《算法优化》专题
-
优化排序依据
我正在尝试优化这个查询,该查询通过字段(第1个)和字段(第2个)对进行排序。没有第一个字段查询需要大约0.250秒,但有了它需要大约2.500秒(意味着慢了10倍,可怕)。有什么建议吗? 注意: -使用InnoDB(MySQL 5.7.19) -主要是表上的 -字段同时被索引和 解释结果: 更新^^ 信誉规定:一个帖子,多少(n=信誉)天可以显示在列表的顶部。 实际上,我试图给一些帖子的声誉,可以
-
OrientDB优化数据库
根据技术术语,优化表示“在最快的时间内实现更好的性能”。 参照数据库,优化涉及最大化检索数据的速度和效率。 OrientDB支持轻量级边缘,这意味着数据实体之间的直接关系。 简而言之,它是一个字段到字段的关系。 OrientDB提供了不同的方法来优化数据库。 它支持将常规边转换为轻量级边缘。 以下语句是数据库命令的基本语法。 将常规边转换为轻量级边,而禁用输出。 示例 在这个例子中,我们将使用在前
-
最后资源优化
问题内容: 我正在写一个不支持两阶段提交的资源适配器。我知道有一种称为“最后的资源优化”的优化技术。 在JBoss上,您的XAResource类应实现LastResource以便进行优化。 我的问题是:如何在WebLogic,WebSpehre,Glassfish等中完成此操作… 问题答案: Weblogic: AFAIK (可能是非常错误的),只有JDBC驱动程序可以与LRO一起使用,这 纯粹是
-
java - JAVA代码优化?
有没有代码写的漂亮的大佬,看看这个代码怎么优化,一直写前端的,突然被叫去搞java,发现很多技术都不太相同,例如动态的key去调用之类,导致写出这样的恶心代码,自己都看不下去了 明明js可以写的这么短小优雅,java有没有办法做到这样子的呢
-
Web 移动端优化
Click 的 300ms 延迟响应 click 的 300ms 延迟是由双击缩放(double tap to zoom)所导致的,由于用户可以进行双击缩放或者双击滚动的操作,当用户一次点击屏幕之后,浏览器并不能立刻判断用户是确实要打开这个链接,还是想要进行双击操作。因此,移动端浏览器就等待 300 毫秒,以判断用户是否再次点击了屏幕。 随着响应式网页逐渐增多,用户使用双击缩放机会减少,这 300
-
16-JavaScript-性能优化
页面性能 浏览器缓存 缓存分类 强缓存:直接拿来用的缓存 Expires Expires:Thu, 21 Jan 2018 23:39:02 GMT (表示绝对时间,时间来自服务器,但是做比较的时候以本地浏览器的时间作为比较) Cache-Control Cache-Control:max-age = 3600(客户端相对时间)它的判断优先级高 协商缓存:本地有副本,但无法确实是否可以使用,需要询
-
如何优化画圆?
我想知道如何优化我的画圆方法。在将顶点发送到opengl之前,我寻求如何尽快生成顶点。 FillRect函数只绘制一个四边形,因此DrawCircle函数绘制100个四边形,这些四边形按cos、sin和半径移动。 我怎么能以不同的方式画圆呢?
