《亿联》专题
-
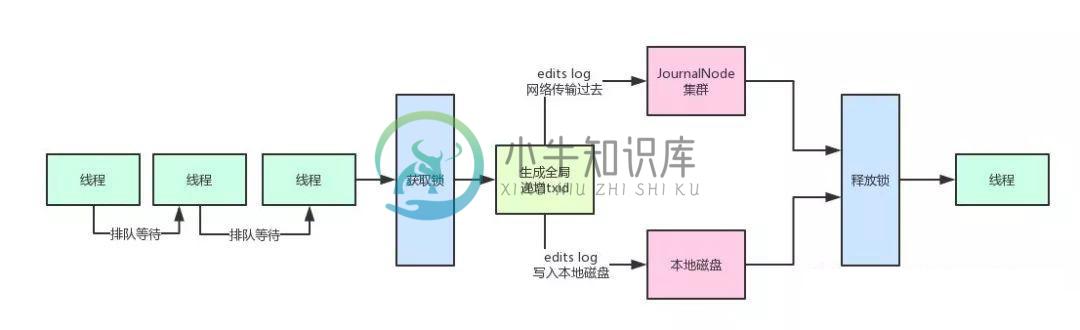 放几十亿数据的系统还能抗每秒上万并发,牛不牛?
放几十亿数据的系统还能抗每秒上万并发,牛不牛?主要内容:一、写在前面,二、问题源起,三、HDFS优雅的解决方案,(1)分段加锁机制 + 内存双缓冲机制,(2)多线程并发吞吐量的百倍优化,(3)缓冲数据批量刷磁盘 + 网络的优化,四、总结一、写在前面 上篇文章我们已经初步给大家解释了Hadoop HDFS的整体架构原理,相信大家都有了一定的认识和了解。 如果没看过上篇文章的同学可以看一下:《兄弟们给我10分钟,带你了解一下大数据技术的入门原理和架构设计!》这篇文章。 本文我们来看看,如果大量客户端对NameNode发起高并发(比如每秒上千次)
-
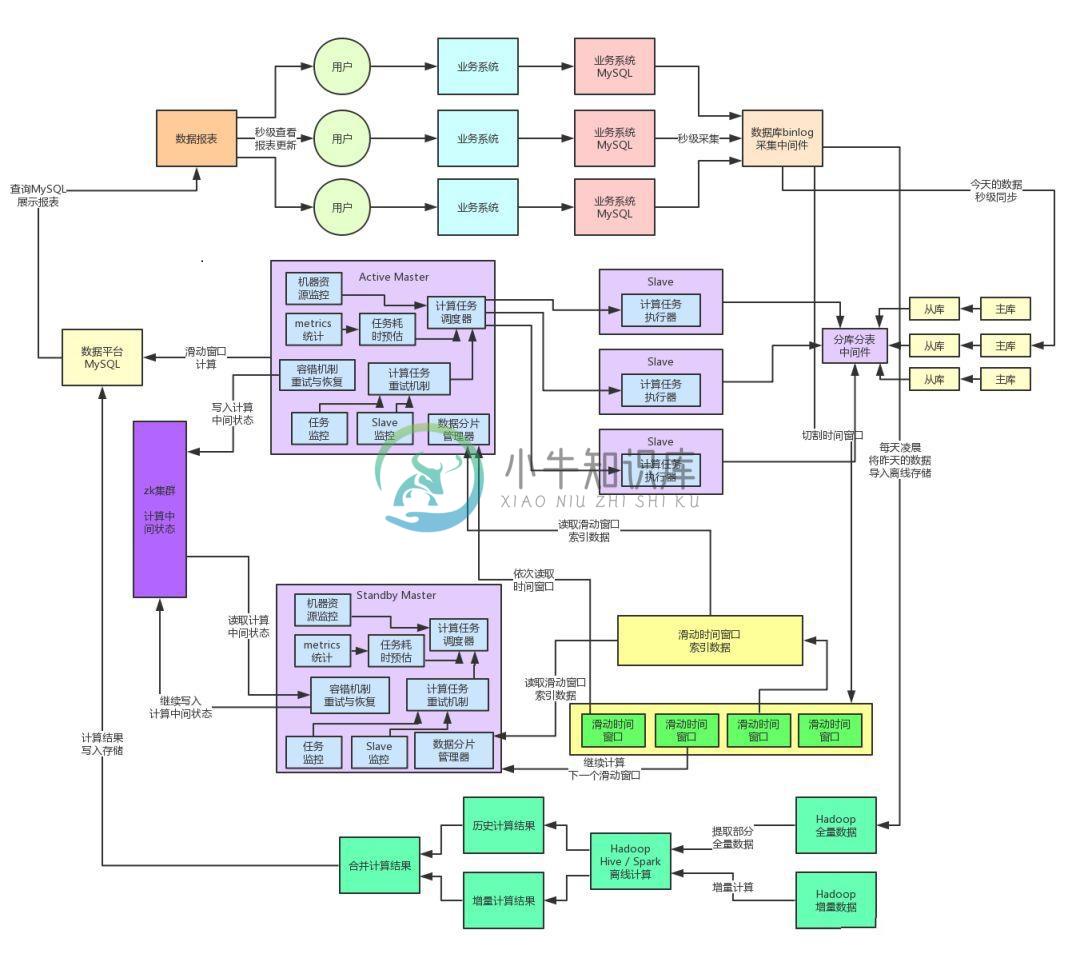 在不加机器情况下,如何抗住每天百亿级高并发流量?
