《索引》专题
-
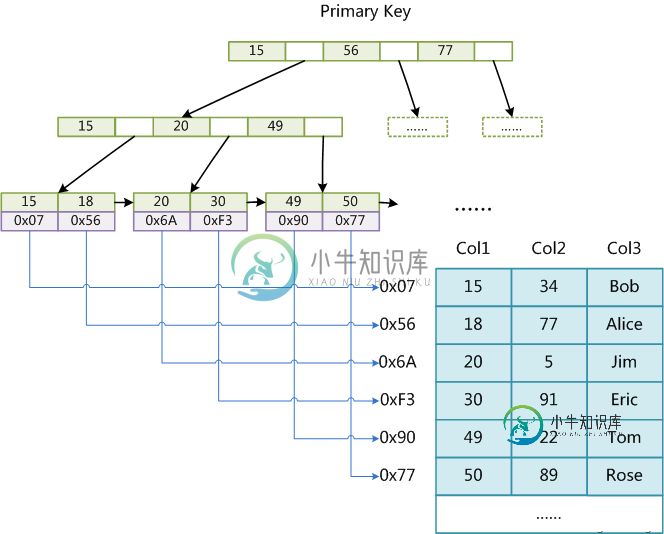 浅谈MySQL和Lucene索引的对比分析
浅谈MySQL和Lucene索引的对比分析本文向大家介绍浅谈MySQL和Lucene索引的对比分析,包括了浅谈MySQL和Lucene索引的对比分析的使用技巧和注意事项,需要的朋友参考一下 MySQL和Lucene都可以对数据构建索引并通过索引查询数据,一个是关系型数据库,一个是构建搜索引擎(Solr、ElasticSearch)的核心类库。两者的索引(index)有什么区别呢?以前写过一篇《Solr与MySQL查询性能对比》,只是简单的
-
从python pandas中的列名获取列索引
问题内容: 在R中,当您需要根据列名检索列索引时,可以执行此操作 有没有办法对熊猫数据框做同样的事情? 问题答案: 当然可以使用: 虽然老实说,我自己通常不需要这个。通常,通过名称进行访问可以实现我想要的功能(,或也许),尽管我可以肯定地看到一些情况下需要索引号的情况。
-
熊猫数据框到没有索引的JSON
问题内容: 我正在尝试采用一个数据框并将其转换为特定的json格式。 这是我的数据框示例: 这是我想转换成的json格式: 注意这是字典列表。我几乎在下面的代码中: 但是,该行还包含这样的索引: 请注意,这是一个字典,它还包含两次索引(在第一个字典中为索引,在第二个字典中为“ id”!对您有所帮助。 问题答案: 您可以使用
-
solr 我的内容实际被索引了吗?
本文向大家介绍solr 我的内容实际被索引了吗?,包括了solr 我的内容实际被索引了吗?的使用技巧和注意事项,需要的朋友参考一下 示例 人们经常尝试索引一些内容然后找到它。如果他们看不到预期的结果,则尝试对整个端到端过程进行故障排除。更好的方法是查看内容是否在预期字段中实际建立了索引。这样,它将问题分成两个部分:索引编制和搜索。 验证所索引内容的最简单方法是在Admin UI的“架构”屏幕(1)
-
在Python中按数组索引调用函数
问题内容: 我在Python out1,out2,out3等中有很多函数,并且想基于传入的整数来调用它们。 是否有捷径可寻? 问题答案: tl; dr:编写函数而不是,并且不要理会此hack。 我无法想象在实际情况中会出现这个问题的合理情况。请重新考虑问题的体系结构;可能会有一个更好的方法(因为将它们存储在列表中意味着除索引外,函数没有其他意义;例如,我只能想象如果要创建该函数,则可以这样做)一堆
-
尽管覆盖索引,MySQL MyISAM慢count()查询
问题内容: 我正在拔头发试图找出我做错了什么。该表非常简单: 如您所见,我创建了一个覆盖该表的所有三列的覆盖索引,并在上添加了一个潜在索引的附加索引。这是一对多链接表,每个链接表都映射到一个或多个链接表。该表包含6500万行。 所以,这就是问题所在。假设我想知道有多少人的icd代码为“ 25000”。[如果您想知道的话,那就是糖尿病]。我写了一个查询,看起来像这样: 这需要60秒钟以上的时间才能执
-
在非唯一列上创建唯一索引
问题内容: 不知道在PostgreSQL 9.3+中是否可行,但是我想在非唯一列上创建唯一索引。对于像这样的表: 我想仅能[快速]查询不同的日子。我知道我可以用来帮助执行不同的搜索,但是如果不同值的数量大大少于索引覆盖的行数,这似乎会增加额外的开销。就我而言,大约30天中有1天与众不同。 我是创建关系表以仅跟踪唯一条目的唯一选择吗?思维: 并在每次插入数据时使用触发器来更新它。 问题答案: 索引只