-
Oracle中的SQL优化
问题内容: 我们使用的是Oracle 11,最近我购买了Dell SQL Optimizer(Xpert Toad软件包随附)。今天早上,我们有一条声明要花比正常运行更长的时间,而在最终使它运行(创建时缺少某些条件)之后,我很好奇,以前从未使用过任何SQL优化器,它将更改为。它返回了同一条语句的150多种变体,但成本最低的语句仅添加到了以下行中。 我们已经有o.curdate> 0,并添加了“ +
-
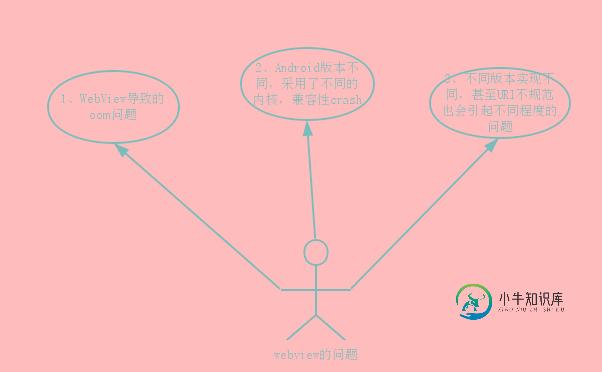 Android WebView 优化之路
Android WebView 优化之路本文向大家介绍Android WebView 优化之路,包括了Android WebView 优化之路的使用技巧和注意事项,需要的朋友参考一下 随着app的迭代,嵌入的html5界面越来越多了,Webview这个强大组件引起的问题越发的多起来,例如: 1、WebView导致的oom问题 2、Android版本不同,采用了不同的内核,兼容性crash 3、不同版本实现不同,甚至URI不规范也会引起不
-
谷歌脚本优化
我有一张保存ID的表。现在,我偶尔需要读取这些ID,并检查表中的其他值(名称)是否仍然符合ID。我的代码是: 从我所读到的,我知道单独调用每个单元格值需要更多的时间。然而,我不知道如何应用getValue来修复这些情况。基本上相同的问题在不同的衣服我有以下代码: 那么我如何使用get值来检查我得到的每个ID呢。我想我得用一些 或者 但我不知道如何实施,有什么想法吗? 有没有其他更有效的方法
-
VTD-XML解析优化?
我必须对VTD-XML库进行性能测试,以便不仅进行简单的解析,而且在解析中进行额外的转换。所以我有30MB的输入XML,然后用自定义逻辑将其转换为其他XML。因此,我想消除所有的想法,这减缓了整个过程,从我这边来(因为没有很好地使用VTD库)。我试图搜索优化提示,但找不到。我认为: '0'. 选择selectXPath或selectElement最好使用什么? > 使用不带名称空间的解析要快得多。
-
JSR223采样器优化
我有下面的JSR223采样器,它读取图像,稍微修改它,并发送一个POST multipart/form-data请求。与HTTP采样器相比,我发现它广泛使用了CPU,但我不能使用HTTP采样器,因为它不支持在不保存到文件系统的情况下更改映像。 如果任何人有任何输入来优化JSR223采样器中的脚本,这样它就不会占用大量的CPU,我将很感激。
-
Kafka流拓扑优化
在准备拓扑优化时,我偶然发现了以下几点: 目前,Kafka Streams在启用时会执行两种优化: 1-源KTable将源主题重新用作变更日志主题。 2-如果可能,Kafka流会将多个重新分区主题压缩为单个重新分区主题。 这个问题是关于第一点的。我不完全明白这里发生了什么。只是为了确保我没有在这里做任何假设。有人能解释一下,以前是什么状态吗: 1-KTable使用内部变更日志主题吗?如果是,有人能
-
性能优化 - 缓存
ES 内针对不同阶段,设计有不同的缓存。以此提升数据检索时的响应性能。主要包括节点层面的 filter cache 和分片层面的 request cache。下面分别讲述。 filter cache ES 的 query DSL 在 2.0 版本之前分为 query 和 filter 两种,很多检索语法,是同时存在 query 和 filter 里的。比如最常用的 term、prefix、rang
-
渲染性能优化
优化提升渲染性能,不仅能让页面更快的展现、可交互,同时能提升用户操作滚动的流畅度,对提升用户体验至关重要。 避免不必要的更新对比 Rax 同 React 一样,render 时会有 vdom 对比,如果对比发现 DOM 没有变化时,不会去真正更新页面。而本身 vdom 对比也是不小的消耗,你应该避免这种不必要的更新对比,使用 shouldComponentUpdate 方法明确标识你的组件什么时候