的数据?Kafka
我在Kafka做数据复制。但是,kafka日志文件的大小增长很快。一天内大小达到5 gb。作为这个问题解决方案,我想立即删除处理过的数据。我正在使用AdminClient中的delete record方法删除偏移量。但当我查看日志文件时,对应于该偏移量的数据不会被删除。 我不想要类似(log.retention.hours,log.retention.bytes,log.segment.bytes
-
如何为Java中的消费者组获取消费者偏移(存储在kafka中)?
我有多个Kafka消费者和制作人,主题不同。使用独立应用程序,我想监控Kafka消费者的延迟。 我使用Kafka0.10.0.1,因为Kafka现在存储消费者偏移Kafka本身,所以我怎么能读到相同的。 我能够读取每个分区的主题偏移量。
-
在Java中获取Kafka未消费消息计数
-
Kafka消费者在Spring Boot中未收到消息
我的Spring/java消费者无法访问生产者生成的消息。但是,当我从控制台/终端运行消费者时,它能够接收Spring/java生产者生成的消息。 消费者配置: 监听器配置: Kafka听众: 消费者应用: 测试用例1:通过 我启动了我的Spring/ java生产者并从控制台运行消费者。当我生成消息表单创建者时,我的控制台使用者能够访问该消息。 测试用例2:失败:我启动了spring/java消
-
Kafka在消费消息时崩溃
Kafka过去在我自己的电脑上工作得很好。我正在另一台电脑上工作,上面写着 为目录C:\tmp\kafka logs(kafka.server.LogDirFailureChannel)java中的\uu consumer\u offset-41创建日志时出错。木卫一。IOException:映射在sun失败。尼奥。总经理。Kafka地图(FileChannelImpl.java:940)。日志抽
-
Kafka消费者不接收消息
我是Kafka的新手。我在网上读了很多关于Kafka制作人和Kafka消费者的说明。我成功地实现了前者,它可以向Kafka集群发送消息。然而,我没有完成后一个。请帮我解决这个问题。我看到我的问题像StackOverflow上的一些帖子,但我想更清楚地描述一下。我在虚拟盒子的Ubuntu服务器上运行Kafka和Zookeeper。使用1个Kafka集群和1个Zookeeper集群的最简单配置(几乎是
-
Spring kafka消息消费者延迟
我正在使用Spring Kafka1.0.3来消费kafka消息。Kafka的2个主题,每个主题有1个分区。在java代码中,有2@KafKalistener来消费每个主题消息。ConcurrentKafkaListenerContainerFactory的并发设置为1。但消息有时会延迟20秒以上。 有人知道为什么吗? 添加调试日志,并且延迟不是每次都可以,有时也可以:
-
camel-rabbitMQ:在单个camel消费者中从多个rabbitmq队列进行消费
我有以下场景:有3个rabbitmq队列,生产者根据消息的优先级将消息推送到这些队列。(myqueue_high,myqueue_medium,myqueue_low)我希望有一个可以按顺序或优先级从这些队列中提取的单一使用者,即只要消息在那里,它就一直从高队列中提取。它是从介质中拉出来的。如果medium也是空的,它从Low拉出。 我如何实现这一点?我需要编写自定义组件吗?
-
Spring靴2.1微米Kafka消费者公制统计数字为“nan”
目前我正在使用Spring Boot2.1、Spring Kafka(2.2.0)和Micrometer(1.1.0)。 null 生成和使用Hello World消息非常正常,(kafka)度量也公开了http://host:port/acture/metrics,但当我请求特定的kafka度量时,比如: http://host:port/actulator/metrics/kafka.cons
-
ActiveMQ消费者挂起
问题内容: 我有一个使用SSL传输的activeMQ代理。我大约有10位使用代理的消费者。我正在使用骆驼配置路线。 即使我重新启动使用者,它总是挂断并且不会使用新消息,即使队列中有待处理的消息也是如此。 我开始尝试一次遍历我的消费者,试图找出问题所在,以找出问题的根源。我终于找到了一个消费者,我可以重新解决这个问题。一段时间后它将挂起,但是,如果我进入活动的MQ管理控制台并尝试查看队列中的消息,它