-
具有重复索引的增量Numpy数组
问题内容: 我有一个Numpy数组和一个索引列表,我想将其值加1。该列表可能包含重复的索引,我希望增量可以随每个索引的重复次数而缩放。没有重复,命令很简单: 通过重复,我想出了以下方法。 这是最好的方法吗?假设和操作将导致相同的排序顺序是否有风险?我是否缺少一些简单的Numpy操作来解决此问题? 问题答案: 做完之后 为什么不这样做: (为进一步简化而编辑。)
-
python pandas将索引转换为日期时间
问题内容: 如何将字符串的熊猫索引转换为日期时间格式 我的数据框“ df”是这样的 但是索引的类型是字符串,但是我需要一个日期时间格式,因为我得到了错误 使用时 问题答案: 它应该按预期工作。尝试运行以下示例。
-
mysql索引基数概念与用法示例
本文向大家介绍mysql索引基数概念与用法示例,包括了mysql索引基数概念与用法示例的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了mysql索引基数概念与用法。分享给大家供大家参考,具体如下: Cardinality(索引基数)是mysql索引很重要的一个概念 索引基数是数据列所包含的不同值的数量。例如,某个数据列包含值1、2、3、4、5、1,那么它的基数就是5。索引的基数相对于数据表
-
在numpy中索引多个非相邻范围
问题内容: 我想从一维numpy数组(或向量)中选择多个不相邻的范围。 假设: 当然,这可行: 这可以通过单个索引获取: 但是,如果我要选择范围,该怎么办? 我试过了: 有没有简单的方法可以执行此操作,或者我需要分别生成它们并进行连接? 问题答案: 您需要在索引之前或之后进行串联。 使它变得容易 扩展切片并将其连接。 您可以混合切片和列表: 在索引之前进行连接可能比在之后进行连接要快,但是对于这样
-
仅需要索引:枚举还是(x)范围?
问题内容: 如果我只想在循环中使用索引,则最好将函数与 还是?即使我根本不使用? 问题答案: 我会使用它,因为它更通用- 例如它将在可迭代对象和序列上工作,并且仅返回对对象的引用的开销并不算大-尽管(对我而言)按您的意图更易于阅读- 在不支持…的物体上折断
-
在Pandas DataFrame对象中重新定义索引
问题内容: 我正在尝试重新索引熊猫对象,像这样, 我正在如下所示进行操作,并且得到了错误的答案。有关如何执行此操作的任何线索? 知道为什么会这样吗? 问题答案: 为什么不简单地使用方法?
-
Python Pandas:在多列上建立布尔索引
问题内容: 尽管至少有两个 关于如何在Python的库中为DataFrame编制索引的优秀教程,但我仍然无法找到一种优雅的方法来编写多个列。 我已经发现(我认为是)这样一种不太优雅的方式 但这并不漂亮,可读性得分很低(我认为)。 有没有更好,更Python风格的方法? 问题答案: 这是一个优先运算符问题。 您应该添加额外的括号以使多条件测试正常工作: 您提到的教程的这一部分显示了带有几个布尔条件的
-
在JSON数组中查找元素的索引
问题内容: 我有一个看起来像这样的表: 还有其他几列与此问题无关。将它们存储为JSON是有原因的。 我要尝试的是查找具有特定 艺术家姓名 (精确匹配)的曲目。 我正在使用此查询: 例如 但是,这会进行全表扫描,而且速度不是很快。我尝试使用function创建一个GIN索引,并使用,但是未使用该索引,查询实际上要慢得多。 问题答案: 在Postgres 9.4+ 使用新的二进制JSON数据类型 ,P