《职能管理面试记录》专题
-
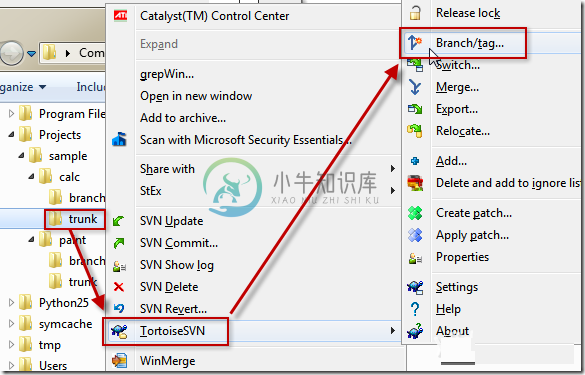 TortoiseSVN-分支管理
TortoiseSVN-分支管理主要内容:一、分支与合并的概念,二、 SVN分支的意义,三、 如何创建分支与合并分支一、分支与合并的概念 分支:版本控制系统的一个特性是能够把各种修改分离出来放在开发品的一个分割线上。这条线被称为分支。分支经常被用来试验新的特性,而不会对开发有编译错误的干扰。当新的特性足够稳定之后,开发品的分支就可以混合回主分支里(主干线)。 合并:分支用来维护独立的开发支线,在一些阶段,你可能需要将分支上的修改合并到最新版本,或者将最新版本的修改合并到分支。 二、 SVN分支的意义 简单说,分
-
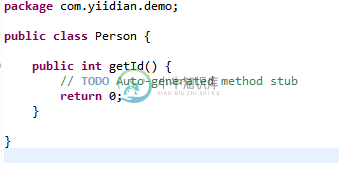 Eclipse 任务管理
Eclipse 任务管理主要内容:Eclipse 任务管理,打开任务视图,使用任务视图Eclipse 任务管理 程序员喜欢在他们的代码中放置 TODO 标记,作为需要完成的任务的提醒。Java 代码中包含 TODO 一词的注释被识别为任务并显示在标记栏和任务视图中。 通过右键单击标记栏并选择添加任务,可以使用 Eclipse 编辑器将任务与正在编辑的文件相关联。在出现的对话框中输入任务描述并从优先级下拉列表中选择一个优先级,然后单击确定按钮。 要使用 Eclipse 编辑器移除任务
-
7. 输入管理
英文原文 译者前言 这一章节比上一章节翻译的还差,最近睡眠不太好,术后恢复比较差,大家凑合看看,看不下去给指出来一下比较不好理解和绕的地方,以及错误的地方,我一定即时修改。 输入体系 Kivy能处理绝大多数的输入类型:鼠标,触摸屏,加速器,陀螺仪等等。并且针对以下平台能够处理多点触控的原生协议:Tuio, WM_Touch, MacMultitouchSupport, MT Protocol A/
-
6 工程管理
我虽不要求达不到软件工程的高度,但基本的管理还是有必要的,比如,工程文件的管理、多文档编辑、工程环境的保存与恢复。 6.1 工程文件浏览 我通常将工程相关的文档放在同个目录下,通过 NERDtree (https://github.com/scrooloose/nerdtree )插件可以查看文件列表,要打开哪个文件,光标选中后回车即可在新 buffer 中打开。 安装好 NERDtree 后,请
-
2 插件管理
既然本文主旨在于讲解如何通过插件将 vim 打造成中意的 C/C++ IDE,那么高效管理插件是首要解决的问题。 vim 自身希望通过在 .vim/ 目录中预定义子目录管理所有插件(比如,子目录 doc/ 存放插件帮助文档、plugin/ 存放通用插件脚本),vim 的各插件打包文档中通常也包含上述两个(甚至更多)子目录,用户将插件打包文档中的对应子目录拷贝至 .vim/ 目录即可完成插件的安装。
-
管理spans注释
合理 这个功能的主要论据是 api-agnostic意味着与跨度进行合作 使用注释允许用户添加到跨度api没有库依赖的跨度。这允许Sleuth将其核心api的影响改变为对用户代码的影响较小。 减少基础跨度作业的表面积。 没有这个功能,必须使用span api,它具有不正确使用的生命周期命令。通过仅显示范围,标签和日志功能,用户可以协作,而不会意外中断跨度生命周期。 与运行时生成的代码协作 使用诸如
-
1.4.3 实验管理
实验管理功能主要用来对已经创建好的实验进行管理,并且提供各个实验功能的入口,本节将会对实验管理功能进行详细介绍。 1.1. 主要功能 Figure: 实验管理 实验管理界面主要操作区 实验分为:未开始,运行中,已结束; 实验搜索功能:对实验名称进行搜索; 新增实验按钮:点击之后进入创建编程实验或者创建多链接实验流程; 实验管理的主要信息展示区 实验名称以及创建时间,未开始与已经结束的实验支持删除;
