《猿辅导内推》专题
-
内联 fonts
Fonts can be really difficult to get right. First of all we have typically 4 different formats, but only one of them will be used by the respective browser. You do not want to inline all 4 formats, as
-
内联 images
Until HTTP/2 is here you want to avoid setting up too many HTTP requests when your application is loading. Depending on the browser you have a set number of requests that can run in parallel. If you l
-
内核栈
内核栈 为什么 / 怎么做 在实现内核栈之前,让我们先检查一下需求和我们的解决办法。 不是每个线程都需要一个独立的内核栈,因为内核栈只会在中断时使用,而中断结束后就不再使用。在只有一个 CPU 的情况下,不会有两个线程同时出现中断,所以我们只需要实现一个共用的内核栈就可以了。 每个线程都需要能够在中断时第一时间找到内核栈的地址。这时,所有通用寄存器的值都无法预知,也无法从某个变量来加载地址。为此,
-
 Spark内核
Spark内核主要内容:spark内核结构:,Spark通用流程spark内核结构: 1、Application 2、spark-submit 3、Driver 4、SparkContext 5、Master 6、Worker 7、Executor 8、Job 9、DAGScheduler 10、TaskScheduler 11、ShuffleMapTask and ResultTask yarn环境: 除了yarn环境外还有k8s和mesos环境 1.sub
-
内存块
简介 内存管理是操作系统内核中最复杂的部分之一(我认为没有之一)。在讲解内核进入点之前的准备工作时,我们在调用 start_kernel 函数前停止了讲解。start_kernel 函数在内核启动第一个 init 进程前初始化了所有的内核特性(包括那些依赖于架构的特性)。你也许还记得在引导时建立了初期页表、识别页表和固定映射页表,但是复杂的内存管理部分还没有开始工作。当 start_kernel
-
未使用的列表框项,如果内容不为 null,则会导致绑定错误
我注意到了ListBoxItem的这个奇怪的事情,即使你实际上没有对你创建的ListBoxItem做任何事情,如果它的内容不为空,它也会导致2个绑定错误。请注意,我没有创建任何绑定,我已经发布了重现这些错误所需的所有代码。 或者 不会导致任何错误,但 这方面的结果: 系统.Windows。数据错误:4:无法找到引用“RelativeSource FindAncestor,AncestorType=
-
安装后运行业力导致“业力”不被识别为内部或外部命令
问题内容: 使用以下方法安装业力后,我尝试将业力作为有 角种子 项目的一部分运行 我得到: 当我尝试从angular-client \ scripts运行test.bat时,此文件的内容为: 设置BASE_DIR =%〜dp0 业力开始“%BASE_DIR%.. \ config \ karma.conf.js”%* 我还尝试导航到“ \ AppData \ Roaming \ npm \ nod
-
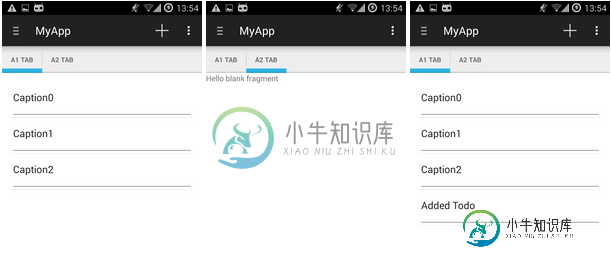 在导航抽屉片段之间切换后,无法在片段内添加ListView项目
在导航抽屉片段之间切换后,无法在片段内添加ListView项目编辑:我的滑动标签碎片ATabs似乎有问题。没有使用ATabs片段,只需使用导航抽屉在片段A1和B之间切换,一切都很好!可以添加列表项。编辑的主要活动: 但当我使用ATabs片段(见下面的MainActivity)并切换到它并返回时,就不可能再添加ListItems了。尽管Logcat显示日志。v(LOG_标签,“添加项”) 每次按add()。 我不知道是什么导致了这个问题。如果ATabs需要是一
-
如何从导入“存储”的vue路由器路由内部提交vuex存储变异?
