《算法求职》专题
-
 递归算法
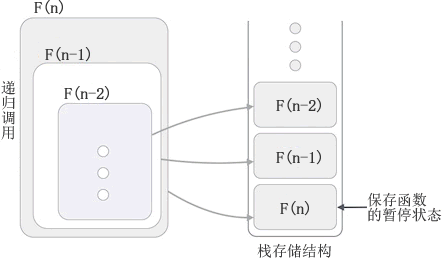
递归算法主要内容:递归的底层实现机制编程语言中,我们习惯将函数(方法)调用自身的过程称为 递归,调用自身的函数称为 递归函数,用递归方式解决问题的算法称为 递归算法。 函数(方法)调用自身的实现方式有 2 种,分别是: 1) 直接调用自身,例如: 2) 间接调用自身,例如: 程序中,function1() 函数内部调用了 function2() 函数,而 function2() 函数内部又调用了 function1() 函数。也就是
-
 回溯算法
回溯算法主要内容:回溯VS递归,回溯算法的实现过程回溯算法,又称为 “试探法”。解决问题时,每进行一步,都是抱着试试看的态度,如果发现当前选择并不是最好的,或者这么走下去肯定达不到目标,立刻做回退操作重新选择。这种走不通就回退再走的方法就是回溯算法。 例如,在解决列举集合 {1,2,3} 中所有子集的问题中,就可以使用回溯算法。从集合的开头元素开始,对每个元素都有两种选择:取还是舍。当确定了一个元素的取舍之后,再进行下一个元素,直到集合最后一个元
-
投弹算法
我有一个由非负整数组成的矩阵。例如: “投下炸弹”将目标单元及其所有八个相邻单元的数量减少一个,至少为零。 确定将所有单元减少到零所需的最小炸弹数量的算法是什么? B选项(由于我不是一个细心的读者) 事实上,这个问题的第一个版本并不是我要寻找的答案。我没有仔细阅读整个任务,还有其他限制,让我们说: 那么简单的问题呢,当行中的序列必须是非递增的: 是可能的输入序列 不可能,因为7- 也许为“更容易”
-
高耸算法
问题内容: 在《破解编码面试》第四版中,存在这样的问题: 马戏团正在设计一个塔楼套路,由站在一个人的肩膀上的人组成。出于实际和美学的原因,每个人都必须比其下方的人矮一些和矮一些。考虑到马戏团中每个人的身高和体重,编写一种方法来计算此类塔楼中的最大人数。 示例:输入(ht,wt):(65,100)(70,150)(56,90)(75,190)(60,95)(68,110) 输出:最长的塔长为6,从上
-
7.20.Dijkstra 算法
我们将用于确定最短路径的算法称为“Dijkstra算法”。Dijkstra算法是一种迭代算法,它为我们提供从一个特定起始节点到图中所有其他节点的最短路径。这也类似于广度优先搜索的结果。 为了跟踪从开始节点到每个目的地的总成本,我们将使用顶点类中的 dist 实例变量。 dist实例变量将包含从开始到所讨论的顶点的最小权重路径的当前总权重。该算法对图中的每个顶点重复一次;然而,我们在顶点上迭代的顺序
-
4.4.6 Floyd算法
一、弗洛伊德算法介绍 和Dijkstra算法一样,弗洛伊德(Floyd)算法也是一种用于寻找给定的加权图中顶点间最短路径的算法。该算法名称以创始人之一、1978年图灵奖获得者、斯坦福大学计算机科学系教授罗伯特·弗洛伊德命名。 基本思想 通过Floyd计算图G=(V,E)中各个顶点的最短路径时,需要引入一个矩阵S,矩阵S中的元素a[i][j]表示顶点i(第i个顶点)到顶点j(第j个顶点)的距离。
-
4.4.5 Dijkstra算法
一、迪杰斯特拉算法介绍 迪杰斯特拉(Dijkstra)算法是典型最短路径算法,用于计算一个节点到其他节点的最短路径。 它的主要特点是以起始点为中心向外层层扩展(广度优先搜索思想),直到扩展到终点为止。 基本思想 通过Dijkstra计算图G中的最短路径时,需要指定起点s(即从顶点s开始计算)。 此外,引进两个集合S和U。S的作用是记录已求出最短路径的顶点(以及相应的最短路径长度),而U则是
-
4.4.4 Prim算法
