《用户运营的核心技能是什么》专题
-
3. 核心组件 - 3.1 etcd
Etcd是CoreOS基于Raft开发的分布式key-value存储,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等)。 Etcd主要功能 基本的key-value存储 监听机制 key的过期及续约机制,用于监控和服务发现 原子CAS和CAD,用于分布式锁和leader选举 Etcd基于RAFT的一致性 选举方法 1) 初始启动时,节点处于follower状态并被设定一个elec
-
5.2、IO核心子系统
1、IO层次结构 IO实现普遍采用了层次式的结构。其基本思想与计算机网络中的层次结构相同:将系统IO的功能组织成一系列的层次,每一层完成整个系统功能的一个子集,其实现依赖于下层完成更原始的功能,并屏蔽这些功能的实现细节,从而为上层提供各种服务。 一个比较合理的层次划分为四个层次的系统结构,各层次及其功能如下: 1)用户层IO软件:实现与用户交互的接口,用户可直接调用在用户层提供的、与IO操作有关的
-
诸葛io核心概念
会话 定义:会话即session,即用户的一次打开和启动。诸葛io认为,会话是行为数据记录的必要维度,会话的准确性直接影响对用户行为的解读以及部分关键统计指标的准确性 判定: 从「打开产品」到「关闭产品」视为一次会话; 对于iOS用户,屏熄、home键切到后台、杀掉进程即判断为会话结束;对于Android用户,当应用重新进入活跃状态与上次活跃状态相隔30秒以上时,会计为一次新的会话; 对于web、
-
Libra 协议: 核心概念
The Libra Blockchain is a cryptographically authenticated distributed database, and it is based on the Libra protocol. This document briefly describes the key concepts of the Libra protocol. For a det
-
EmberJS - 核心概念( Core Concepts)
Ember.js有以下核心概念 - Router Templates Models Components 路由器和路由处理程序 该URL通过在地址栏中输入URL来加载应用程序,用户将单击该应用程序中的链接。 Ember使用路由器将URL映射到路由处理程序。 路由器将现有URL与路由匹配,然后用于加载数据,显示模板和设置应用程序状态。 Route处理程序执行以下操作 - 它提供了模板。 它定义了模板
-
创建核心系统类
每次CodeIgniter运行时都有很多基础类作为核心框架的一部分被自动初始化.但你也可以使用经过你修改的类来替换甚至扩展这些原始的核心系统类. 大多数用户一般不会有这种需求,但对于那些想较大幅度的改变CodeIgniter的人来说,我们依然提供了替换和扩展核心系统类的选择. 注意: 改变系统核心类会产生很大影响,所以在你做之前必须清楚地知道自己正在做什么. 系统类清单 以下是系统核心文件的清单
-
创建核心系统类
每次 CodeIgniter 运行时,都有一些基础类伴随着核心框架自动的被初始化。但你也可以使用你自己类来替代这些核心类或者扩展这些核心类。 大多数用户一般不会有这种需求,但对于那些想较大幅度的改变 CodeIgniter 的人来说,我们依然提供了替换和扩展核心类的选择。 注解 改变系统核心类会产生很大影响,所以在你做之前必须清楚地知道自己正在做什么。 系统类清单 以下是系统核心文件的清单,它们在
-
Webpack 五大核心概念
一、Entry 入口(Entry)指示Webpack以哪个文件为入口起点开始打包,分析构建内部依赖图。 二、Output 输出(Output)指示Webpack打包后的资源bundles输出到哪里去,以及如何命名。 三、Loader Loaderi Webpack能够去处理那些非Javascript文件(webpack 自身只理解JavaScript) 四、Plugins 插件(Plugins)可
