《面试如何更好的表现自己》专题
-
如何通过另一个面板更改CardLayout的面板
在我的程序中,我有一个基于向导的布局。由CardLayout实现。因此,有一组类扩展了JPanel。我想在每个面板上都有按钮来导航到其他面板。例如,当程序显示第一面板时,我想有一个按钮来显示第二面板。 我试图在main cardlayout panel holder中创建一个方法,以便任何其他类都可以通过该方法更改显示面板,但它不起作用,并且出现了stackoverflow错误。 这是我的课程 基
-
Kafka的基准测试——表现平平
我正在通过在EC2服务器上传输1k大小的消息,对Kafka 0.8.1.1进行基准测试。 我在两个m3上安装了zookeeper。xlarge服务器和具有以下配置: 第二,我在i2.2x大型机器上安装了一台Kafka服务器,该机器具有32Gb RAM和额外的6个SSD驱动器,其中每个磁盘都分区为mnt/a、mnt/b等 。在服务器上,我有一个代理,端口9092上有一个主题,有8个复制因子为1的分区
-
如果基础映像已更新,如何自动更新Docker容器
问题内容: 假设我有一个基于的琐碎容器。现在有一个安全更新,并在docker repo中进行了更新。 我怎么知道我的本地映像及其容器在后面运行? 是否有一些最佳实践来自动更新本地映像和容器以跟随docker repo更新,实际上,这会给您带来与在常规ubuntu机器上运行无人值守升级一样的好处。 问题答案: 一种方法是通过CI / CD系统来驱动它。构建父映像后,请使用该父映像扫描git repo
-
如果更新了基本映像,如何自动更新docker容器
假设我有一个基于< code>ubuntu:latest的小容器。现在有一个安全更新,docker repo中更新了< code>ubuntu:latest。 > 我怎么知道我的本地映像及其容器在后面运行? 是否有一些最佳实践可以自动更新本地映像和容器以遵循 docker 存储库更新,这在实践中将为您提供在传统 ubuntu 计算机上运行无人值守升级的相同细节
-
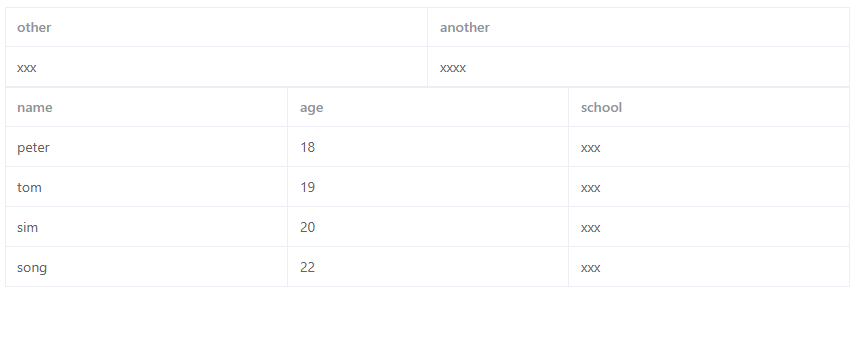 如何使用element-plus实现两个表头的表格?
如何使用element-plus实现两个表头的表格?如何使用element-plus实现两个表头的表格? 其实这应该是两个表格合在一起了,第一个表格只有一行数据。 我现在的实现是用了两个el-table来实现,还有其他实现方式吗?能只用一个el-table来实现吗? elementplus playground
-
 前端 - 有没有好的思路实现下图的表格?
前端 - 有没有好的思路实现下图的表格?如图,不采用div一个个格子画的话,有没有什么优雅的实现方式
-
如何创建自定义页面?
标题说明了一切。我想创建一个自定义的prestashop页面,但我不知道如何创建。我真正想做的是:创建一个按钮,打开一个自定义页面。我在网上找不到任何有用的东西,所以我来这里寻求帮助。有人能告诉我怎么做吗?
-
Webflux性能更好Mono
我从webflux开始,我想知道以下哪项性能更好,因为它们看起来都很像我 你能帮我弄清楚哪一个最好,为什么?谢谢
-
如何使SwiftUI列表自动滚动?
问题内容: 将内容添加到ListView时,我希望它自动向下滚动。 我正在使用SwiftUI 和a 作为控制器。新数据将追加到列表中。 当我将新数据追加到消息列表时,我希望列表向下滚动。但是,我必须手动向下滚动。 问题答案: 更新:在iOS 14中,现在有一种本机方式可以执行此操作。我正在这样做 对于iOS 13及以下版本,您可以尝试: 我发现翻转视图对我来说似乎很好。这将在底部启动ScrollV
-
如何更正我尝试的反向数组的顺序?
