《拼多多一面》专题
-
筛选满足一组条件的多对多关系
问题内容: 使用以下模型: 如果我要查找包含至少一篇文章的订单操作,则可以按预期工作: 但是,如果要查找订单中所有商品的订单操作,正确的方法是什么? 引发错误(我理解为什么会这样)。 问题答案: 一个简单的解决方案: 这只是一个查询,但每篇文章都有一个内部联接。对于多篇文章,Willem更巧妙的解决方案应该会表现更好。
-
多线程:多个线程与同一个表交互
面试问题 比如说,我们有一个在Employee表中有200万条记录的表,我们需要削减每个员工10%的工资(需要做一些处理),然后将其保存回collection。你怎样才能有效地做到这一点。 我问他,我们可以使用executor框架来创建多个线程,这些线程可以从表中获取值,然后我们可以处理并将其保存到列表中。 然后他问我,你将如何检查一个记录是否已经被处理,我不知道(如何做)。 甚至我也不确定我是否
-
基于多列将一行拆分为多行[重复]
我在 spark 中有一个数据帧: 此处,所有列均为字符串数据类型。 如何在多列中使用分解功能,并创建如下所示的新数据框: 在新的数据帧中,所有列都是字符串数据类型。
-
Java 字符串拼接竟然有这么多姿势(收藏版)
本文向大家介绍Java 字符串拼接竟然有这么多姿势(收藏版),包括了Java 字符串拼接竟然有这么多姿势(收藏版)的使用技巧和注意事项,需要的朋友参考一下 但扪心自问,在我做程序员的前两年内,我也不知道为啥。遇到字符串拼接就上“+”号操作符,甭管是不是在循环体内。和小菜比起来,我当时可没他这么幸运,还有一位热心的“二哥”能够分享这份价值连城的开发手册。 既然我这么热心分享,不如好人做到底,对不对?
-
从Spark读取拼花地板数据时有多少个分区
我正在使用Spark 1.6.0。以及用于读取分区拼花数据的DataFrame API。 我想知道将使用多少个分区。 以下是我的一些数据: 2182个文件 Spark似乎使用了2182个分区,因为当我执行计数时,作业被拆分为2182个任务。 这似乎得到了的证实 对吗?在所有情况下? 如果是,数据量是否过高(即我是否应该使用df重新分区来减少数据量)?
-
 多多买菜-运营管培生一面面经(3面后凉凉)
多多买菜-运营管培生一面面经(3面后凉凉)#非技术2023笔面经# 总体来说多多买菜这个面试时间跨度是比较长的,从意面到上面隔了,有半个月到20天 整体的体验感的话就是你的面试官在仓库给你面试环境很吵杂11116的工作环境 . 一面: 1.自我介绍我介绍了一下,我来自哪个大学,然后两段实习经历分别点了一下,最后就是一个感谢 2.个人经历细问 3.了解多多买菜吗(从个人使用、家人团长方向阐述、社区团购愿景) 4.社区团购的理解 5.了解生鲜
-
多对多hibernate反面被忽略
问题内容: 您好,我正在阅读hibernate文档。 http://docs.jboss.org/hibernate/annotations/3.5/reference/zh/html/entity.html 使用@ManyToMany批注在逻辑上定义了多对多关联。您还必须使用@JoinTable批注描述关联表和联接条件。如果关联是双向的,则一侧必须是所有者,而一侧必须是反向端(即,在更新关联表中
-
一对一、一对多的关联查询 ?
本文向大家介绍一对一、一对多的关联查询 ?相关面试题,主要包含被问及一对一、一对多的关联查询 ?时的应答技巧和注意事项,需要的朋友参考一下
-
ActiveAndroid多对多关系
问题内容: 我目前正在使用ActiveAndroid,并且在过去的几个小时里一直在尝试建立多对多关系,但是我还是无法正常工作。我希望你能帮助我: 我有“学生”和“课程”的模型,一个学生可以有很多课程,而一个课程有很多学生。基本上,这就是我在“ StudentCourse”模型中所拥有的: 现在,我要做的是使用以下代码获取“课程X中的所有学生”: 但是我收到以下错误: java.lang.Class
-
多对多查询jpql
问题内容: 我遇到了麻烦。 有一个实体发行人与与实体镇的ManyToMany关系有关: 那么实体镇也与地区有关 现在,我必须过滤(使用jpql)一个区域中的所有分发服务器。我能怎么做? 问题答案: 请参阅:https://en.wikibooks.org/wiki/Java_Persistence/JPQL
-
MySQL多对多选择
问题内容: 仍在学习MySQL的绳索,我试图找出如何进行涉及多对多的特定选择。如果表名太通用,我深表歉意,我只是在做一些自制的练习。我尽力成为一名自学者。 我有3个表,其中一个是链接表。如何编写 “显示哪些用户同时拥有HTC和Samsung手机” (他们拥有2部手机)的语句。我猜答案在WHERE语句中,但我不知道该怎么写。 问题答案: 关键是在GROUP BY / HAVING中使用COUNT个D
-
Spring,Hibernate-多对多-LazyInitializationException
问题内容: 我有2个模型。 用户: 汽车: 贴图: 用户: 汽车: HomePageController: 但是当我执行line时: 以下堆栈跟踪出现错误: 我是否构造了错误的映射文件,尤其是多对多关系? 问题答案: 默认情况下,Hibernate将延迟加载集合。换句话说,除非绝对需要,否则它不会进入数据库来检索汽车列表。这意味着从您的dao层返回的对象将不会初始化汽车列表,除非您尝试访问它。当您
-
mysql-多少列太多?