在不加机器情况下,如何抗住每天百亿级高并发流量?主要内容:一、往期回顾,二、百亿流量的高并发技术挑战,三、计算与存储分离的架构,四、自研纯内存SQL计算引擎,五、MQ削峰以及流量控制,六、数据的动静分离架构,七、阶段性总结一、往期回顾 上篇《亿流量大考(1):开发一套高容错分布式系统》,主要聊了一下将单块系统重构为分布式系统,以此来避免单台机器的负载过高。同时引申出来了弹性资源调度、分布式容错机制等相关的东西。 这篇文章我们继续来聊聊这个系统后续的重构演进过程,先来看下目前的系统架构图,一起来回顾一下。 二、百亿流量的高并发技术挑战 上篇文章
-
上千万或上亿的数据,统计其出现次数最多的前N个数据?
本文向大家介绍上千万或上亿的数据,统计其出现次数最多的前N个数据?相关面试题,主要包含被问及上千万或上亿的数据,统计其出现次数最多的前N个数据?时的应答技巧和注意事项,需要的朋友参考一下 做法相同,先hash到小文件,然后hashmap计数比较
-
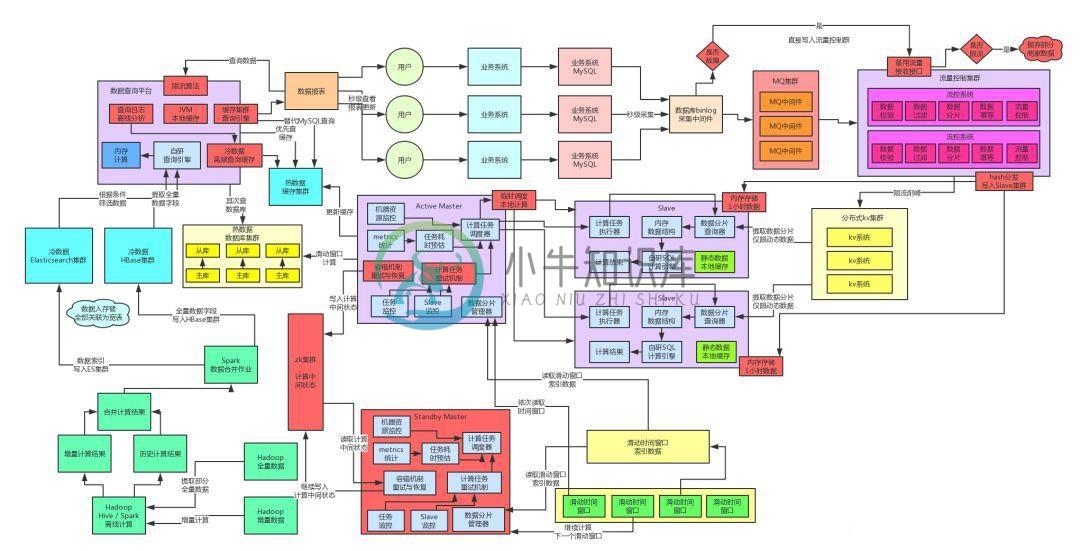 阿里面试题:如果每天有百亿流量,你如何保证数据一致性?
阿里面试题:如果每天有百亿流量,你如何保证数据一致性?主要内容:一、前情提示,二、什么是数据一致性?,三、一个数据计算链路的梳理,四、数据计算链路的bug,五、电商库存数据的不一致问题,六、大型系统的数据不一致排查有多困难一、前情提示 这篇文章,咱们继续来聊聊之前的亿级流量架构的演进,之前对这个系列的文章已经更新到了可扩展架构的设计,如果有不太清楚的同学,建议一定先回看一下之前的文章: 亿流量大考(1):开发一套高容错分布式系统 亿流量大考(2):不加机器,如何抗住每天百亿级高并发流量? 亿流量大考(3):百亿流量全链路99.99%高可用架构最佳实
-
1.2.3 es 在数据量很大的情况下(数十亿级别)如何提高查询效率啊?
