《算法岗》专题
-
 python实现感知器算法详解
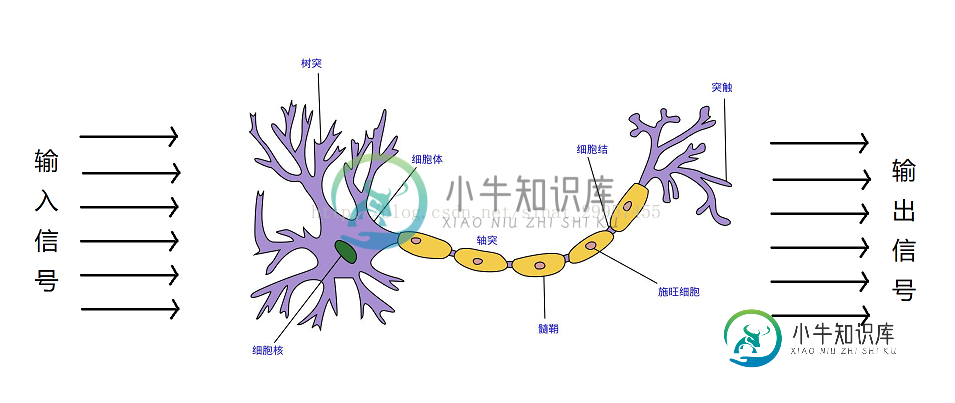
python实现感知器算法详解本文向大家介绍python实现感知器算法详解,包括了python实现感知器算法详解的使用技巧和注意事项,需要的朋友参考一下 在1943年,沃伦麦卡洛可与沃尔特皮茨提出了第一个脑神经元的抽象模型,简称麦卡洛可-皮茨神经元(McCullock-Pitts neuron)简称MCP,大脑神经元的结构如下图。麦卡洛可和皮茨将神经细胞描述为一个具备二进制输出的逻辑门。树突接收多个输入信号,当输入信号累加超过
-
 vue实现简单加法计算器
vue实现简单加法计算器本文向大家介绍vue实现简单加法计算器,包括了vue实现简单加法计算器的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了vue实现简单加法计算器的具体代码,供大家参考,具体内容如下 只需要简单两步 1.模板结构,设计界面 2.处理数据和控制逻辑 代码: 以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持呐喊教程。
-
 Python3运算符常见用法分析
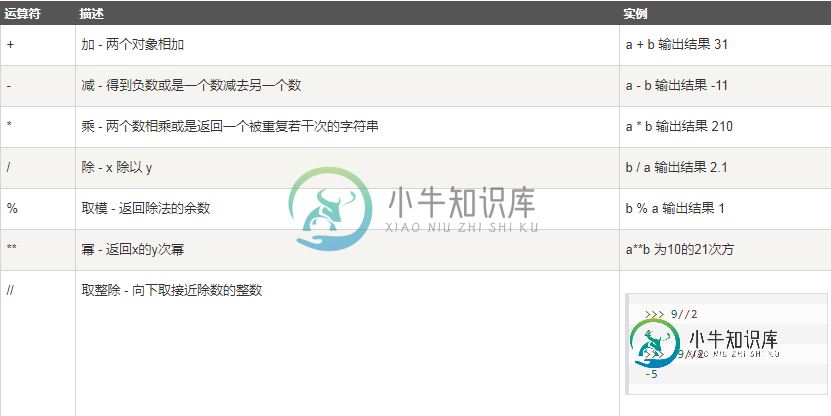
Python3运算符常见用法分析本文向大家介绍Python3运算符常见用法分析,包括了Python3运算符常见用法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python3运算符常见用法。分享给大家供大家参考,具体如下: 4.1算数运算符(以下假设变量a为10,变量b为21) 实例操作: 结果: 4.2赋值运算符(以下假设变量a为10,变量b为20) 4.3比较(关系)运算符(以下假设变量a为10,变量b为20)
-
java实现Base64加密解密算法
本文向大家介绍java实现Base64加密解密算法,包括了java实现Base64加密解密算法的使用技巧和注意事项,需要的朋友参考一下 Base64是网络上最常见的用于传输8Bit字节代码的编码方式之一,大家可以查看RFC2045~RFC2049,上面有MIME的详细规范。Base64编码可用于在HTTP环境下传递较长的标识信息。例如,在Java Persistence系统Hibernate中,就
-
Python hashlib常见摘要算法详解
本文向大家介绍Python hashlib常见摘要算法详解,包括了Python hashlib常见摘要算法详解的使用技巧和注意事项,需要的朋友参考一下 这篇文章主要介绍了Python hashlib常见摘要算法详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等 计算出一个字
-
python实现八大排序算法(1)
本文向大家介绍python实现八大排序算法(1),包括了python实现八大排序算法(1)的使用技巧和注意事项,需要的朋友参考一下 排序 排序是计算机内经常进行的一种操作,其目的是将一组”无序”的记录序列调整为”有序”的记录序列。分内部排序和外部排序。若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序。反之,若参加排序的记录数量很大,整个序列的排序过程不可能完全在内存中完成,需要访问
-
python实现八大排序算法(2)
本文向大家介绍python实现八大排序算法(2),包括了python实现八大排序算法(2)的使用技巧和注意事项,需要的朋友参考一下 本文接上一篇博客python实现的八大排序算法part1,将继续使用python实现八大排序算法中的剩余四个:快速排序、堆排序、归并排序、基数排序 5、快速排序 快速排序是通常被认为在同数量级(O(nlog2n))的排序方法中平均性能最好的。 算法思想: 已知一组无序
-
MySQL:计算行数的最快方法
问题内容: 在MySQL中,哪种方式计算行数应该更快? 这个: 或者,替代方案: 有人会认为第一种方法应该更快,因为在内部确定类似情况时,这显然是数据库领域,而数据库引擎应该比其他任何人都要快。 问题答案: 当您使用count列索引时,它将是最好的结果。使用 MyISAM 引擎的Mysql 实际上存储行数,每次尝试对所有行进行计数时,它都不会对所有行进行计数。(基于主键的列) 使用PHP计数行不是
-
什么是算法的摊销分析?
