《顺丰机器学习》专题
-
可以在顺序流上使用收集器的合并器功能吗?
问题内容: 示例程序: 因此,为简化起见,没有最终转换,因此生成的代码非常简单。 现在,产生一个顺序流。我只是将结果装箱到s中,然后将其收集到中。很简单 而且,无论我运行此示例程序多少次,都不会成功,这意味着永远不会调用我的虚拟组合器。 我有点期望,但是后来我已经误解了流,以至于我不得不问这个问题… 可以将的组合时,流过被称为 保证 是连续的? 问题答案: 仔细阅读ReduceOps.java中的
-
学Java做项目需要学习的一些技能
本文向大家介绍学Java做项目需要学习的一些技能,包括了学Java做项目需要学习的一些技能的使用技巧和注意事项,需要的朋友参考一下 Java就是用来做项目的!Java的主要应用领域就是企业级的项目开发!要想从事企业级的项目开发,你必须掌握如下要点: 1、掌握项目开发的基本步骤 2、具备极强的面向对象的分析与设计技巧 3、掌握用例驱动、以架构为核心的主流开发方法 没有人愿意自己一辈子就满足于掌握了一
-
java学习 - 哪里有付费的Java学习课程?
如题,培训班出来的,教的东西都很浅,感觉完全不够用,想再补充自己提高自己。请问哪里有进阶的课程资料,要视频的,有语音讲解的,我知道免费的资源有很多,但是鱼龙混杂,质量参差不齐,挑选成本太高。付费的至少质量方面肯定比免费的好吧。大家有什么推荐吗?谢谢。
-
如何用数学在Java中模拟60%的概率。随机的
如果有60%的可能性,我想做点什么(只使用Math.random()。例如,数组中的每个值都有60%的几率被设置为1,否则为0。 我的困惑是我们是否应该检查一下 或 我的想法是,它应该是第一个,因为0.0算作可能的返回值,但我想确认我应该使用哪一个,以及为什么。
-
ES6 迭代器(Iterator)和 for.of循环使用方法学习(总结)
本文向大家介绍ES6 迭代器(Iterator)和 for.of循环使用方法学习(总结),包括了ES6 迭代器(Iterator)和 for.of循环使用方法学习(总结)的使用技巧和注意事项,需要的朋友参考一下 一、什么是迭代器? 生成器概念在Java,Python等语言中都是具备的,ES6也添加到了JavaScript中。Iterator可以使我们不需要初始化集合,以及索引的变量,而是使用迭代器
-
Python中的with语句与上下文管理器学习总结
本文向大家介绍Python中的with语句与上下文管理器学习总结,包括了Python中的with语句与上下文管理器学习总结的使用技巧和注意事项,需要的朋友参考一下 0、关于上下文管理器 上下文管理器是可以在with语句中使用,拥有__enter__和__exit__方法的对象。 相当于以下情况的简化: 换言之,PEP 343中定义的上下文管理器协议允许将无聊的try...except...fina
-
request.getParameterNames()的顺序
问题内容: 如何以相同的顺序获取HTML表单中的所有parameterNames。 即,如果表单包含…。FirstName,LastName,MiddleName和Age。输出应该以相同的顺序出现 我尝试使用以下内容,但这会改变输出的顺序: 问题答案: 我认为HTTP规范中没有任何内容可以强制浏览器按照它们在表单中出现的顺序发送参数。您可以通过在参数名称前添加数字来解决此问题,例如: 之后,您基本
-
书写顺序
书写顺序 1. 不强制要求声明的书写顺序。 如果团队规范有要求,建议使用工具来自动化排序,比如 CSScomb,或者使用 @wangjeaf 开发的 ckstyle 推荐以声明的特性作为分组,不同分组间保留一个空行,例如: .dialog { /* 定位 */ margin: auto; position: absolute; top: 0; bottom: 0; righ