一、普里姆算法介绍 普里姆(Prim)算法,是用来求加权连通图的最小生成树的算法。 基本思想 对于图G而言,V是所有顶点的集合;现在,设置两个新的集合U和T,其中U用于存放G的最小生成树中的顶点,T存放G的最小生成树中的边。 从所有uЄU,vЄ(V-U) (V-U表示出去U的所有顶点)的边中选取权值最小的边(u, v),将顶点v加入集合U中,将边(u, v)加入集合T中,如此不断重复,直到U=V为
-
4.4.3 Kruskal算法
一、最小生成树 在含有n个顶点的连通图中选择n-1条边,构成一棵极小连通子图,并使该连通子图中n-1条边上权值之和达到最小,则称其为连通网的最小生成树。 例如,对于如上图G4所示的连通网可以有多棵权值总和不相同的生成树。 二、克鲁斯卡尔算法介绍 克鲁斯卡尔(Kruskal)算法,是用来求加权连通图的最小生成树的算法。 基本思想:按照权值从小到大的顺序选择n-1条边,并保证这n-1条边不构成回路。
-
算法 - 目录
算法分析 排序 并查集 栈和队列 符号表 其它 参考资料 Sedgewick, Robert, and Kevin Wayne. Algorithms. Addison-Wesley Professional, 2011.
-
算法 - 排序
待排序的元素需要实现 Java 的 Comparable 接口,该接口有 compareTo() 方法,可以用它来判断两个元素的大小关系。 使用辅助函数 less() 和 swap() 来进行比较和交换的操作,使得代码的可读性和可移植性更好。 排序算法的成本模型是比较和交换的次数。 // java public abstract class Sort<t extends="" comparable
-
算法 - 其它
有三个柱子,分别为 from、buffer、to。需要将 from 上的圆盘全部移动到 to 上,并且要保证小圆盘始终在大圆盘上。 这是一个经典的递归问题,分为三步求解: ① 将 n-1 个圆盘从 from -> buffer ② 将 1 个圆盘从 from -> to ③ 将 n-1 个圆盘从 buffer -> to 如果只有一个圆盘,那么只需要进行一次移动操作。 从上面的讨论可以知道,an
-
Python Dijkstra算法
问题内容: 我正在尝试编写Dijkstra的算法,但是我在努力如何在代码中“说”某些事情而苦苦挣扎。为了可视化,这是我要使用数组表示的列: 因此,将有几个数组,如下面的代码所示: 粗体部分是我要坚持的地方-我正在尝试实现算法的这一部分: 3.对于当前节点,请考虑其所有未访问的邻居并计算其暂定距离。 例如,如果当前节点(A)的距离为6,并且将其与另一个节点(B)相连的边为2,则通过A到B的距离将为6
-
Jarvis March算法
本文向大家介绍Jarvis March算法,包括了Jarvis March算法的使用技巧和注意事项,需要的朋友参考一下 Jarvis March算法用于从一组给定的数据点中检测凸包的角点。 从数据集的最左端开始,我们通过逆时针旋转将这些点保留在凸包中。从当前点开始,我们可以通过从当前点检查这些点的方向来选择下一个点。当角度最大时,将选择该点。完成所有点后,当下一个点是起点时,停止算法。 输入输出
-
贪婪算法
本文向大家介绍贪婪算法相关面试题,主要包含被问及贪婪算法时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 贪婪算法(贪心算法)是指在对问题进行求解时,在每一步选择中都采取最好或者最优(即最有利)的选择,从而希望能够导致结果是最好或者最优的算法。贪婪算法所得到的结果往往不是最优的结果(有时候会是最优解),但是都是相对近似(接近)最优解的结果。贪婪算法并没有固定的算法解决框架,算法的关键是贪婪策