问题内容: 与渐进分析有何不同?您何时使用它,为什么? 我读过一些写得不错的文章,例如: http://www.ugrad.cs.ubc.ca/~cs320/2010W2/handouts/aa-nutshell.pdf http://www.cs.princeton.edu/~fiebrink/423/AmortizedAnalysisExplained_Fiebrink.pdf 但我仍然没有完
-
基于ELO的团队匹配算法
我正在寻找一种非常简单的方法,用未知(但已知)数量的球员组建2支球队。因此,这实际上不是一个标准的配对,因为它只为特定的比赛在整个注册球员池中创建一场比赛。我几乎只有一个变量,它是每个球员的ELO分数,这意味着它是唯一可以用来计算的选项。 我想到的只是简单地检查每一个可能的球员组合(每队6名),球队平均ELO之间的最小差异是最终创建的名册。我已经测试过这个选项,它为18名注册玩家提供了超过1700
-
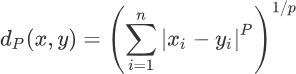 K-means聚类算法原理解析
K-means聚类算法原理解析主要内容:度量最小距离,总结通过《 什么是Kmeans聚类算法》一节的学习,我们了解了 K-means 聚类算法的聚类过程,其实就是不断寻找簇的质心的过程,该过程从随机设定 K 个质心开始,直到找到 K 个最合适的质心为止。本节我们透过算法流程直击算法的本质,帮助您彻底理解 K-means 算法。 度量最小距离 对于 K-means 聚类算法而言,找到质心是一项既核心又重要的任务,找到质心才可以划分出距离质心最近样本点。从数
-
 SVM分类算法应用及实现
SVM分类算法应用及实现主要内容:Sklearn库SVM算法,SVM算法应用SVM 是一种有监督学习分类算法,输入值为样本特征值向量和其对应的类别标签,输出具有预测分类功能的模型,当给该模型喂入特征值时,该模型可以它对应的类别标签,从而实现分类。 Sklearn库SVM算法 下面我看一下 Python 的 Scikit -Learn(简称 Sklearn) 库是如何实现 SVM 算法的。 支持向量机算法被包含在 sklearn.svm 模块中,该模块提供了 7 个常用类,
-
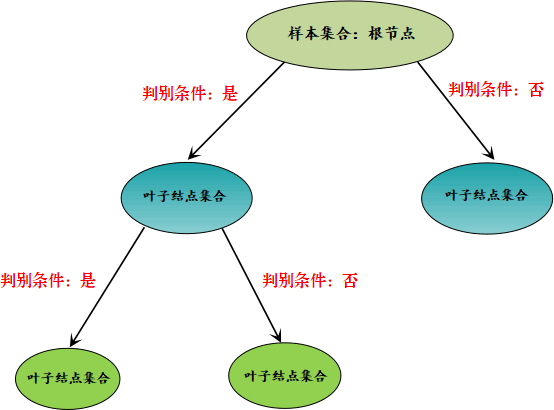 决策树算法和剪枝原理
决策树算法和剪枝原理主要内容:决策树算法原理,决策树剪枝策略本节我们对决策算法原理做简单的解析,帮助您理清算法思路,温故而知新。 我们知道,决策树算法是一种树形分类结构,要通过这棵树实现样本分类,就要根据 if -else 原理设置判别条件。因此您可以这样理解,决策树是由许多 if -else 分枝组合而成的树形模型。 决策树算法原理 决策树特征属性是 if -else 判别条件的关键所在,我们可以把这些特征属性看成一个 集合,我们要选择的判别条件都来自于
-
 二分查找(折半查找)算法
二分查找(折半查找)算法主要内容:折半查找算法,折半查找的性能分析,总结折半查找,也称 二分查找,在某些情况下相比于顺序查找,使用折半查找算法的效率更高。 但是该算法的使用的前提是静态查找表中的数据必须是有序的。 例如,在 这个查找表使用折半查找算法查找数据之前,需要首先对该表中的数据按照所查的关键字进行排序: 。 在折半查找之前对查找表按照所查的关键字进行排序的意思是:若查找表中存储的数据元素含有多个关键字时,使用哪种关键字做折半查找,就需要提前以该关键字对所有数据
-
A*搜索算法启发式函数
我正在尝试使用 A* 算法找到任何长度的滑动块拼图的最佳解决方案。 滑动积木拼图是一种游戏,白色(W)和黑色(B)的瓷砖排列在一个线性游戏板上,有一个单一的空白空间(-)。给定棋盘的初始状态,游戏的目的是将瓷砖排列成目标模式。 例如,我目前在董事会上的状态是BBW-WWB,我必须达到BBB-WWW状态。瓷砖可以通过以下方式移动:1.滑入相邻的空白空间,成本为1。2. 跳过另一个瓷砖进入空白区域,费