我的目标是提交(调用/调用)我在Vuex存储中定义的突变。 商店。js 由于我将Vuex连接到我的应用程序,因此我可以使用,不会出现问题。 main.js 例如: omponent.vue 现在,我想从vue路由器路由文件中提交一些内容,使用方法: 例如路线。js 然而,当我尝试上述方法时,我得到了错误 网上有很多通过导入成功使用vuex getters的例子。而且,如果我导入,我可以看到我的整个
-
在其他模块中导入或使用内置模块名称时如何隐藏它
我使用python unittest框架做集成测试。为了消除混淆,我想以“集成测试”的方式继承TestCase类。TestCase”而不是“unittest”。TestCase". 此外,如果我也能做“import integrationtest”而不是“import unittest”,那就更好了,类似于“unittest.main()”,最好用“integrationtest.main()”来
-
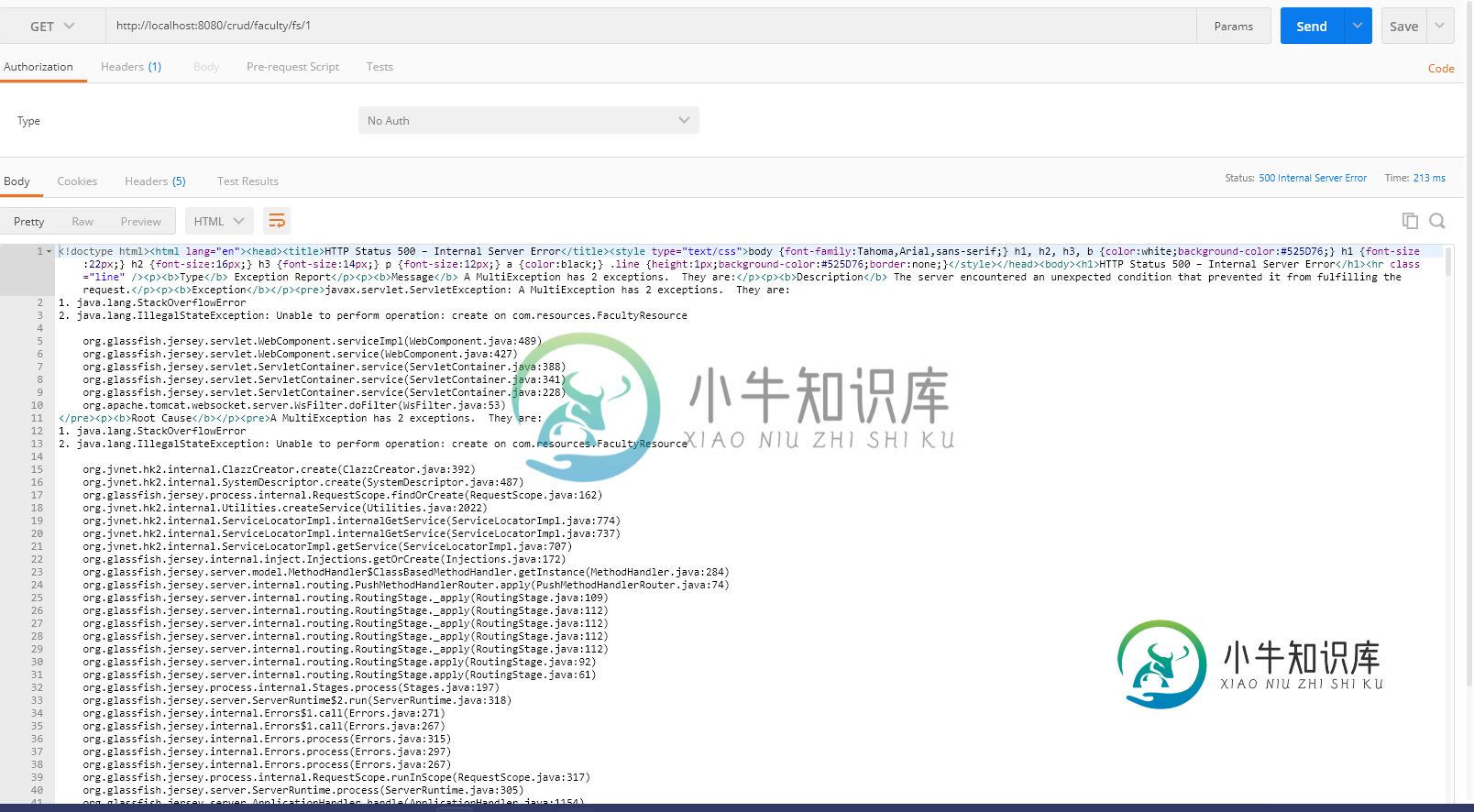 GET REQUEST无法正确返回教师数据导致500个内部服务器错误
GET REQUEST无法正确返回教师数据导致500个内部服务器错误我想让邮递员返回这个:显示通过id搜索的教员,并在教员内部显示学生的科目、教授和学生的成绩数据。 下面是GET请求调用的方法: public Faculty getFacultyStudent(int id)引发异常{连接=null; 此方法调用另外3个方法来生成学生、教授和成绩数据:此方法获取学生: 此方法可获得教授: 此方法获取等级: 这是主题和学生班: 学生班级: 主题类别: 我知道我没有正
-
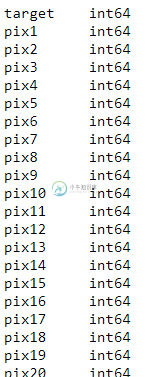 Pandas CSV导入中二进制变量减少内存占用的最佳数据类型
Pandas CSV导入中二进制变量减少内存占用的最佳数据类型我的原始文件为训练目的有25GB。我的机器有64GB的内存。用默认选项导入数据总是以“内存错误”告终,因此在阅读了一些帖子后,我发现最好的选项是定义所有的数据类型。 为了回答这个问题,我使用了100.7MB的CSV文件(它是从https://pjreddie.com/media/files/mnist_train.CSV获取的mnist数据集) 当我用Pandas中的默认选项导入时: 我的内存使用
-
是_uinit\uuuu。每次我从该模块导入任何内容时都运行py?[副本]
我有一个名为核心的模块,其中包含许多python文件。 如果我这样做: Does被呼叫?我可以将适用于所有核心文件的导入语句移动到保存重复自己?应该进入
-
防止泽西岛客户端在发布大文件时导致内存不足错误
使用 Jersey 客户端将大文件作为 InputStream 时,文件的全部内容似乎在发送到服务器之前已缓冲到内存中。这会导致大文件出现问题,因为 JVM 的堆空间不足。如何防止泽西岛客户端出现此行为?服务器端的 JAX-RS 资源方法在发送数据时似乎没有此问题。 例如:
-
java-full GC(垃圾收集器)在短时间内发生大量导致性能下降
你能解释一下这里发生了什么吗。 下面是gc.log上的输出。 .. Jul 18 14:52:49 fwprodcontent03 GC.log:3182.923:[GC[Psyounggen:0K->0K(2752512K)]2748930K->2748930K(10092544K),0.0607190秒][times:user=0.39 SYS=0.01,real=0.06秒] Jul 18