《算法优化》专题
-
Spark FP Tree算法和PrefixSpan算法
在Spark MLlib中,也只实现了两种关联算法,即我们的FP Tree和PrefixSpan,而像Apriori,GSP之类的关联算法是没有的。而这些算法支持Python,Java,Scala和R的接口。由于前面的实践篇我们都是基于Python,本文的后面的介绍和使用也会使用MLlib的Python接口。 Spark MLlib关联算法基于Python的接口在pyspark.m
-
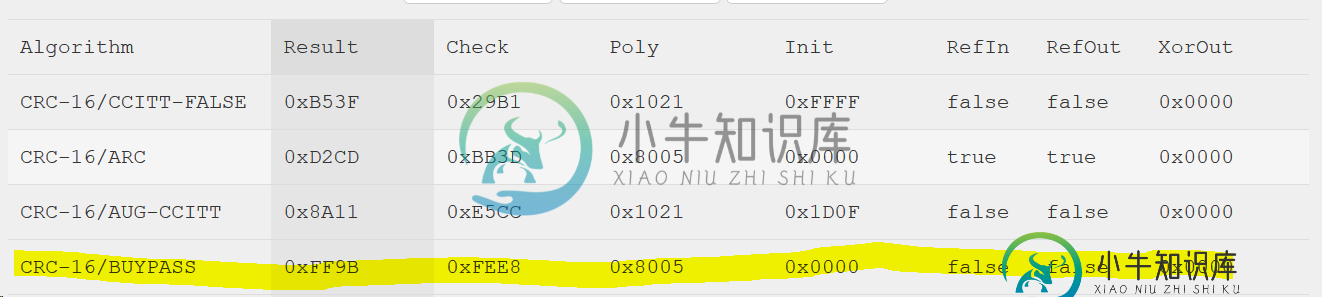 CRC16(ModBus)-计算算法
CRC16(ModBus)-计算算法我正在使用ModBus RTU,并试图找出如何计算CRC16。我不需要代码示例。我只是对机制很好奇。我已经了解到,基本的CRC是数据字的多项式除法,根据多项式的长度,用零填充。下面的测试示例应该检查我的基本理解是否正确: 数据字:01001011 多项式:1001(x3+1) 由于最高指数x3而被填充3位 计算:0100 1011 000/1001->余数:011 计算。 null 第二次尝试:由
-
用神经网络关联输入与输出,用遗传算法优化输入
我目前正在做激光切割的过程优化——在MATLAB中。我试图将工艺参数与切割质量联系起来,例如: 输入(工艺参数) 切割速度 激光功率 辅助气体压力 输出(质量参数) 切割深度 切割宽度 我首先训练一个神经网络模型,以便根据工艺参数预测切削质量。 这很好,现在我对表演不感兴趣。 接下来我想使用遗传算法优化(最大化)输入参数切割速度。这意味着我的适应度函数(目标函数)是1/切割速度。 我为我的适应度函
-
算法篇
本书的 GitHub 地址:https://github.com/todayqq/PHPerInterviewGuide 算法可以说是大厂的必考题,对于算法,一定要理解其中的精髓、原理。 冒泡排序 冒泡排序的原理:一组数据,比较相邻数据的大小,将值小数据在前面,值大的数据放在后面。 function bubble_sort($arr) { $count = count($arr);
-
KM算法?
本文向大家介绍KM算法?相关面试题,主要包含被问及KM算法?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 匈牙利算法:求最大匹配,那么我们希望每一个在左边的点都尽量找到右边的一个点和它匹配。我们依次枚举左边的点x的所有出边指向的点y,若y之前没有被匹配,那么(x,y)就是一对合法的匹配,我们将匹配数加一,否则我们试图给原来匹配y的x’重新找一个匹配,如果x’匹配成功,那么(x,y)就可以
-
diff 算法?
本文向大家介绍diff 算法?相关面试题,主要包含被问及diff 算法?时的应答技巧和注意事项,需要的朋友参考一下 把树形结构按照层级分解,只比较同级元素。 给列表结构的每个单元添加唯_的key属性,方便比较。 React只会匹配相同class的component (这里面的class指的是组件的名字) 合并操作,调用component的setState方法的时候,React将其标记为dirty.
