《优化》专题
-
优化java 8流操作
我在这里使用的所有方法几乎都是O(1)复杂度,比较器也不太费力,所以这不应该是问题,有什么我可能不知道的东西可以帮助我优化这个流操作吗?也许我用的入口集可以避免...?因为这可能是这里最贵的手术... 编辑1:也许我应该解释一下这个方法背后的想法。它的主要目的是对地图aux进行排序,并返回一个带有排序键的列表(键也被修改了,但这不是主要目的)
-
优化批量插入,SQLite
问题内容: 我在将不同的缓冲区大小插入到本地SQLite DB中时发现,当缓冲区大小为10,000时,插入10,000,000行数据需要花费近8分钟的时间。换句话说,它需要1,000次写入来存储所有内容。 8分钟存储10,000,000个似乎太长了(或者是?) 可以优化以下任何一项以提高速度吗?请注意,插入的数据是字符的随机集合。 创建表格后,通过 是否可以进一步优化上述任何一项? 问题答案: 我
-
如何进行SQL优化?
本文向大家介绍如何进行SQL优化?相关面试题,主要包含被问及如何进行SQL优化?时的应答技巧和注意事项,需要的朋友参考一下 (1)选择正确的存储引擎 MyISAM 适合于一些需要大量查询的应用,但其对于有大量写操作并不是很好。甚至你只是需要update一个字段,整个表都会被锁起来,而别的进程,就算是读进程都无法操作直到读操作完成。另外,MyISAM 对于 SELECT COUNT(*) 这类的计算
-
react性能优化方案
本文向大家介绍react性能优化方案相关面试题,主要包含被问及react性能优化方案时的应答技巧和注意事项,需要的朋友参考一下 重写shouldComponentUpdate来避免不必要的dom操作0 使用 production 版本的react.js0 使用key来帮助React识别列表中所有子组件的最小变化。 参考链接: https://segmentfault.com/a/119000000
-
 iOS性能优化浅析
iOS性能优化浅析本文向大家介绍iOS性能优化浅析,包括了iOS性能优化浅析的使用技巧和注意事项,需要的朋友参考一下 本文将从原理出发,解释卡顿发生的原理,然后会讲解项目中行之有效的几个优化点,最后会展望一下接下来将要尝试的方向。下面进入正题。 屏幕显示的原理 屏幕显示原理 我们知道,远古时代的CRT显示器的显示原理是用电子枪扫描荧光屏来发光。如上图所示,电子枪按照从左到右,然后从上到下的顺序扫描。当电子枪换到新的
-
MySQL查询优化-加入?
问题内容: 一个供您所有MySQL专家使用的技巧:-) 我有以下查询: 订单表= 80,900行 产品表= 125,389行 o.id和p.order_id已建立索引 该查询大约需要6秒钟才能完成-太长了。我正在寻找一种优化它的方法,可能使用临时表或其他类型的联接。恐怕我对这两个概念的理解还很有限。 谁能建议我优化此查询的方法? 问题答案: 首先,我将使用其他样式的语法。 已经有20年的睡眠时间了
-
SQL查询-性能优化
问题内容: 我不太擅长SQL,因此我要求你们提供有关编写查询的帮助。 [SQL查询-表连接问题]https://codingdict.com/questions/208252) 我得到了答案,并且可以正常工作!它只是明显的缓慢。我讨厌这样做,但是我真的希望有人在那里推荐一些优化查询的方法。我什至没有自己尝试过,因为我对SQL不够了解,甚至无法开始使用谷歌搜索。 问题答案: 可能有帮助的是在要加入的
-
优化INSERT / UPDATE / DELETE操作
问题内容: 我想知道以下脚本是否可以某种方式进行优化。它确实在磁盘上写了很多东西,因为它可能删除了最新的行并重新插入它们。我正在考虑应用“在重复键更新中插入…”之类的东西,并发现了单行更新的一些可能性,但我不知道如何在的上下文中应用它。 编辑: 的架构,,,:http://pastebin.com/3tRVPPVi。 要点是更新列和中的内容。表上有一个触发器,可根据这些列设置列的值。 in是表中的
-
优化oracle jdbc批插入
我需要使用JDBC在Oracle数据库中进行大量插入,即两位数百万。为此,我使用了类似于以下类的东西,灵感来自使用JDBC进行批处理插入的高效方法: 虽然这种插入方式很好,但速度非常慢。JDBC batch insert performance描述了MySQL基本上可以解决这个问题,因为在Oracle上似乎不存在,但在这里没有太大帮助。 为了提高性能,我还尝试将语句切换为一个大的
-
优化tomcat启动时间
我的应用程序非常大,例如,在web inf/lib中包含310个JAR,总计100Mb。启动服务器,以下步骤需要13秒: 该应用程序依赖于web片段和注释来正确启动。 我尝试了以下方法来跳过13秒的扫描时间: > 修改<code>conf/context。属性为logEffectiveWebXml=“true”的xml 中提取< code>web.xml片段,将其保存在< code > web a
-
Volatile和编译器优化
如果关闭了编译器优化(gcc-o0...),那么说'volatile'关键字没有区别是可以的吗? 我制作了一些示例“C”程序,并且仅当打开编译器优化时,才在生成的汇编代码中看到易失性和非易失性之间的区别,即((gcc-o1....)。
-
优化Node.js内存消耗
不是内存泄漏或类似的问题,因为第一次连接后内存使用量不会增加,所以优化可能是加载更少的模块或做一些不同的事情...
-
优化阵列的分区
我当时正在解决一个编程挑战问题,但我的解决方案是对大量数据给出超时/错误。有人能帮我优化解决方案吗? 问题: 给你一个由N个整数组成的数组。现在需要固定X,使以下两个值之间的差值最小: 如果X的值更多,则打印最小的一个。 约束: <代码>1 输入: 第一行包含整数N(表示大小) 第二行包含空格分隔的数字(用于数组) 我在测试这个输入 答案应该是2(如果从零开始计算,那么是1),但我的代码给出了4。
-
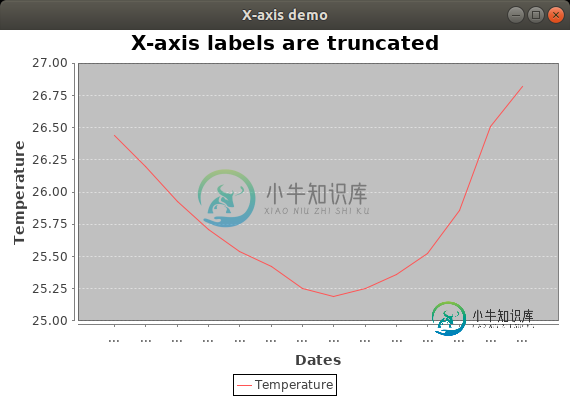 Jfreechart优化X轴标签
Jfreechart优化X轴标签在JFreechart中,我有一个带有日期(和时间)的X轴。 我怎样才能让JFreechart优化它们并充分利用它们? 现在它包含的标签比空间多,所有标签都转换为“…”。 如果不是所有的刻度都有标签,这是完全可以的,但是我想要尽可能多的(如果它们合适并且可以完全显示)。 我怎样才能做到这一点? 这里是完整的最小源来重现截断的标签。(默认情况下,JFreechart不处理优化: 我更喜欢像@tras
-
我应该优化多少?
关于编译器(GCC)所做的优化,标准做法是什么?每个选项(-O、-O1、-O2、-O3、-Os、-s、-fexpensive-optimizations)有什么不同,我如何决定什么是最优的?