《亿联》专题
-
2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数?
本文向大家介绍2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数?相关面试题,主要包含被问及2.5亿个整数中找出不重复的整数的个数,内存空间不足以容纳这2.5亿个整数?时的应答技巧和注意事项,需要的朋友参考一下 整数个数一共有2^32个,可以将划分为2^8个区域,比如用一个文件代表一个区域,然后将数据分离到不同的区域,再在不同的区域利用bitmap就可以找个各自区域内不重复
-
5.1 亿书一个面向未来的自出版平台
前言 本篇的目的是通过一个产品的发行说明(白皮书),来了解产品最初的设计需求。无论是代码设计,还是源码分析,我们都要循着这些需求去渐次深入到代码内部,这样的思路,会帮助我们更加轻松、快速的掌握代码精髓。 亿书,是什么? 官方定义(白皮书 v1.0 2016.5.1) 亿书,英文名Ebook,是一个去中心化的出版平台,由新一代加密货币驱动,具备版权签名与认证、 协同创作、一键发布等功能,将促进人们更
-
对范围为10亿的100个不同值进行散列
-
 中国电信广东亿讯科技Java技术面试,已OC
中国电信广东亿讯科技Java技术面试,已OC一、基本情况 自我介绍 为什么只实习了三个月 为什么想来广州这边工作 在学校的成绩如何 二、Java知识 String,StringBuffer和StringBuilder的区别 抽象类和接口的区别 乐观锁和悲观锁 封装、继承和多态的概念 常见的异常类 List、Set和Map的区别 堆和栈的区别 JVM内存模型 final和static的区别 IO流 同步和异步 Java的垃圾回收机制 Spri
-
如何优化大多数出现的值(亿万行)的检索
问题内容: 我正在尝试从包含数亿行的SQLite表中检索一些最常出现的值。 到目前为止,查询可能如下所示: 该字段上有一个索引。 但是,使用ORDER BY子句,查询会花费很多时间,我从未见过它的结尾。 可以采取什么措施来大幅度改善对如此大量数据的此类查询? 我试图添加一个HAVING子句(例如:HAVING count> 100000)以减少要排序的行数,但是没有成功。 请注意,我不太在意插入所
-
Elasticsearch 对于大数据量(上亿量级)的聚合如何实现?
本文向大家介绍Elasticsearch 对于大数据量(上亿量级)的聚合如何实现?相关面试题,主要包含被问及Elasticsearch 对于大数据量(上亿量级)的聚合如何实现?时的应答技巧和注意事项,需要的朋友参考一下 Elasticsearch 提供的首个近似聚合是 cardinality 度量。它提供一个字段的基数,即该字段的 distinct 或者unique 值的数目。它是基于 HLL 算
-
 拼多多产品题:为什么京东也要做百亿补贴
拼多多产品题:为什么京东也要做百亿补贴Q:为什么京东也要做百亿补贴? A:本次复盘主要参考@Jane 京东做百亿补贴的核心是抢夺电商流量,因为当下消费水平下跌,外部拼多多、抖音等低价竞争剧烈,都让京东、淘宝等老牌电商平台的用户流量流失严重。而用户是平台的根本,因此,通过补贴来获取低客单用户才能为后续的长期发展提供动力。 基于此,京东做百亿补贴是为了抢占下沉市场(人)、吸引货源(货)、打造人气电商场域(场),也是京东顺应市场竞争,保障自
-
 2024实习记录:中国电信亿讯科技日常实习面试
2024实习记录:中国电信亿讯科技日常实习面试2023.02.08 今天早上面试了中国电信亿讯科技公司的Java开发岗,面试官人挺好的,上来就是一顿闲聊,然后问我考研考了哪些科目,我说了OS和DS,然后直接从这两门开问,考研的时候倒背如流,现在基本没印象了,就勉勉强强瞎答了一下,在这里记录一下,附上整理的答案 面试题: 1.内存调度算法还记得哪些? 最佳页面置换算法:就是计算内存在未来最长一段时间内不会使用到的,但在实际中无法实现 先进先出置
-
任何关于regex搜索数亿文本(存储在MongoDB中)的建议
null 搜索的要求如下: 应该能够为(任何)单个或多个字符使用占位符/通配符(如、或); 应该能够指示短语在搜索文本中的位置(开头、任意位置、结尾:、、); 结果应完全匹配。 我已经试过了: null 如果在MongoDB中拥有所有功能并使用它的内置功能,那就太好了; 或使用solr,因为它将用于其他搜索功能,它是可靠的、可伸缩的,等等; 或使用lucene,与solr相同,但必须自己处理可伸缩
-
 亿纬锂能(数据工程师方向)一面面经+二面面经
亿纬锂能(数据工程师方向)一面面经+二面面经更新一下,二面后五天样子发offer啦。 但手上还有一个国企省总部的offer,华子在等待二面…目前还没有决定好。 ——————— 滴滴滴,下午四点面完的二面。由于面试答得不是很好,所以调整情绪了好久,才来更新二面面经,愿攒攒好运! 二面是技术总监负责面试,第一环节是自我介绍。 然后第二环节是英文自我介绍,由于面试官要求剪短一些。我就直接介绍了学历信息就结束了(现在想想好蠢,应该多说一些的,没有很
-
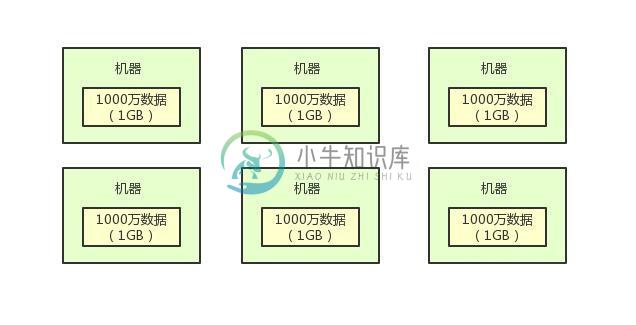 如何设计一个分布式系统去分析上亿条数据?
