《优化》专题
-
第六章: 基准分析与调优 - 尾部调用优化 (TCO)
尾部调用优化 (TCO) 正如我们早前简单提到的,ES6包含了一个冒险进入性能世界的具体需求。它是关于在函数调用时可能会发生的一种具体的优化形式:尾部调用优化(TCO)。 简单地说,一个“尾部调用”是一个出现在另一个函数“尾部”的函数调用,于是在这个调用完成后,就没有其他的事情要做了(除了也许要返回结果值)。 例如,这是一个带有尾部调用的非递归形式: function foo(x) { r
-
使用application / json优于text / plain的优势?
问题内容: 使用内容类型application / json通过文本/纯文本发送序列化为json的对象有什么性能优势?我知道许多框架(例如Spring)都可以根据内容类型映射和序列化数据,但是总的来说,我发现此过程非常简单,因此对于在JSON对象上使用application / json而不是text / plain的应用,这并不是一个令人信服的理由。 。 问题答案: 假设您正在谈论使用JSON与
-
优化Spring-Data JPA查询
问题内容: 我正在寻找框架生成的查询的可能的优化。据我了解,该过程如下: 你可以声明你的域对象是POJO和增加几个注解像,,等等。 您声明您的存储库,例如每个接口 使用(2),您可以通过多种方式描述您的查询:例如,每个方法名或 如果我写这样的查询: 将自动生成一个SQL查询,其中解析订单的每一列,并随后解析订单位置和相关对象/表。好像我写了: 因此,以防万一,我需要来自 多个 连接对象的 一些 信
-
编译器会优化吗
问题内容: 假设我在C代码中有类似的内容。我知道您可以使用a 代替,以使编译器不对其进行编译,但是出于好奇,我问编译器是否也可以解决此问题。 我认为这对于Java编译器来说更为重要,因为它不支持。 问题答案: 在Java中,if内的代码甚至都不是已编译代码的一部分。它必须编译,但不会写入已编译的字节码。它实际上取决于编译器,但我不知道没有对它进行优化的编译器。规则在JLS中定义: 优化的编译器可能
-
用于REGEXP的MySQL优化
问题内容: 在我的慢速查询日志中,此查询(使用不同的名称而不是“ jack”)发生了很多次。为什么? Users表具有许多字段(超过我选择的这三个字段)和大约40.000行。 是主要的,并且是自动递增的。 有一个索引。 具有唯一索引。 有时需要3秒钟!如果我在MySQL上解释选择,我会得到: 这是我能做的最好的吗?我该如何解决? 问题答案: 如果必须使用regexp-style 子句,则肯定会遇到
-
优化mysql全文搜索
问题内容: 我想在我的网页中进行全文搜索。我需要分页进行搜索。我的数据库每张表有50,000+行。我已经改变了我的表,并使其成为索引。该表始终处于更新状态,仍然有一个自动增加的列。而最新的总是在表格的末尾。 但整个查询时间将花费。我通过Google搜索了许多文章,有的文章写道,只有限制字段字长才能帮助更快地进行搜索。但作为一种类型,它会像这样改变一定的长度(我尝试过标题TEXT(500) CHAR
-
MySQL5.6基本优化配置
本文向大家介绍MySQL5.6基本优化配置,包括了MySQL5.6基本优化配置的使用技巧和注意事项,需要的朋友参考一下 下面开始优化下my.conf文件(这里的优化只是在mysql本身的优化,之前安装的时候也要有优化) cat /etc/my.cnf # For advice on how to change settings please see # http://dev.mysql.com/d
-
优化mysql之key_buffer_size设置
本文向大家介绍优化mysql之key_buffer_size设置,包括了优化mysql之key_buffer_size设置的使用技巧和注意事项,需要的朋友参考一下 key_buffer_size key_buffer_size指定索引缓冲区的大小,它决定索引处理的速度,尤其是索引读的速度。通过检查状态值Key_read_requests和Key_reads,可以知道key_buffer_size设