问题内容: 我正在建立一个可能有70列以上的表格。我现在正在考虑将其拆分,因为每次访问表时都不需要列中的某些数据。再说一次,如果我这样做,我就不得不使用联接。 在什么时候(如果有的话)是否认为列太多? 问题答案: 一旦超过数据库支持的最大限制,就认为它太多了。 不需要每个查询都返回所有列的事实是完全正常的;这就是为什么SELECT语句可让您显式命名所需的列的原因。 通常,您的表结构应反映您的域模型
-
JPA多对多映射
主要内容:@ManyToMany 示例,程序输出结果多对多映射表示集合值关联,其中任何数量的实体可以与其他实体的集合关联。 在关系数据库中,一个实体的任何行可以被引用到另一个实体的任意数量的行。 完整的项目目录结构如下所示 - @ManyToMany 示例 在这个例子中,我们将创建学生和图书馆之间的多对多关系,以便可以为任何数量的学生发放任何类型的书籍。 这个例子包含以下步骤 - 第1步: 在包中创建一个实体类,包含学生ID(s_id)和学生姓名(
-
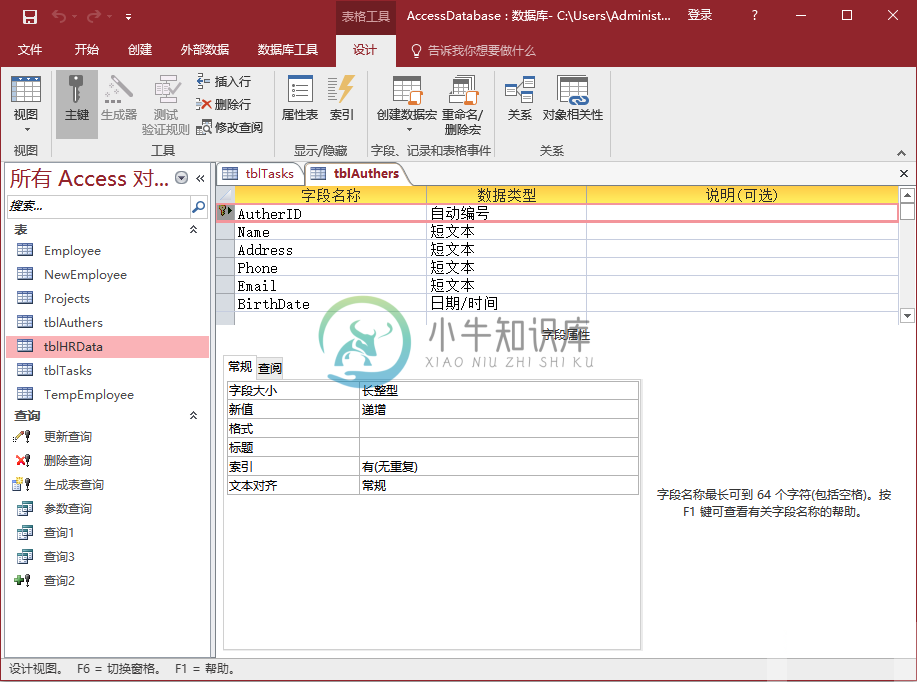 Access多对多关系
Access多对多关系在本章中,让我们了解和学习多对多的关系。要表示多对多关系,必须创建第三个表(通常称为联接表),将多对多关系分解为两个一对多关系。 为此,我们还需要添加一个联接表。 下面先添加一个表。表的定义如下所示 - 现在创建一个多对多的关系。假设有多个作者在多个项目上工作,反之亦然。 如您所知,我们在中有一个字段,所以为它创建了一个表。但现在不再需要这个字段了。 选择字段,然后按下删除 按钮,将看到以下消息。