《猿辅导内推》专题
-
引导导航栏链接颜色不会更改
我需要将导航栏链接更改为白色,并在导航栏上留出空间。我已经为此编写了代码,但我似乎不明白为什么/在哪里它一直被覆盖。导航栏的背景是一个图像,链接似乎变为白色,而图像不在其中,那么有没有办法修复这个问题并将图像保留在背景中? 有人能帮我理解我做错了什么吗?
-
使用引导程序的多级导航菜单
我们在学校的一个项目上出了点问题。我们正在尝试做一个电子商务网站和前端,我们想尝试bootstrap 4。但我们似乎不能去任何低于2级,任何建议都是欢迎的。我试着研究了不同的问题,但没有一个解决方案是有效的。 null null
-
尝试导出多个模块时出错。导出
我试图上传一个图像到内存使用multer,然后处理它与夏普和保存到磁盘。当我尝试在我的中间件中做多个module.exports时。 错误是: TypeError FileUpload.Single不是函数 到目前为止的路线是: 当我刚刚有下面的路由之前,尝试添加图像处理,我没有得到一个错误;
-
在单一类型导入中已定义导入
我需要帮助来找出如何解决活动中两个相互冲突的导入的问题,即: null 取决于哪一个先来。
-
在Cassandra中导入和导出键空间架构
问题内容: 我有一个卡桑德拉1.1.2安装我的系统为单节点集群上有三个keyspaces: ,和。我想尽可能地转储keyspace模式及其列族数据,并在其他Cassandra集群上恢复转储。谁能详细建议我该怎么做? 问题答案: 您可以使用和cassandra工具 退房Datastax 文档上相同,这也 您始终可以在文件中执行cassandra-cli命令 您可以将所有create语句加载到文件中并
-
 Fullpage.js固定导航栏-实现定位导航栏
Fullpage.js固定导航栏-实现定位导航栏本文向大家介绍Fullpage.js固定导航栏-实现定位导航栏,包括了Fullpage.js固定导航栏-实现定位导航栏的使用技巧和注意事项,需要的朋友参考一下 FullPage.js 是一个简单而易于使用的插件,用来创建全屏滚动网站(也被称为单页网站)。除了可以创建全屏滚动效果以外,也可以给网站添加一些水平的滑块效果。能够自适应不同的屏幕尺寸,包括平板电脑和移动设备。 开始制作自己的个人简历啦,决
-
从'react'导入*作为React; vs从'react'导入React;
问题内容: 我注意到可以这样导入: …或像这样: 第一个导入模块中的所有内容(请参阅:导入整个模块的内容) 第二个仅导入模块导出(请参阅:导入默认值) 似乎这两种方法是不同的,并且根本上是不兼容的。 为什么它们都起作用? 请参考源代码并解释该机制…我有兴趣了解其工作原理。 ES6常规模块信息回答了该问题。 我在问使模块像这样工作的机制。在这里,它似乎与源代码中的 “ hacky”导出机制有关,但尚
-
 SpringBoot中EasyExcel实现Excel文件的导入导出
SpringBoot中EasyExcel实现Excel文件的导入导出本文向大家介绍SpringBoot中EasyExcel实现Excel文件的导入导出,包括了SpringBoot中EasyExcel实现Excel文件的导入导出的使用技巧和注意事项,需要的朋友参考一下 前言 在我们日常的开发过程中经常会使用Excel文件的形式来批量地上传下载系统数据,我们最常用的工具是Apache poi,但是如果数据到底上百万时,将会造成内存溢出的问题,那么我们怎么去实现百万数据
-
确认导入*和xxx导入*之间的区别