-
MYSQL更新优化实录
本文向大家介绍MYSQL更新优化实录,包括了MYSQL更新优化实录的使用技巧和注意事项,需要的朋友参考一下 引言 今天(August 5, 2015 5:34 PM)在给数据库中一张表的结构做一次调整,添加了几个字段,后面对之前的数据进行刷新,刷新的内容是:对其中的一个已有字段url进行匹配,然后更新新加的字段type和typeid。后来就写了个shell脚本来刷数据,结果运行shell脚本后我就
-
Python性能优化技巧
本文向大家介绍Python性能优化技巧,包括了Python性能优化技巧的使用技巧和注意事项,需要的朋友参考一下 Python是一门非常酷的语言,因为很少的Python代码可以在短时间内做很多事情,并且,Python很容易就能支持多任务和多重处理。 py 1、关键代码可以依赖于扩展包 Python使许多编程任务变得简单,但是对于很关键的任务并不总是提供最好的性能。使用C、C++或者机器语言扩展包
-
Tensorflow:使用Adam优化器
问题内容: 我正在尝试使用张量流中的一些简单模型,包括一个看起来与第一个MNIST for ML Beginners示例 非常相似的模型,但具有更大的维度。我能够毫无问题地使用梯度下降优化器,获得足够好的收敛性。当我尝试使用ADAM优化器时,出现如下错误: 抱怨未初始化的特定变量根据运行而变化。这个错误是什么意思?这表明错了吗?无论我使用什么学习率,它似乎都会发生。 问题答案: AdamOptim
-
SQL优化经验总结
本文向大家介绍SQL优化经验总结,包括了SQL优化经验总结的使用技巧和注意事项,需要的朋友参考一下 一. 优化SQL步骤 1. 通过 show status和应用特点了解各种 SQL的执行频率 通过 SHOW STATUS 可以提供服务器状态信息,也可以使用 mysqladmin extende d-status 命令获得。 SHOW STATUS 可以根据需要显示 session 级别的
-
js如何性能优化?
本文向大家介绍js如何性能优化?相关面试题,主要包含被问及js如何性能优化?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 减少HTTP请求 使用内容发布网络(CDN) 添加本地缓存 压缩资源文件 将CSS样式表放在顶部,把javascript放在底部(浏览器的运行机制决定) 避免使用CSS表达式 减少DNS查询 使用外部javascript和CSS 避免重定向 图片lazyLoad
-
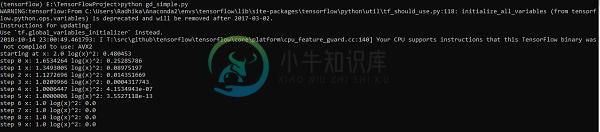 TensorFlow梯度下降优化
TensorFlow梯度下降优化梯度下降优化是数据科学中的一个重要概念。考虑下面显示的步骤,以了解梯度下降优化的实现 - 第1步 包括必要的模块和声明和变量,我们将通过它来定义梯度下降优化。 第2步 初始化必要的变量并调用优化器来定义和调用相应的函数。 上面的代码行生成一个输出,如下面的屏幕截图所示 - 可以看到必要的时期和迭代的计算如上面输出中所示。
-
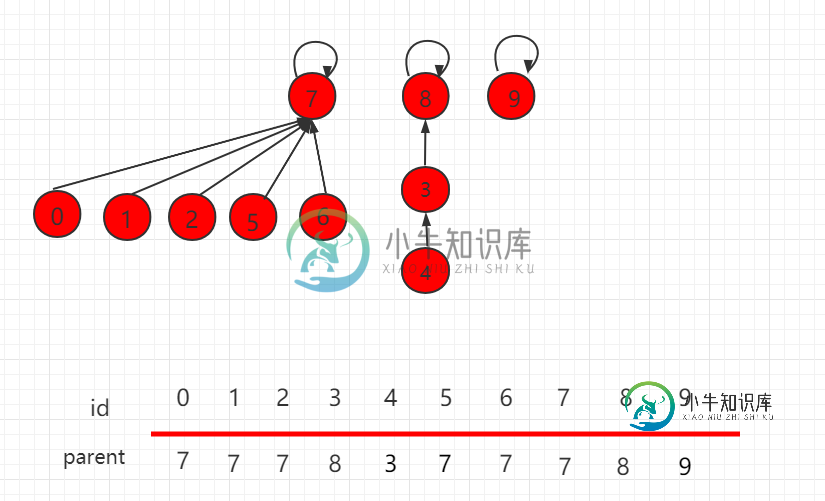 并查集 rank 的优化
并查集 rank 的优化主要内容:UnionFind3.java 文件代码:上一小节介绍了并查集基于 size 的优化,但是某些场景下,也会存在某些问题,如下图所示,操作 union(4,2)。 根据上一小节,size 的优化,元素少的集合根节点指向元素多的根节点。操完后,层数变为4,比之前增多了一层,如下图所示: 由此可知,依靠集合的 size 判断指向并不是完全正确的,更准确的是,根据两个集合层数,具体判断根节点的指向,层数少的集合根节点指向层数多的集合根节点,如下图