《求内推同程艺龙》专题
-
 同程旅行 移动安全工程师
同程旅行 移动安全工程师0 offer,发经验攒人品。#同程旅游# 一天吃着饭看到一个微信好友请求,一看是同程的HR,约了时间,腾讯会议,半个小时,快速结束。 1. 面试官介绍部门,说成都这边安全就七个人,但是什么都在做,网络安全、安全开发、移动安全。 2. 自我介绍 3. 问项目 4. 做了什么?有没有碰到什么问题? 5. suricata实际使用场景,suricata的优化 6. 简单介绍clcikhouse和ela
-
 为什么我的“同意管理权限”请求要求所有权限?
为什么我的“同意管理权限”请求要求所有权限?我将只同意graph API中的特定管理权限。 但它请求所有租户权限。 当前逻辑为 如何请求对特定权限的同意?
-
GitHub工作流:每个不同的git操作(推送主控、推送标签…)对应一个作业
我想设置我的工作流程来执行以下操作: 在任何事件上(拉请求,在任何分支上推送) 结账码 构建项目 运行测试 为其他作业上传工件 从以前的工作下载工件 推送页面 从以前的工作下载工件 创建发行版 将工件上传到发行版 在我的中,指令适用于所有作业,因此在我的情况下不起作用。另一方面,仅在同一工作流中工作。 实现所述工作流程的正确方法是什么?
-
Java使用相同资源的非同步线程
我必须制作一个非常简化的联合银行账户程序(在这个例子中,有3个用户都可以访问银行账户资源),但是我在正确使用Java线程时遇到了问题。 以下是该程序的工作原理。有些“用户”都可以访问一个具有任意设置的初始余额的联合银行账户(我使用了5000)。他们每个人都可以在一次运行的程序中提取或存款三次(无论是提取还是存款,每次都是随机生成的)。 他们存款或取款的金额也是随机生成的,唯一的规则是金额永远不能超
-
在spring测试中要求范围内的bean
问题内容: 我想在我的应用程序中使用请求范围的bean。我使用JUnit4进行测试。如果我尝试在这样的测试中创建一个: 使用以下bean定义: 我得到: 但是我注意到他使用了AbstractDependencyInjectionSpringContextTests,它似乎在Spring 3.0中已被弃用。我目前使用Spring 2.5,但认为切换此方法以使用Docs建议的使用AbstractJUn
-
Ruby、PHP、Shell实现求50以内的素数
本文向大家介绍Ruby、PHP、Shell实现求50以内的素数,包括了Ruby、PHP、Shell实现求50以内的素数的使用技巧和注意事项,需要的朋友参考一下 ruby求50之内的素数的方法,感觉对比PHP和SHELL方法是最简单的,但SHELL中可以利用factor命令,而PHP中没有求素数的对应函数的,需要自己设计算法,三种方式大家对比学习下,应该还有更优更简单的方法的。 PHP代码如下: S
-
求和两个Collections.Counter()对象的内容[重复]
-
Ajax Post内容类型:Application/Json阻止请求
下面是我的Ajax请求: 如果我没有精确的内容类型,我就无法再看到Firebug的请求。相反,当我添加内容类型时,我可以看到POST请求(由于我的URL是false而出现错误),但在我的头中,内容类型默认是URL编码的表单。 我想要的是通过JSON数据发送表单的详细信息。谢谢你的帮助
-
在请求范围内存储和检索值
我制作了一个用于注册成员的jsp页面,在注册时,如果用户忘记填写表单中的任何字段,另一个页面会显示一条错误消息。 为了实现这一点,我使用了3个servlet,第一个servlet从jsp页面获取值,并传递到第二个servlet,后者检查是否有任何字段为空,如果是,它将返回一条消息给第一个servlet,然后将消息传递给第三个servlet,以向用户显示错误消息。 我的问题是消息没有从第一个serv
-
如何从REST-ASTUED请求XML内容类型
我有一个支持json和XML的REST api。我想测试XML方面,但自从升级到2.4.0版本后,我得到了一个错误: 预期的内容类型“xml”与实际的内容类型“application/json”不匹配。
-
如何处理包含html内容的请求?
我有一个请求我的服务器,响应是一个类型,如下所示: 我通过如下方式设置改装请求: 并准备如下请求: 但是,始终无法获得响应的代码,并且该代码是”。 如何获得html响应? 非常感谢。
-
用flurl为JSON请求指定内容语言?
我想发送一个请求,使用Flurl指定内容头。我已经成功地设置了内容类型(),没有任何问题: 正确返回: 所使用的API是一个模拟。我知道使用会自动设置头,但是,对于我的用例,它将被设置为,因此需要显式指定。 我做错了什么?关于内容头,我有什么不明白的吗? 与在添加到请求时有什么不同?