-
1.3.7.5 应用管理
基本应用管理功能,包括应用的创建,编辑以及删除,SDK使用和配置的相关问题请查看SDK接入说明。应用创建成功后,系统将会自动生成AppKey,该AppKey全局唯一是数据接入的唯一标志。 特别注意: 应用管理需要有管理员权限,具体功能请参考权限管理模块 请谨慎处理删除操作,一旦删除将会出现未知错误 1.1. 基本概念 AppKey:应用创建时,系统默认自动生成的唯一的应用标识,用于后台数据处理。
-
1.3.7.4 权限管理
用户角色定义共有4种,分别是创建者、管理员、分析师和普通用户,按权限由大到小排列。 1.1. 1. 概念理解 创建者 产品唯一创建人,需个人基本信息及邮箱或手机号码认证,最高权限,可申请更换; 管理员 产品级别,数量可设置多个,与创建者之间除更换创建者之外,权限相同; 分析师 分析功能全部权限,不具有应用、用户权限管理功能权限; 普通用户 查看被授权的看板(未开放功能); 角色权限速查表: 权限类
-
1.3.6.1 事件管理
事件管理覆盖事件的整个生命周期管理,本节将对具体内容进行介绍 新建事件:生命周期的第一步,主要功能在于埋点的需求管理 事件查看:包括事件列表,事件的筛选以及查看等基本功能 事件编辑:事件信息以及属性信息的新增,更改以及删除 事件删除:主要指回收站以及删除操作 本节的介绍顺序为事件列表,新建事件,事件详情,回收站等功能 推荐需求方将埋点提前录入系统,开发按照录入的信息进入埋点 1.1. 事件列表 事
-
1.3.6 埋点管理
这个模块提供完善的埋点管理功能,整体功能覆盖事件管理,元数据管理等核心功能。主要内容如下: 事件管理:对事件的整个生命周期进行管理,包括埋点需求,埋点统计,异常跟踪,埋点更新等等 元数据管理:对自定义事件的公共维度进行管理,包括用户属性,默认属性,预置属性的管理 1.1. 埋点管理流程如下 在HubbleData埋点管理功能辅助下,我们推荐用户按照如下流程管理埋点: 定义埋点需求:在事件管理模块新
-
1.3.5.1 推广管理
HubbleData通过UTM参数方式来跟踪推广渠道,为了能够有效跟踪渠道数据您需要完成以下步骤: 1.1. 首先在网站或者App中引入HubbleData的sdk,具体使用指南如下: JS SDK使用指南; iOS SDK使用指南; Android SDK使用指南; 1.2. 通过推广管理页面,生成推广链接将推广链接交给市场或者运营人员: Figure: 渠道新增 首先进入推广管理页面,点击新建
-
1.6 数据管理
“数据管理”用来管理“百度统计-分析云”所追踪的数据,帮助您对产品内所有的数据进行统一管理和维护。 新版分析云的数据模型由之前的“PV模型”升级为“事件模型”。支持您对产品进行更多场景下的精细化分析。在使用分析云进行分析前,您需要在“数据管理”内定义“事件”和“属性”。 事件是用户在产品上的行为,如“浏览页面”、“点击元素”等。 属性是用来描述事件的维度。在分析云中,属性不从属于具体事件,您需要从
-
状态管理 - Actions
属性是用于标识您的应用程序的操作的唯一字符串。 使用lisp-case(例如)是一个常见的惯例,但是只要在整个项目中是一致的,您可以随意使用任何写法。 示例: 为了简化操作创建,您可以创建一个工厂函数来处理应用程序中重复的部分: 由此产生的创建操作变得更加简洁和干净:
-
8.3 内存管理
一、内存连续分配 主要是指动态分区分配时所采用的几种算法。 动态分区分配又称为可变分区分配,是一种动态划分内存的分区方法。这种分区方法不预先将内存划分,而是在进程装入内存时,根据进程的大小动态地建立分区,并使分区的大小正好适合进程的需要。因此系统中分区的大小和数目是可变的。 首次适应(First Fit)算法: 空闲分区以地址递增的次序链接。分配内存时顺序查找,找到大小能满足要求的第一个空闲分区。