-
绘图: matplotlib核心剖析
matplotlib是基于Python语言的开源项目,旨在为Python提供一个数据绘图包。我将在这篇文章中介绍matplotlib API的核心对象,并介绍如何使用这些对象来实现绘图。实际上,matplotlib的对象体系严谨而有趣,为使用者提供了巨大的发挥空间。用户在熟悉了核心对象之后,可以轻易的定制图像。matplotlib的对象体系也是计算机图形学的一个优秀范例。即使你不是Python程序
-
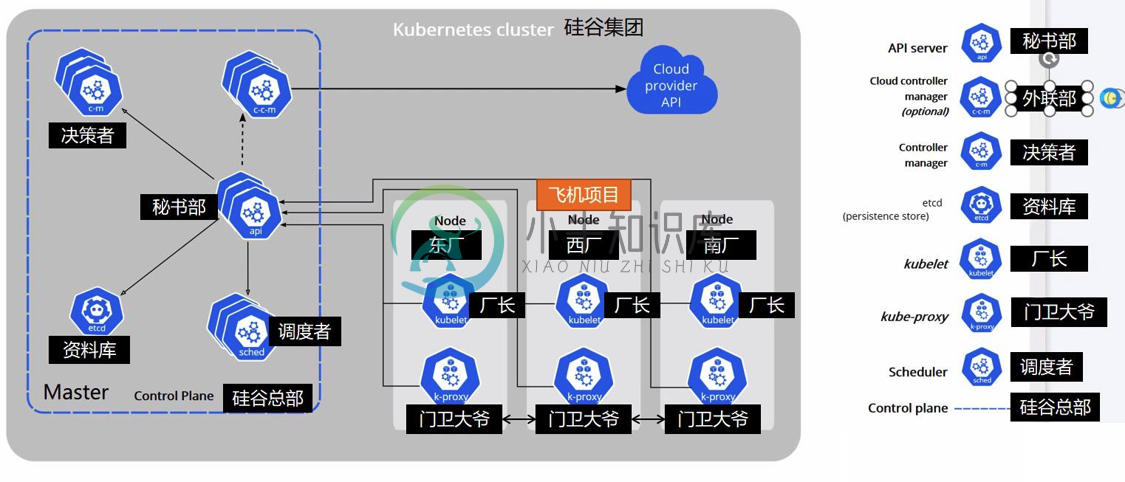 Kubernetes 核心资源原理
Kubernetes 核心资源原理主要内容:1.kubernetes 架构,2.从创建 deployment 开始,3.Pod,3.容器编排,4.水平扩缩容,5.更新/回滚,6.滚动更新,7.kubernetes 中的网络,8.微服务—service,9.kubernetes 中的服务发现与网络调用kubernetes 已经成为容器编排领域的王者,它是基于容器的集群编排引擎,具备扩展集群、滚动升级回滚、弹性伸缩、自动治愈、服务发现等多种特性能力。 1.kubernetes 架构 从宏观上来看 kubernetes 的整体架构,包
-
魅族 MX 核心代码
虽然魅族自M9以来就一直在使用Android系统,却一直没有根据协议开源所使用的Linux核心。如今距离MX已经上市接近一年,魅族在近日终于将旗 下手机的核心源代码上传至Github,支持的机型包括M030、M031和M032。 由于Linux核心采用的是GPL协议,因此根据规定是必须要开源的,魅族此举算是完成了一件长久以来必须要完成的事情。虽然M9的核心暂时没有包含在 内,但是根据魅族员工的说法,M9的核心将于近期上传。
-
如何获取.NET核心Web API中的当前用户(来自JWT令牌)
经过很多挣扎(以及大量的指导,指南等),我设法设置了一个小型的.NET Core REST Web API,当存储的用户名和密码有效时,使用身份验证控制器颁发JWT令牌。 令牌将用户ID存储为子声明。 我还设法设置了Web API,以便在方法使用Authorize注释时验证这些标记。 现在我的问题是:我如何在我的控制器(在一个Web API中)中读取用户id(存储在主题声明中)? 这基本上是这个问
-
Java REST的正确心跳/保持活力的技术/层是什么?HTTP?TCP?编码:分块?
设置: 有时London04实际上需要超过10秒(比方说2分钟)才能执行。有时它会不优雅地崩溃。有时会发生其他(网络)问题。有时在这2分钟内,response-xml-data的各个部分被逐渐填充,以至于各个部分之间没有10秒的间隔,因此从来不会超过readTimeout,有时有10多秒的间隔,HttpClient超时... 我们可以尝试增加主端的超时,但这会很容易使侦听器池膨胀/过载(仅仅是常规
-
为什么Spark每个执行器只使用一个核心?它如何决定使用除分区数以外的核?
我在Spark UI上看到0个内核分配给executor,这是可以理解的,因为我们不再使用Spark独立集群模式。但是现在,当我在worker节点上检查top+1命令时,所有的内核都被利用了,这表明问题不在于应用程序代码,而在于spark独立模式对资源的利用。 那么,当spark有16个内核并且有足够的分区时,它是如何决定每个执行器使用一个内核的呢?我可以改变什么,以便它可以利用所有的核心? 我使
-
为什么++(后增量运算符)不能是lvalue?
代码 产出(如预期) 1.post increment运算符()在表中具有最高的优先级。因此它肯定会在赋值运算符()之前执行。根据post增量规则,变量的值只有在执行该语句之后才会增加。 参见有rvalue 3,而不是变量本身,对吗?但是如果它带来了一个具有lvalue的变量,那么5将插入其中,在语句结束后,它的值将是6。这有什么问题,为什么做不到?