-
flex order 顺序
flex order 排序,一般情况下浏览器会把元素从左到右或者从上到下排列,如果我们想要更改它们的排列顺序该如何做呢?使用order就可以轻松的修改。数字越大越往后,数字越小越在前。 1. 官方定义 order 属性设置或检索弹性盒模型对象的子元素出现的順序。 2. 解释 子元素可以通过设置 order 数值的大小来设定在页面中出现的顺序,数值小的在前,数值大的在后。 3. 语法 .item-c
-
顺序结构
顺序结构 #include <stdio.h> #include <stdlib.h> int main01(void) { printf("%d \n", 1);//顺序结构,从上往下执行,从main函数开始 printf("%d \n", 11); printf("%d \n", 111); printf("%d \n", 1111); sys
-
 上海高仙机器人 前端实习面经
上海高仙机器人 前端实习面经一面: 发现录的音频没有录到对方的...只能凭记忆 自我介绍 项目 vue的生命周期 vue的一些方法(没太懂问的什么,好像是v-if之类的) 项目构建的过程 搭建路由的过程(这两个问题好像也不太明白要问什么hhh) 常用的ui框架(答了vant和element-ui) 追问:为什么觉得这两个比较常用? 小程序分包 项目里面怎么解决的跨域(proxy代理) 追问:怎么设置 垂直居中 两边固定中间自
-
 网易伏羲机器人测开实习面经
网易伏羲机器人测开实习面经timeline: 5.23 hr电话约面 5.29 业务一面 6.13 hr电话约二面 6.17 业务二面 6.20 hr面并于下午被告知通过 7.2 offer通过审批 基本信息 本人bg本科东北末9机器人工程专业,二战上岸上海某双一流电子信息专业,目前研0gap阶段,本科期间0实习经历基本0竞赛。拟录取后一直在家里属于躺不平摆不烂的状态,于是从4月底开始在网上搜索有无专业对口实习。网易是我投
-
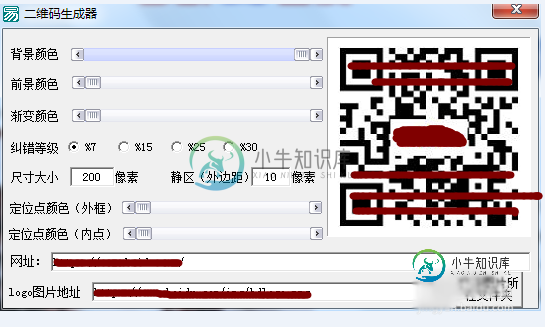 易语言二维码生成器制作教学
易语言二维码生成器制作教学本文向大家介绍易语言二维码生成器制作教学,包括了易语言二维码生成器制作教学的使用技巧和注意事项,需要的朋友参考一下 二维码的使用度和普及度相当的高,无论是在广告推送、网站跳转、信息获取,还是在手机支付都在应用,网页的上生成二维码就见不少,现在用易语言来来看怎样制作二维码生成器,当然这里也是调用API接口,所以难度不大! 1、百度搜索一下二维码开入平台,选择一个开放、免费的可以调用的接入就可以了,这
-
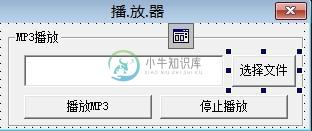 易语言编写小巧的播放器教学
易语言编写小巧的播放器教学本文向大家介绍易语言编写小巧的播放器教学,包括了易语言编写小巧的播放器教学的使用技巧和注意事项,需要的朋友参考一下 本次小编来教大家如何制作一个小巧使用的播放器。 废话少说,上图! 1、我们先设计一下界面,弄成这样。 当然可以依据个人所好来制作界面。 2、设置一下通用对话框的属性(就是灰色正方形里面有窗口的那个小东东)。 1、代码 进入代码阶段。 其实也不怎么难,就几句代码。。。看图。 这是按下播
-
Java8流收集器中断HashMap插入语义学?
所以我试图使用Java8流Collectors.toMap添加元素到新创建的Map。 要创建的映射可能包含其某些键的空值。这对于HashMap来说是完全可以接受的,当我使用stream forEach添加成员时,它会按预期工作: msgRouteProps是一个映射,其中键和值都是非空的。请注意,ReflectionUtil。getNamedMethod()调用可能会返回null,我希望将其放入结