《推荐算法实习》专题
-
Adam算法
Adam算法在RMSProp算法基础上对小批量随机梯度也做了指数加权移动平均 [1]。下面我们来介绍这个算法。 算法 Adam算法使用了动量变量$\boldsymbol{v}_t$和RMSProp算法中小批量随机梯度按元素平方的指数加权移动平均变量$\boldsymbol{s}_t$,并在时间步0将它们中每个元素初始化为0。给定超参数$0 \leq \beta_1 < 1$(算法作者建议设为0.9
-
AdaDelta算法
除了RMSProp算法以外,另一个常用优化算法AdaDelta算法也针对AdaGrad算法在迭代后期可能较难找到有用解的问题做了改进 [1]。有意思的是,AdaDelta算法没有学习率这一超参数。 算法 AdaDelta算法也像RMSProp算法一样,使用了小批量随机梯度$\boldsymbol{g}_t$按元素平方的指数加权移动平均变量$\boldsymbol{s}_t$。在时间步0,它的所有元
-
RMSProp算法
我们在“AdaGrad算法”一节中提到,因为调整学习率时分母上的变量$\boldsymbol{s}_t$一直在累加按元素平方的小批量随机梯度,所以目标函数自变量每个元素的学习率在迭代过程中一直在降低(或不变)。因此,当学习率在迭代早期降得较快且当前解依然不佳时,AdaGrad算法在迭代后期由于学习率过小,可能较难找到一个有用的解。为了解决这一问题,RMSProp算法对AdaGrad算法做了一点小小
-
AdaGrad算法
在之前介绍过的优化算法中,目标函数自变量的每一个元素在相同时间步都使用同一个学习率来自我迭代。举个例子,假设目标函数为$f$,自变量为一个二维向量$[x_1, x_2]^\top$,该向量中每一个元素在迭代时都使用相同的学习率。例如,在学习率为$\eta$的梯度下降中,元素$x_1$和$x_2$都使用相同的学习率$\eta$来自我迭代: $$x_1 \leftarrow x_1 - \eta \f
-
9.11 算法
当你编写一个针对一类问题的通用解法,而非针对某一个问题的特定解法时,你就写出了一个算法。我在第一章提到过这个词,但是没有给出详细定义。这也不太好定义,所以我会试用多种方式进行定义。 首先,考虑一些不是算法的问题。当你学习个位数乘法时,你可能会背乘法表。实际上你记住的是100个特定解法,这种知识并不是真正意义的算法。 但是,如果你很“懒”,你可能学习一些作弊技巧。比如,求n与9的乘积,你可以在第一位
-
10 算法
算法策略 分治法T(n)=O(nlogn) 将问题分解成规模较小、相互独立的子问题,各个击破,分而治之。 归并排序 将数列分为几个序列片段,逐趟两两归并,到底层归并成有序数列 最大子段和问题 动态规划法T(n)=O(nW) 将问题分解成互不独立子问题,保存子问题解,需要时再用,例如多项式时间算法 0/1背包问题 LCS最长公共子序列 贪心/贪婪法T(n)=O(n) 不从整体最优考虑,只根据当前信息
-
LRU 算法
一、前言 上一章《Memcached源码分析 - Memcached源码分析之增删改查操作(5) 》中,我们讲到了SET命令的操作。当客户端向Memcached服务端SET一条缓存数据的时候,会将生成的Item地址挂到LRU的链表结构上。这一章节,我们主要讲一下Memcached是如何使用LRU算法的。 LRU:是Least Recently Used 近期最少使用算法。 二、Memcached的
-
1.-算法
名称 原理 复杂度 插入排序 对于元素索引i(i>=1),从头开始,若能找到比 a[i] 大对元素 a[j],则记录 a[i] 的值,将索引 j~i-1 的元素向后移动一位,使用 a[i] 替换 a[j]。优化思路:针对数组可以采用二分查找找到当前元素的插入位置,链表不需要位移操作。 O(n^2/2) 选择排序 从当前元素开始遍历,记录最小值的索引,根据索引交换当前值的最小值,选择排序每次选出最小
-
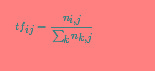 TF-IDF算法解析与Python实现方法详解
TF-IDF算法解析与Python实现方法详解本文向大家介绍TF-IDF算法解析与Python实现方法详解,包括了TF-IDF算法解析与Python实现方法详解的使用技巧和注意事项,需要的朋友参考一下 TF-IDF(term frequency–inverse document frequency)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。比较容易理解的一个应用场景是当
-
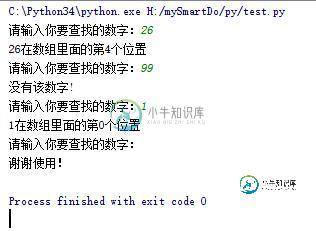 python有序查找算法 二分法实例解析
python有序查找算法 二分法实例解析本文向大家介绍python有序查找算法 二分法实例解析,包括了python有序查找算法 二分法实例解析的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了python有序查找算法 二分法实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 二分法是一种快速查找的方法,时间复杂度低,逻辑简单易懂,总的来说就是不断的除以2除以2... 但是
-
html5 - vue3+ts+element plus开发的web项目,前端导出打印插件/功能实现推荐?