问题内容: 我很惊讶地发现 和 对全球成员产生了不同的影响。我想确认我的实验是正确的行为。 在第一个示例中,更改foo模块中的成员将反映在所有导入foo的代码中。但是,在以后的情况下更改该成员似乎仅影响导入该成员的文件。换句话说,使用后一种方法将为每个导入文件提供其自己的foo成员副本。 我想要的行为是可以从所有文件访问foo.x,可以从所有文件更改它,并在所有文件中反映该更改(如果愿意,则为真正
-
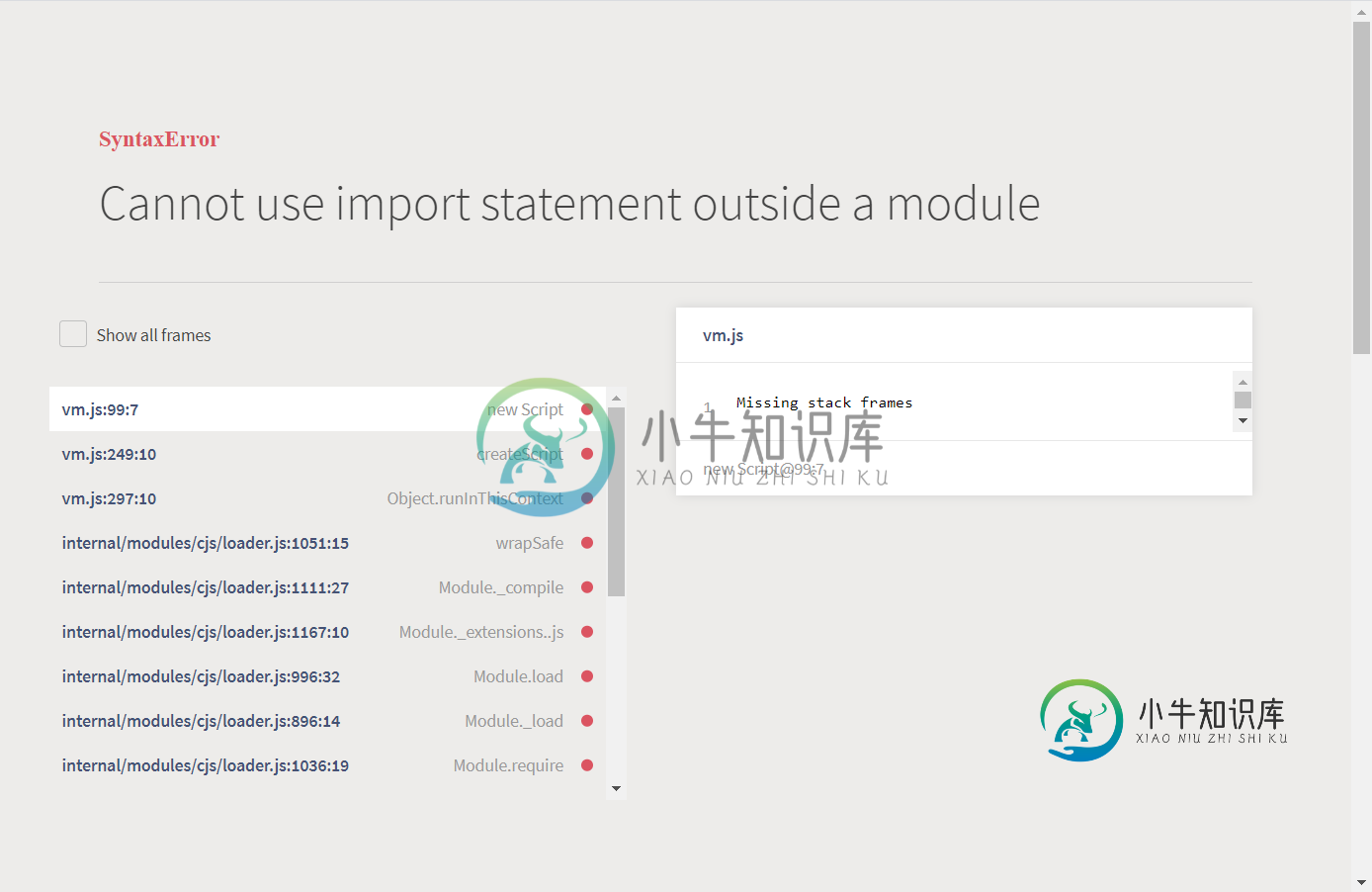 无法在nuxt vue组件中导入引导[duplicate]
无法在nuxt vue组件中导入引导[duplicate]我无法在任何vue组件中导入引导(使用最新的nuxtjs)。我得到: 我的(简单)组件是: 我真的被卡住了。你有什么想法或建议吗?
-
无法导入tensorflow,导入pywrap\u tensorflow时出错
我试图使用Keras序列,然而,我的jupyter笔记本充斥着错误,因为它无法在后端导入tenorflow(我想)。后来我发现,它不与Keras,但我不能做'导入tenstorflow作为tf'以及。 有什么建议吗?我正在使用python 3.5。6 tensorflow 1.12 我做了,pip的安装tenstorflow的安装。 ImportError回溯(最近一次调用上次)~\AppData
-
PHP实现CSV文件的导入和导出类
本文向大家介绍PHP实现CSV文件的导入和导出类,包括了PHP实现CSV文件的导入和导出类的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP实现CSV文件的导入和导出类。分享给大家供大家参考。具体如下: 希望本文所述对大家的php程序设计有所帮助。
-
Oracle 使用TOAD实现导入导出Excel数据
本文向大家介绍Oracle 使用TOAD实现导入导出Excel数据,包括了Oracle 使用TOAD实现导入导出Excel数据的使用技巧和注意事项,需要的朋友参考一下 在Oracle应用程序的开发过程中,访问数据库对象和编写SQL程序是一件乏味且耗费时间的工作,对数据库进行日常管理也是需要很多SQL脚本才能完成的。Quest Software为此提供了高效的Oracle应用开发工具-Toad。在T
-
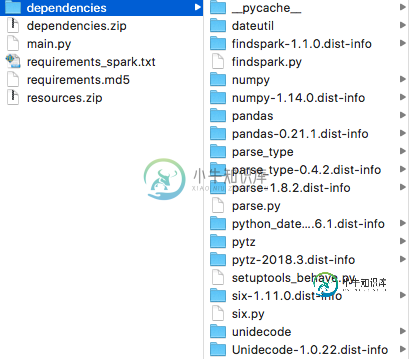 为PySpark绑定Python3包会导致缺少导入
为PySpark绑定Python3包会导致缺少导入我试图运行一个依赖于某些python3库的PySpark作业。我知道我可以在Spark Cluster上安装这些库,但是因为我正在为多个作业重用集群,所以我更愿意捆绑所有依赖项,并通过指令将它们传递给每个作业。 为此,我使用: 它有效地压缩了需要在根级别使用的包中的所有代码。 在my中,我可以导入依赖项 并将.zip添加到我的Spark上下文中 到目前为止还不错。 但出于某种原因,这将在星火星团的
-
导入有效包导致java编译器错误
我在编译顺序时遇到编译器错误。java文件,即使它包含另一个打包类的导入语句。我不完全确定为什么会发生这种情况,但这是一个目录树,其中包含一些文件: > com/my/domain/Order.java 这个文件里面有下面的包和导入: com/my/utils/MyDate。此文件中包含以下包和导入: 编译顺序时出现编译器错误。java: 我仍然不知道如何解决这个问题后,试图从评论。这里有一些更多