面试题 es 在数据量很大的情况下(数十亿级别)如何提高查询效率啊? 面试官心理分析 这个问题是肯定要问的,说白了,就是看你有没有实际干过 es,因为啥?其实 es 性能并没有你想象中那么好的。很多时候数据量大了,特别是有几亿条数据的时候,可能你会懵逼的发现,跑个搜索怎么一下 5~10s,坑爹了。第一次搜索的时候,是 5~10s,后面反而就快了,可能就几百毫秒。 你就很懵,每个用户第一次访问都会比
-
使用 Jmeter 测试具有 1 亿条具有相同列标题的多个 csv 的记录的 API 的合适方法
我正在使用具有相同标头的多个CSV文件使用JMeter进行rest API测试。要请求的查询参数是30列CSV文件中的5列。每个CSV文件有接近100万行。 使用CSV数据集配置和__CSVRead函数处理具有相同头的多个CSV文件的最佳方法是什么? 我正试图在下面几行提出一种方法。 < li >线程组= 1000(并发,非同时) < li >循环计数= 10000 < li >对于目录中的每个文
-
借助以下数据,确定投资的好坏。水泥制造业每年生产160亿吨,其中一半出口。他们想提高能力b
本文向大家介绍借助以下数据,确定投资的好坏。水泥制造业每年生产160亿吨,其中一半出口。他们想提高能力b,包括了借助以下数据,确定投资的好坏。水泥制造业每年生产160亿吨,其中一半出口。他们想提高能力b的使用技巧和注意事项,需要的朋友参考一下 解 解决方案如下- 现金流量增量 营业额 当前 建议的 增量=提议–销售=> 2280 – 1600 => 680 变动成本=>(11 * 20)+(12
-
给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,找出a,b文件中相同的url?
本文向大家介绍给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,找出a,b文件中相同的url?相关面试题,主要包含被问及给定a、b两个文件,各存放50亿个url,每个url各占64字节,内存限制是4G,找出a,b文件中相同的url?时的应答技巧和注意事项,需要的朋友参考一下 这种找相同数据的步骤: 由于单文件总量为5G*64=320G,无法一次读入内存,同样将a文件
-
列举一个你觉得互联网中存在价格歧视的产品,并从开发者与用户的角度来分析这种歧视是否合理。
本文向大家介绍列举一个你觉得互联网中存在价格歧视的产品,并从开发者与用户的角度来分析这种歧视是否合理。相关面试题,主要包含被问及列举一个你觉得互联网中存在价格歧视的产品,并从开发者与用户的角度来分析这种歧视是否合理。时的应答技巧和注意事项,需要的朋友参考一下 举例:携程会就同一产品对不同画像的用户提供不同面额的优惠券,从而导致不同用户购买同一产品所支付的实际价格有差异。 开发者角度:合理。不同画像
-
MySQL返回联接表的第一行
问题内容: 我有两个表(“国家/地区”和“鸭子”),其中“国家/地区”表包含世界上每个国家/地区,并且“鸭子”表中有一个鸭子列表,其中有一个country_id字段可链接到主要国家/地区。 我正在尝试获取仅包含至少一只鸭子的国家/地区列表,并从鸭子表中找到该国家内评分最高的鸭子的单个匹配记录。到目前为止,我有: 这将返回每只鸭子的列表,而不是每个国家/地区的列表。 如果有人能指出我正确的方向,我将
-
一列的SQL Server唯一联合
问题内容: 我花了点时间弄清楚我需要的SQL查询。 我有一个项目,该项目具有用户的工作室级别的用户角色,并且每个项目都有覆盖/覆盖工作室级别的角色的项目级别的角色。所有角色都是在工作室级别定义的,但是只有一些角色是在项目级别定义的(主要是与相应的工作室级别角色具有不同值的角色) g_studio_UsersInRole g_project_UsersInRole 我需要一个查询,该查询将给定项目I
-
如何使用联接定义JPA存储库查询?
问题内容: 我想通过注释@Query通过Jpa存储库进行Join查询。我有三个表。 本机查询是: 现在我有了Table Hibernate实体,所以我在ApplicationRepository中尝试过 日志说 意外的标记 有什么想法吗? 我的表实体 Application.java: Customer.java: User.java: 问题答案: 您不需要JPA中的ON子句,因为借助映射注释,J
-
如何从三向联接表查询中列出第一个值?
问题内容: 好的,我在解释问题时很糟糕,所以我只先给您引号和链接: 问题4b(靠近底部): 4b。列出所有“朱莉·安德鲁斯”电影的片名和最佳男主角。 电影(id,标题,年,分数,票数,导演) 演员(id,姓名) 演员(movieid,actorid或ord) (注意:movie.id = 演员.movieid, actor.id =演员.actorid) 我的回答(无效): 这里的问题是,它希
-
休眠多对多级联删除
问题内容: 我在我的数据库3个表:,和 学生可以有多个课程,课程可以有多个学生。和之间存在多对多关系。 我为我的项目和课程添加了3个案例。 (a)当我添加用户时,它会保存得很好, (b)当我为学生添加课程时,它将在-预期行为中再次创建新行。 (三)当我试图删除学生,则在删除适当的记录和,但它也删除其中不需要的记录。即使课程中没有任何用户,我也希望课程在那里。 下面是我的表和注释类的代码。 这是Hi
-
没有域关联的Java软件包名称的约定是什么?
问题内容: 我找不到关于SO的Q / A来回答我的 确切 问题,所以我想我将其发布并看看会回来什么。 就Java包的命名约定而言,我知道它应该是反向域名:并且我得到了关于不混合大小写,连字符,关键字等的规则。 我还阅读了Java语言规范的7.7节(唯一包名称)。据我所知,Java的规则是使用反向域来确保唯一性……如果您没有,请去获取一个: -第7.7节 因此,如果我对花钱买一个域名不感兴趣,那么我