《算法优化》专题
-
 首面 - AIGC算法工程师
首面 - AIGC算法工程师2023/05/08 首先自我介绍 他介绍他们公司是干嘛的:基于大厂在Github上开源的人工智能项目,主要是图像生成,进行优化再卖出去。 实习生的主要职责就是了解这些技术,能在本地搭建环境跑通,使用工具调整参数,并且上面给出写好的代码需要能修改代码。所以Pytroch这一块得很有了解。 其次是了解很多开源项目,比如Gam,复旦Moss等等 了解起来成本真的巨大
-
 美团算法一面凉经
美团算法一面凉经美团算法一面凉经 1、面试官自我介绍、简单介绍部门 2、自我介绍 3、问实习经历、讲一个科研项目 4、想做深度学习还是想做传统的机器学习(回答:都可以) 5、有了解哪些传统的机器学习算法(讲了逻辑回归、决策树、支持向量机等) 6、有了解哪些深度学习的算法 7、再次问想做深度学习还是想做传统的机器学习,然后介绍他们部门主要做传统的机器学习算法的,项目大多关于深度学习的,询问是否感兴趣?(回答:都可以
-
浅谈java多线程 join方法以及优先级方法
本文向大家介绍浅谈java多线程 join方法以及优先级方法,包括了浅谈java多线程 join方法以及优先级方法的使用技巧和注意事项,需要的朋友参考一下 join: 当A线程执行到了B线程的.join()方法时,A就会等待。等B线程都执行完,A才会执行。 join可以用来临时加入线程执行。 1、线程使用join方法,主线程就停下,等它执行完,那么如果该线程冻结了,主线程就挂了,这也是为什么线程要
-
Python:掩盖列表的优雅高效方法
问题内容: 例: 结果是: 如您所见,与列表相比,对数组进行屏蔽的操作更为优雅。如果您尝试使用列表中的数组屏蔽方案,则会收到错误消息: 问题是要为s找到一个优雅的蒙版。 更新: 通过引入的答案,但是提出的要点使解决方案完全符合我的兴趣。 问题答案: 你在找 文档中的示例 相当于:
-
eclipse修改jvm参数调优方法(2种)
本文向大家介绍eclipse修改jvm参数调优方法(2种),包括了eclipse修改jvm参数调优方法(2种)的使用技巧和注意事项,需要的朋友参考一下 本文介绍了eclipse修改jvm参数调优方法(2种),分享给大家,具体如下: 一般在不对eclipse进行相关设置的时候,使用eclipse总是会觉得启动好慢,用起来好卡,其实只要对eclipse的相关参数进行一些配置,就会有很大的改善。 有两种
-
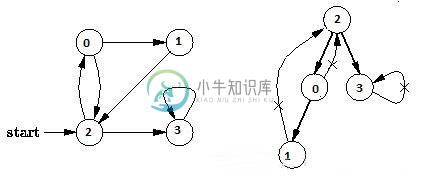 C++深度优先搜索的实现方法
C++深度优先搜索的实现方法本文向大家介绍C++深度优先搜索的实现方法,包括了C++深度优先搜索的实现方法的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了图的遍历中深度优先搜索的C++实现方法,是一种非常重要的算法,具体实现方法如下: 首先,图的遍历是指从图中的某一个顶点出发,按照某种搜索方法沿着图中的边对图中的所有顶点访问一次且仅访问一次。注意到树是一种特殊的图,所以树的遍历实际上也可以看作是一种特殊的图的遍历。图
-
Nodejs异步回调的优雅处理方法
本文向大家介绍Nodejs异步回调的优雅处理方法,包括了Nodejs异步回调的优雅处理方法的使用技巧和注意事项,需要的朋友参考一下 前言 Nodejs最大的亮点就在于事件驱动, 非阻塞I/O 模型,这使得Nodejs具有很强的并发处理能力,非常适合编写网络应用。在Nodejs中大部分的I/O操作几乎都是异步的,也就是我们处理I/O的操作结果基本上都需要在回调函数中处理,比如下面的这个读取文件内容的
-
Spring Cloud Config Eureka-优先方法不起作用
我正在开发一个Spring Cloud Eureka微服务应用程序。我希望我的服务通过尤里卡优先的方法连接到配置服务。微服务被打包为docker容器,并通过Docker-Compose进行部署。该应用程序由以下人员组成: :使用Spring Cloud Eureka实现的服务注册服务 :Spring云配置服务服务器 :一个示例微服务,它应该尝试通过Eureka-first方法连接到配置服务来获取配
-
语法规则优先是如何工作的?
这是我的语法文件: https://github.com/frankdu/minijs/blob/master/antlr/src/main/resources/org/minijs/parser/antlr/javascript.g4 问题在于语句解析。当它看到break语句时 https://github.com/frankdu/minijs/blob/master/core/src/test
-
无法设置namenode进程xxxxx的优先级
AL01299205:Hadoop用户$/usr/local/cellar/hadoop/3.2.1/sbin/start-dfs.sh 正在启动[AL01299205.Local]上的namenodes AL01299205.Local:错误:无法设置namenode进程24897的优先级
-
有没有办法在Haskell中表示静态数据?或者在Haskell中还有其他优雅的DFS遍历算法吗?
我正在尝试使用递归算法构造DFS树。 这个的伪代码是: . 虽然通过为未访问/访问的节点构造某种数据结构、为它们分配动态分配或某种声明,我可以用命令式语言以简单的方式很容易地实现这一点,但对于Haskell来说,这是不可能的,因为Haskell的纯净性使我无法在传递参数时更改数据。 这是我使用DFS ish(或者更确切地说是BFS ish)算法进行图形遍历时得到的结果,但问题是它将再次访问不在点路
-
Java for循环优化
问题内容: 我使用java for循环进行了一些运行时测试,并发现了一种奇怪的行为。对于我的代码,我需要原始类型(例如int,double等)的包装对象来模拟io和输出参数,但这不是重点。只是看我的代码。具有字段访问权限的对象如何比原始类型更快? 优先类型的循环: 结果: MicroTime原语(最大值:= 10000.0):110 MicroTime原语(最大值:= 100000.0):1081
-
摇摆动画优化
问题内容: 我一直在使用一个简单的动画上。但是,当观看动画时,我会遇到难以置信的震荡。我应该采取什么步骤来优化此代码? 不知道这是否重要,但是我正在使用OpenJDK 1.8.0_121版本。 任何帮助表示赞赏。 问题答案: 在与Yago进行了精彩的讨论之后,我发现问题围绕多个领域展开,很大程度上归因于Java将更新与操作系统和硬件同步的能力,有些是您可以控制的,有些是无法控制的。 受到Yago的
-
Java 7排序“优化”
问题内容: 在Java6中,quicksort和mergesort分别在中用于原始数组和对象数组。在Java7中,它们都已更改为DualPivotQuicksort和Timsort。 在新的快速排序的来源中,以下注释出现在几个地方(例如354行): 这是一个性能问题吗?编译器不会将这些简化为同一件事吗? 更广泛地说,调查自己的最佳策略是什么?我可以运行基准测试,但对分析已编译代码中的任何差异会更感
-
graphql解析器优化
如果我有模式: 和一个解析器: 和两个可能的查询。问题#1: 和查询#2: 是否可以优化冲突解决程序,使查询#1 readAllPosts仅从数据库中提取标题,而查询#2则同时提取标题和lotsofdata? 我查看了parent、args、context和info参数,但看不到任何指示解析器是否被调用以响应像#1或#2这样的查询的内容。