《优化》专题
-
如何优化Flutter App大小?
我是本地Android开发者,我开始使用Flatter SDK。我开发了一个简单的应用程序,遵循官方的颤振文件。但是我发现调试应用的大小是46MB,对于这个简单的应用来说太大了。有没有办法优化应用程序的大小?因为Flatter应用程序的大小比原生Android应用程序大。
-
JavaScript性能优化-代码篇
JavaScript代码优化 1、慎用全局变量 为什么要慎用全局变量原因如下 1、全局变量定义在全局执行上下文,是所有作用域链的顶端 2、全局执行上下文一直存在于上下文执行站,直到程序退出 3、如果某个局部作用域出现了同名变量则会遮蔽或污染全局 2、缓存全局变量 其实就是在程序执行过程中,将使用中无法避免的全局变量缓存到局部 代码演示如下 1、普通写法: function getBt
-
JavaScript性能优化-概念篇
介绍 这本栏文章中主要介绍的是JavaScript的性能优化 我们都知道,随着软件开发行业的不断发展,性能优化呢已经是一个不可避免的话题。 那么什么样的行为才能算得上是性能优化呢?本质上来说,任何一种可以提高运行效率, 降低运行开销的行为,我们都可以看作是一种优化操作, 这也就意味着在软件开发过程中必然存在着很多值得优化的地方。 特别是在前端应用开发过程中性能优化我们可以认为是无处不在的
-
3.2. 自动加载器优化
优化级别1:类映射生成 怎么运行它呢? 有几个选项可以启用此功能: 在 composer.json 的配置中设置 "optimize-autoloader": true 使用 -o / --optimize-autoloader 调用安装或更新 使用 -o / --optimize 调用 dump-autoload 它有什么作用? 类映射生成实质上是将 PSR-4/PSR-0 规则转换为类映射规
-
1.6.9 继续优化 mvc 结构
继续优化mvc结构 好吧,上一小节,给出了如何简单的把目录下的文件挂载到某个对象上,并发布npm上 照着这个思路,我们造了几个简单的库,用于挂载某个目录里的文件 mount-controllers mount-models mount-middlewares 1)mount-controllers var $ = require('mount-controllers')(__dirname).or
-
Tomcat 安装和配置、优化
Tomcat 8 安装 Tomcat 8 安装 官网:http://tomcat.apache.org/ Tomcat 8 官网下载:http://tomcat.apache.org/download-80.cgi 此时(20160207) Tomcat 8 最新版本为:apache-tomcat-8.0.32.tar.gz 我个人习惯 /opt 目录下创建一个目录 setups 用来存放各种软件
-
18.6. 优化字符串操作
18.6. 优化字符串操作 Soundex 算法的最后一步是对短结果补零和截短长结果。最佳的做法是什么? 这是目前在 soundex/stage2/soundex2c.py 中的做法: digits3 = re.sub('9', '', digits2) while len(digits3) < 4: digits3 += "0" return digit
-
18.3. 优化正则表达式
18.3. 优化正则表达式 Soundex 函数的第一件事是检查输入是否是一个空字符串。 怎样做是最好的方法? 如果你回答 “正则表达式”,坐在角落里反省你糟糕的直觉。正则表达式几乎永远不是最好的答案,而且应该被尽可能避开。 这不仅仅是基于性能考虑,而是因为差错和维护都很困难,当然性能也是个原因。 这是 soundex/stage1/soundex1a.py 检查 source 是否全部由字母构成
-
5. DPDK - 网卡性能优化
运行在操作系统内核态的网卡驱动程序基本都是基于异步中断处理模式,而DPDK采用了轮询或者轮询混杂中断的模式来进行收包和发包。DPDK起初的纯轮询模式是指收发包完全不使用任何中断,集中所有运算资源用于报文处理。但这不是意味着DPDK不可以支持任何中断。根据应用场景需要,中断可以被支持,最典型的就是链路层状态发生变化的中断触发与处理。 任何包进入到网卡,网卡硬件会进行必要的检查、计算、解析和过滤等,最
-
7.4. 优化数据库结构
7.4.1. 设计选择 7.4.2. 使你的数据尽可能小 7.4.3. 列索引 7.4.4. 多列索引 7.4.5. MySQL如何使用索引 7.4.6. MyISAM键高速缓冲 7.4.7. MyISAM索引统计集合 7.4.8. MySQL如何计算打开的表 7.4.9. MySQL如何打开和关闭表 7.4.10. 在同一个数据库中创建多个表的缺陷 7.4.1. 设计选择 MySQL将行数据和索
-
禁止函数被优化掉
例子 #if (GCC_VERSION > 4000) #define DEBUG_FUNCTION __attribute__ ((__used__)) #define DEBUG_VARIABLE __attribute__ ((__used__)) #else #define DEBUG_FUNCTION #define DEBUG_VARIABLE #endif DEBUG_FUNCT
-
调试,测试以及优化
我们小型的 microblog 应用程序已经足够的完善了,因此是时候准备尽可能地清理不用的东西。近来,一个读者反映了一个奇怪的数据库问题,我们今天将会调试它。这也提醒我们不论我们是多小心以及测试我们应用程序多仔细,我们还是会遗漏一些 bug。用户是很擅长发现它们的! 不是仅仅修复此错误,然后忘记它,直到我们遇到另一个。我们会采取一些积极的措施,以更好地准备下一个。 在本章的第一部分,我们将会涉及到
-
9.1. 优化指标的选取
优化指标的选取 由于A/B 测试的目的是对产品进行针对性优化,因此我们需要提前对现有数据进行收集。下面列举了一些产品改进中的关键业务数据供参考: 留存率 用户活跃度(如:在线时长、启动次数等) 转化率(如:申请转化、购买转化等) 用户行为(如:功能使用度、购物车结算行为等) 之后,对关键业务数据进行分析,推断可能造成数据表现不佳的关键因素,找出可以进行优化的关键点,从而提高其产生的用户行为数据表现
-
hikaricp - HikariCP可以怎么优化?
项目的数据库连接我是用HikariCP,单个增删查改速度是还算快的。但请求一多,速度就变得很慢很慢了。请问这个可以怎么优化? 然后我是这么配置的
-
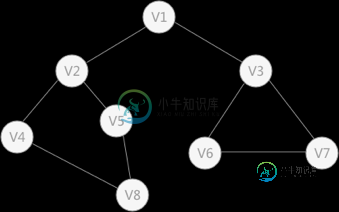 深度优先搜索和广度优先搜索
深度优先搜索和广度优先搜索主要内容:深度优先搜索(简称“深搜”或DFS),广度优先搜索,总结前边介绍了有关图的 4 种存储方式,本节介绍如何对存储的图中的顶点进行遍历。常用的遍历方式有两种: 深度优先搜索和 广度优先搜索。 深度优先搜索(简称“深搜”或DFS) 图 1 无向图 深度优先搜索的过程类似于树的先序遍历,首先从例子中体会深度优先搜索。例如图 1 是一个无向图,采用深度优先算法遍历这个图的过程为: 首先任意找一个未被遍历过的顶点,例如从 V1 开始,由于 V1 率先访问过了,所以