-
viterbi算法
本文向大家介绍viterbi算法相关面试题,主要包含被问及viterbi算法时的应答技巧和注意事项,需要的朋友参考一下 动态规划算法,用于寻找最有可能产生观测事件序列的-维特比路径-隐含状态序列,特别是在马尔可夫信息源上下文和隐马尔可夫模型中。声音信号作为观察到的事件序列,而文本字符串,被看作是隐含的产生声音信号的原因,因此可对声音信号应用维特比算法寻找最有可能的文本字符串。
-
Redlock 算法?
本文向大家介绍Redlock 算法?相关面试题,主要包含被问及Redlock 算法?时的应答技巧和注意事项,需要的朋友参考一下 算法很易懂,起 5 个 master 节点,分布在不同的机房尽量保证可用性。为了获得锁,client 会进行如下操作: 得到当前的时间,微秒单位 尝试顺序地在 5 个实例上申请锁,当然需要使用相同的 key 和 random value,这里一个 client 需要合理设
-
nth_element算法
我最近发现STL中有一个名为nth_element的方法。引用描述: Nth_element与partial_sort类似,因为它对元素区域进行部分排序:它对区域[first,last]进行排列,使得迭代器nth所指向的元素与如果整个区域[first,last]都已排序后将处于该位置的元素相同。此外,区域[nth,last]中的任何元素都不小于区域[first,nth)中的任何元素。 它声称平均具
-
2.2 算法
任何计算问题都可以通过按特定顺序执行一系列操作而完成。解决问题的过程(procedure)称为算法(algorithm),包括: 执行的操作(action) 执行操作的顺序(order) 下例演示正确指定执行操作的顺序是多么重要: 考虑每个人早晨起床到上班的“朝阳算法”:(1)起床,(2)脱睡衣,(3)洗澡,(4)穿衣,(5)吃早饭,(6)搭车上班。 总裁可以按这个顺序,从容不迫地来到办公室。假设
-
A3C算法
A3C的算法实际上就是将Actor-Critic放在了多个线程中进行同步训练. 可以想象成几个人同时在玩一样的游戏, 而他们玩游戏的经验都会同步上传到一个中央大脑. 然后他们又从中央大脑中获取最新的玩游戏方法. **这样, 对于这几个人, 他们的好处是:**中央大脑汇集了所有人的经验, 是最会玩游戏的一个, 他们能时不时获取到中央大脑的必杀招, 用在自己的场景中. **对于中央大脑的好处是:**中
-
bandit算法
假设每个臂是否产生收益,其背后有一个概率分布,产生收益的概率为p 我们不断地试验,去估计出一个置信度较高的*概率p的概率分布*就能近似解决这个问题了。 怎么能估计概率p的概率分布呢? 答案是假设概率p的概率分布符合beta(wins, lose)分布,它有两个参数: wins, lose。 每个臂都维护一个beta分布的参数。每次试验后,选中一个臂,摇一下,有收益则该臂的wins增加1,否则该臂的
-
图算法
GraphX包括一组图算法来简化分析任务。这些算法包含在org.apache.spark.graphx.lib包中,可以被直接访问。 PageRank算法 PageRank度量一个图中每个顶点的重要程度,假定从u到v的一条边代表v的重要性标签。例如,一个Twitter用户被许多其它人粉,该用户排名很高。GraphX带有静态和动态PageRank的实现方法 ,这些方法在PageRank object
-
1.1.3 算法
1.1.3 算法 如前所述,程序是解决某个问题的指令序列。编程解决一个问题时,首先要找出解决问 题的方法,该解决方法一般先以非形式化的方式表述为由一系列可行的步骤组成的过程,然 后才用形式化的编程语言去实现该过程。这种解决特定问题的、由一系列明确而可行的步骤 组成的过程,称为算法(algorithm①)。算法表达了解决问题的核心步骤,反映的是程序的解 题逻辑。 算法其实并不是随着计算机的发明才出现
-
Adam算法
Adam算法在RMSProp算法基础上对小批量随机梯度也做了指数加权移动平均 [1]。下面我们来介绍这个算法。 算法 Adam算法使用了动量变量$\boldsymbol{v}_t$和RMSProp算法中小批量随机梯度按元素平方的指数加权移动平均变量$\boldsymbol{s}_t$,并在时间步0将它们中每个元素初始化为0。给定超参数$0 \leq \beta_1 < 1$(算法作者建议设为0.9