我当时正在做一个项目,可以看到一系列的小数被反向和横向打印出来。我已经让java代码以横向格式打印,但是当涉及到数组变量的打印时,它不是以相反的顺序,而是以随机顺序。我不确定我哪里出了错,想再多看一眼,看看我哪里出了错,谢谢。
-
如何在准备好的语句中实现类似运算符?
问题内容: ps=con.prepareStatement(“select * from REGISTER inner join ORGAN on REGISTER.PATIENTID=ORGAN.PATIENTID where ORGAN.ORGAN LIKE ?”); ps.setString(1,”’%”+o.getOrgan()+”%’“); 我在SQL Developer中执行了正常的查
-
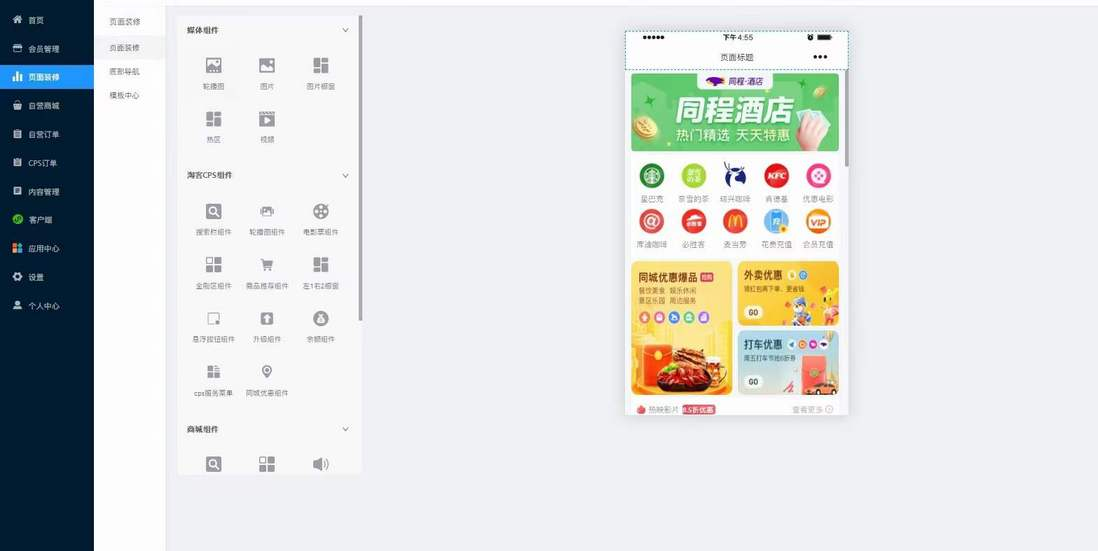 vue.js - vue如何实现页面装修的?
vue.js - vue如何实现页面装修的?vue如何实现页面装修的
-
听众有更好的做法吗?
问题内容: 说我有一个摇摆的GUI,我想听。您认为谁应该是侦听器类,谁应该负责?实施它的最佳或首选方式是什么?有什么意见吗?我通常会这样: 有没有更好的办法? 编辑: 谢谢大家的智慧和帮助。我很感激。 问题答案: 有几种执行事件侦听器的常用方法(在下面的代码中,我想到的唯一一个就是静态内部类)。下面的代码使用ActionListener,因为它很简单,但是您可以将其应用于任何侦听器。 请注意,“这
-
卷曲到WCF的更好方法
我可以通过一个CURL请求发布到我用C#从PHP编写的web服务,但是我无法正确地完成请求。无论我做什么,我能让帖子显示出来的唯一方法是我表单数据头。因此,我的PHP代码最终是这样的: 当我设定路线时: 到: PHP中没有错误,C#服务不返回错误(我在配置中设置了返回异常),函数上的断点永远不会被命中。 在C#端,我的接口和服务设置如下: 当断点命中时,我能够看到的值为: 我希望的值简单地为: 有
-
更好的蜂巢-火花连接?
我正在回顾一个旧的Spark软件,它必须并行运行许多小的查询和计数()并使用直接的hive-sql。 在过去,该软件通过在shell()上直线运行每个查询来解决“并行化查询的问题”。我不能用现代新鲜的Spark,此刻只有Spark V2.2。下面的片段说明了完整的SQL查询方法。 有一种“Spark方式”可以访问Hive并运行SQL查询,性能(略)更好,而且Spark配置的重用性更好? 没有丢失纯