如何设计一个分布式系统去分析上亿条数据?主要内容:一、从一个新闻门户网站案例引入,二、推算一下你需要分析多少条数据?,三、黄金搭档:分布式存储+分布式计算这篇文章聊一个话题:什么是分布式计算系统? 一、从一个新闻门户网站案例引入 现在很多同学经常会看到一些名词,比如分布式服务框架,分布式系统,分布式存储系统,分布式消息系统。 但是有些经验尚浅的同学,可能都很容易被这些名词给搞晕。所以这篇文章就对“分布式计算系统”这个概念做一个科普类的分析。 如果你要理解啥是分布式计算,就必须先得理解啥是分布式存储,现在我们从一个小例子来引入。 比如说
-
 东莞Java开发面试汇总以及避坑指南三(亿用网络)
东莞Java开发面试汇总以及避坑指南三(亿用网络)笔试题 没有笔试 技术面 项目中分布式事务是用什么? mysql引擎类型?区别? 事务什么时候会失效? 进程怎么确保安全? spring注解有哪些? autowire 和 resours注解有什么不同? 大概问了很多很多,项目那些也问了。两个人问,一个所谓的技术主管(特别年轻的人,感觉像刚出来的大学生) 直接拒绝,一进门就感觉很不对劲,一群小年轻像极了大学上实训课室那种感觉,很小很乱,也没水喝等面
-
写一个程序从10亿个数组中找出100个最大的数
我只能给出一个强力解决方案,即以O(nlogn)时间复杂度对数组进行排序,并取最后100个数字。 面试官在寻找一个更好的时间复杂性,我尝试了几个其他的解决方案,但都没能回答他。有更好的时间复杂性解决方案吗?
-
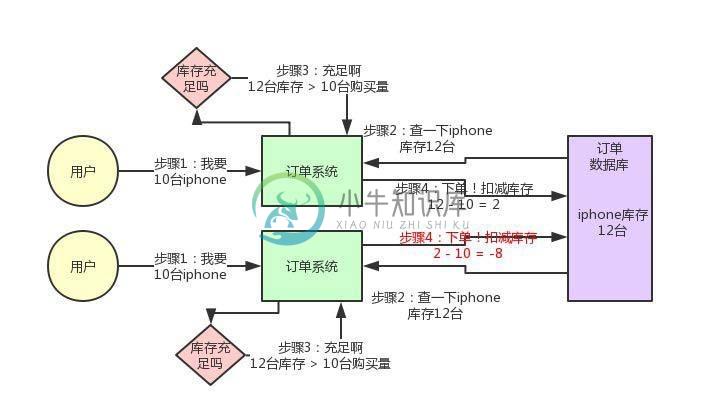 一文带你了解亿级流量下的分布式锁优化方案!
一文带你了解亿级流量下的分布式锁优化方案!主要内容:背景引入,库存超卖现象是怎么产生的?,用分布式锁如何解决库存超卖问题?,如何对分布式锁进行高并发优化?今天给大家聊一个有意思的话题:每秒上千订单场景下,如何对分布式锁的并发能力进行优化? 背景引入 首先,我们一起来看看这个问题的背景? 前段时间有个朋友在外面面试,然后有一天找我聊说:有一个国内不错的电商公司,面试官给他出了一个场景题: 假如下单时,用分布式锁来防止库存超卖,但是是每秒上千订单的高并发场景,如何对分布式锁进行高并发优化来应对这个场景? 他说他当时没答上来,因为没做过没什么
-
性能优化 - 前端如何绘制能容纳亿级别的折线图?
前端如何绘制能容纳亿级别的折线图? 项目需要绘制一个折线图,这个折线图要容纳亿级数据量,并且是实时更新的,就是这个统计图一直在绘画,每秒都在更新,然后并且能支持查看很久之前的统计图,比如说我点到之前的某个点,这个点就会放大,以前的数据不删除。 已经使用的方式是highcharts,引入, 实时更新是使用 数据是批量过来的,通过websocked, highcharts好像没有addPoints这种