vue3+ts+element plus开发的web项目,想针对客户的table查询结果导出打印需求,实现前端打印功能,请问有什么比较好的插件或者实现代码思路推荐嘛? 之前.net mvc开发的web项目,报表是使用rdlc插件来实现的。现在这种前后端分离,纯vue开发的前端有无好的实现插件或者思路呢。
-
为什么React并不推荐我们优先考虑使用Context?
本文向大家介绍为什么React并不推荐我们优先考虑使用Context?相关面试题,主要包含被问及为什么React并不推荐我们优先考虑使用Context?时的应答技巧和注意事项,需要的朋友参考一下 1、Context目前还处于实验阶段,可能会在后面的发行版本中有很大的变化,事实上这种情况已经发生了,所以为了避免给今后升级带来大的影响和麻烦,不建议在app中使用context。 2、尽管不建议在app
-
谁能推荐一个简单的Java Web应用程序框架?
问题内容: 我正在尝试着用Java开发一个相对快速的Web应用程序,但是我尝试过的大多数框架(Apache Wicket,Liftweb)都需要大量的设置,配置和尝试,在使整个过程与Eclipse融为一体的同时,全神贯注于Maven,我整个周末都在试图写我的第一行代码! 谁能推荐一个简单的Java Webapp框架,它不涉及Maven,难以置信的复杂目录结构或无数必须手动编辑的XML文件? 问题答
-
为什么在DOM级别3中不推荐使用DOMSubtreeModified事件?
问题内容: 为什么不推荐使用 DOMSubtreeModified事件,而应该使用什么呢? 问题答案: 如果向下滚动一点,您会看到: 警告!该接口是在DOM Level 2事件中引入的,但尚未在用户代理之间完全且可互操作地实现。另外,也有人批评说,接口的设计会给性能和实现带来挑战。一个新的规范正在开发中,其目的是解决突变事件解决的用例,但以更有效的方式。因此,本规范描述了变异事件,以供参考和遗留行
-
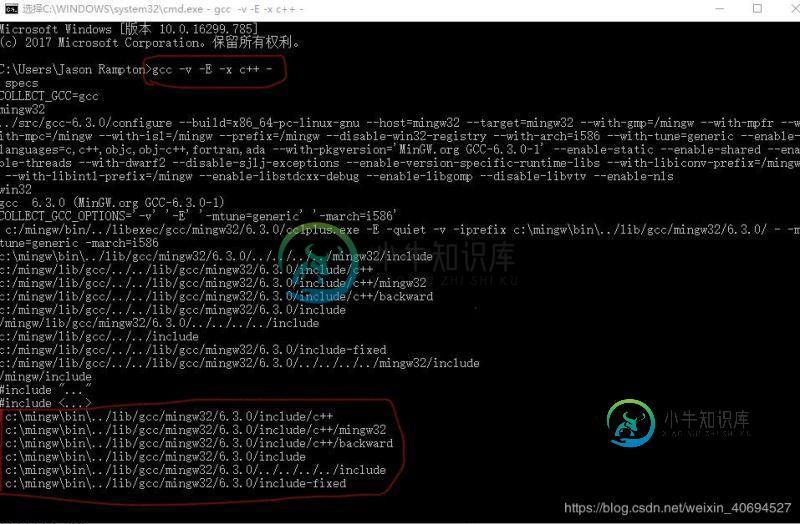 解析VScode在Windows环境下c_cpp_properties.json文件配置问题(推荐)
解析VScode在Windows环境下c_cpp_properties.json文件配置问题(推荐)本文向大家介绍解析VScode在Windows环境下c_cpp_properties.json文件配置问题(推荐),包括了解析VScode在Windows环境下c_cpp_properties.json文件配置问题(推荐)的使用技巧和注意事项,需要的朋友参考一下 初次使用VScode,我们都会碰到一个问题,就是在编写C和C++源文件时,头文件提示未配置好等错误。关于这个问题,给出方案如下:我想大家