-
Scala/Play:javax.xml.soap请求标题内容类型问题
在我的Scala/Play应用程序中,我有一个对SOAP API的简单调用: 输出我设置的右侧标题: 但是我调用的远程SOAP API以响应: 我已经检查了用wireshark发送的请求,事实上,标头是错误的: 在这种情况下,为什么我设置的内容类型被忽略?我该如何修复它? 更新:我想我已经了解了一些事情: SOAPPart对象是MIME部件,具有MIME头内容Id、内容位置和内容类型。因为内容类型
-
JAX-WS调度请求设置内容类型
我试图使用服务/调度机制发布一个JAX-RS资源。问题是传出请求的内容类型被锁定为。我看不出有什么方法可以将其更改为其他类型,例如。 RESTful webservice只使用和。这是我使用的代码: 接受标头被修改为zoo标头,foo标头添加了值,但Content-Type保持不变。我想我可以使用一个过滤器,并根据一些条件修改,甚至基于foo头,但这似乎违反直觉。 以下是请求的所有标题: 感谢您的
-
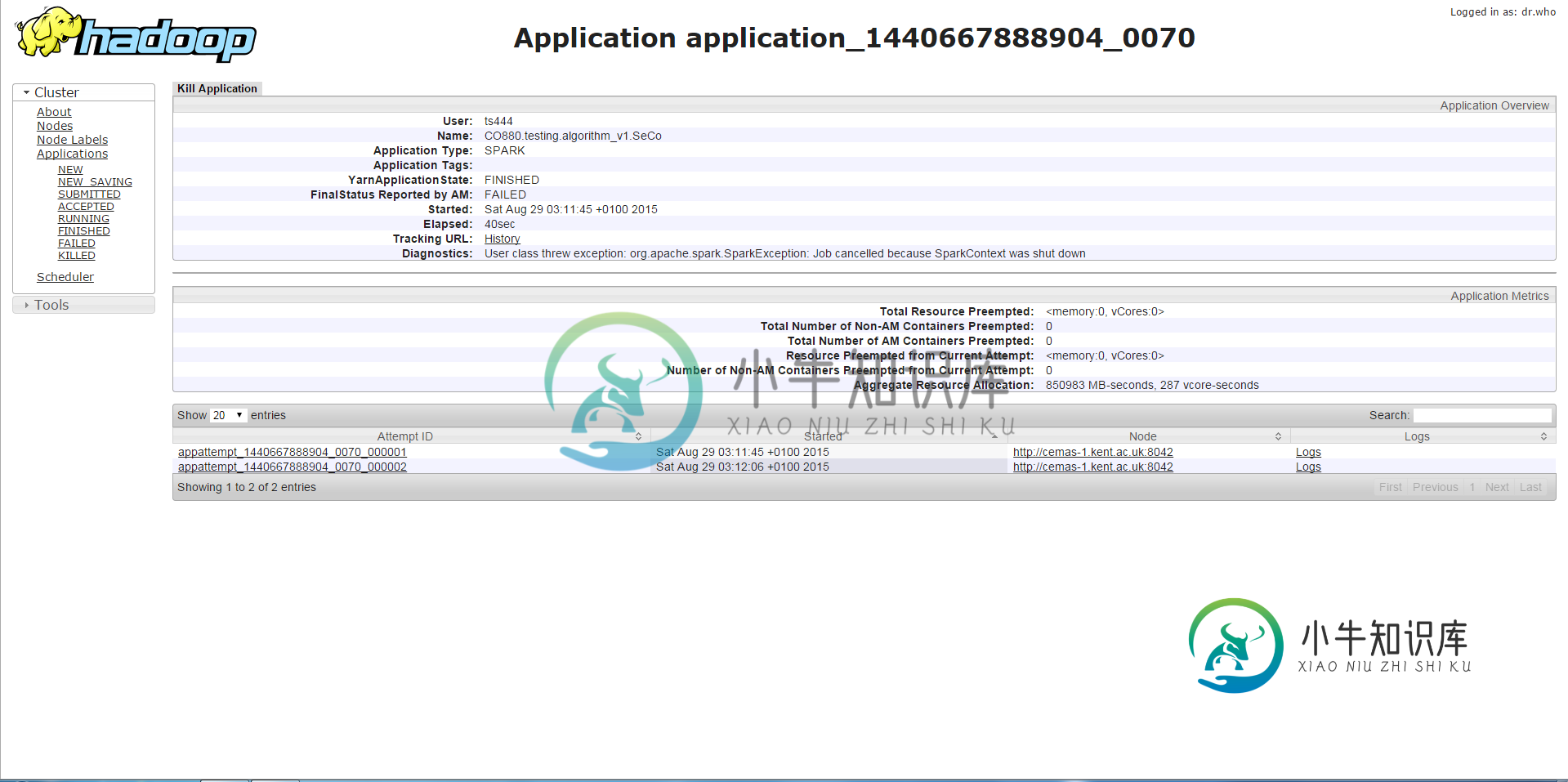 Apache Spark驱动程序内存、执行程序内存、驱动程序内存开销和执行程序内存开销对作业成功运行的影响
Apache Spark驱动程序内存、执行程序内存、驱动程序内存开销和执行程序内存开销对作业成功运行的影响我正在对YARN上的Spark作业进行一些内存调优,我注意到不同的设置会给出不同的结果,并影响Spark作业运行的结果。但是,我很困惑,不明白为什么会这样,如果有人能给我一些指导和解释,我会很感激。 我将提供一些背景资料和张贴我的问题和描述案例,我已经经历了他们在下面。 我的环境设置如下: 存储器20G,每个节点20个vCore(共3个节点) Hadoop 2.6.0 火花1.4.0 我的代码对R