《数据分析科学实习》专题
-
thinkPHP批量删除的实现方法分析
本文向大家介绍thinkPHP批量删除的实现方法分析,包括了thinkPHP批量删除的实现方法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了thinkPHP批量删除的实现方法。分享给大家供大家参考,具体如下: html: php: 原理是根据Web表单提交时可以传递数组,例如: 则传递过来的是: 更多关于thinkPHP相关内容感兴趣的读者可查看本站专题:《ThinkPHP入门教程》
-
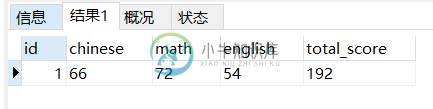 mysql5.7 生成列 generated column用法实例分析
mysql5.7 生成列 generated column用法实例分析本文向大家介绍mysql5.7 生成列 generated column用法实例分析,包括了mysql5.7 生成列 generated column用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了mysql5.7 生成列 generated column用法。分享给大家供大家参考,具体如下: 生成列的值是根据列定义中的表达式计算得出的。 mysql5.7支持两种类型的生成列:
-
C#装箱和拆箱操作实例分析
本文向大家介绍C#装箱和拆箱操作实例分析,包括了C#装箱和拆箱操作实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了C#装箱和拆箱操作。分享给大家供大家参考,具体如下: 1. C#中的装箱 C#中的装箱就是把一个值类型隐式地转换为object类型,转换过程中采用的是值的拷贝而不是引用,这从下面的例子可以看出: 2. C#中的拆箱 C#中的拆箱就是把一个对象类型显式地转换为值类型,注意
-
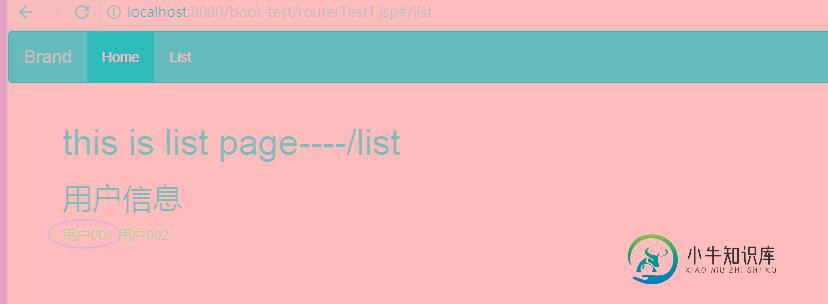 vue-router 路由传参用法实例分析
vue-router 路由传参用法实例分析本文向大家介绍vue-router 路由传参用法实例分析,包括了vue-router 路由传参用法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了vue-router 路由传参用法。分享给大家供大家参考,具体如下: 在设置路由规则时,我们可以给路径名设置一个别名,方便进行路由跳转,而不需要去记住过长的全路径。 例如: 上文中的 importFile,jsp 在上一篇路由基本用法中介
-
 javascript多物体运动实现方法分析
javascript多物体运动实现方法分析本文向大家介绍javascript多物体运动实现方法分析,包括了javascript多物体运动实现方法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了javascript多物体运动实现方法。分享给大家供大家参考,具体如下: 这里需要注意:每个运动物体的定时器作为物体的属性独立出来互不影响,属性与运动对象绑定,不能公用。 运行效果截图如下: 例子: 更多关于JavaScript运动效果相
-
PHP实现的方程求解示例分析
本文向大家介绍PHP实现的方程求解示例分析,包括了PHP实现的方程求解示例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了PHP实现的方程求解。分享给大家供大家参考,具体如下: 一、需求 1. 给出一个平均值X,反过来求出来,得到这个平均值X的三个数X1 ,X2, X3,最大值与最小值的差值要小于0.4(X1-X3都是保留1位小数的数) 2. 这三个数X1, X2, X3代表了三组数。
-
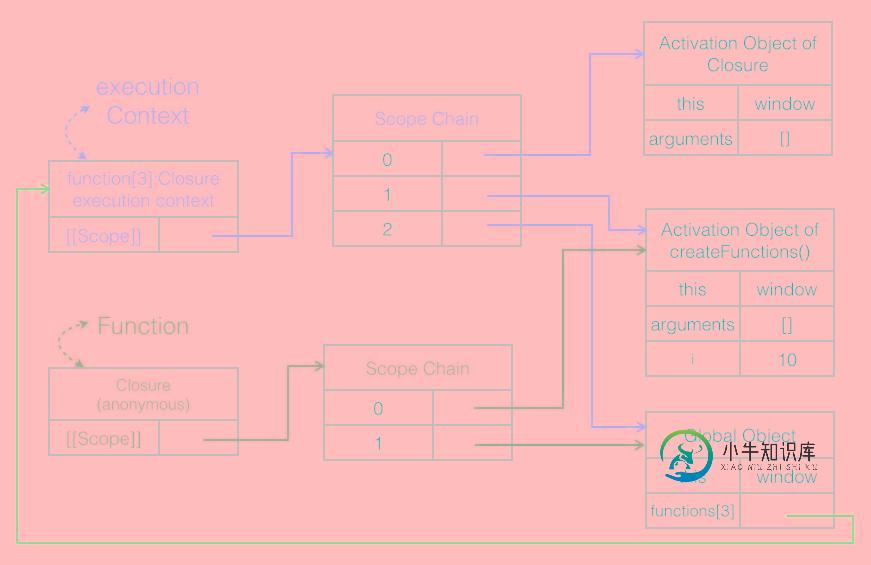 JavaScript闭包与作用域链实例分析
JavaScript闭包与作用域链实例分析本文向大家介绍JavaScript闭包与作用域链实例分析,包括了JavaScript闭包与作用域链实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JavaScript闭包与作用域链。分享给大家供大家参考,具体如下: 闭包定义 闭包指的是有权访问另一个函数作用域中的变量的函数。创建闭包的常见方式,就是在一个函数A内部创建另一个函数B,那么函数B就是一个闭包,可以访问函数A作用域中的所
-
Python sqlite3事务处理方法实例分析
本文向大家介绍Python sqlite3事务处理方法实例分析,包括了Python sqlite3事务处理方法实例分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了Python sqlite3事务处理方法。分享给大家供大家参考,具体如下: sqlite3事务总结: 在connect()中不传入 isolation_level 事务处理: 使用connection.commit() 更多关
-
通过分析日期字符串实现DateTimeParseException
我试图用Java解析一个日期字符串,但我得到了异常。 字符串如下所示: 我的方法是这样的: 我得到: java.time.format.DateTimeParseException:....在索引17中找到未分析的文本 有什么想法吗?:)
-
Wireshark 抓包实例分析 TCP 窗口及 reset
介绍 TCP最重要的机制之一是滑动窗口机制,以及用以控制TCP终端节点愿意接收的数据总量的流控机制。 TCP reset可以在几种情况下被发送。有一些是协议的正常工作过程,有一些则表明可能有问题。本节中,我们查找问题以及分析解决问题的方法。 本章讨论以上两个问题。 更多信息 TCP窗口问题: TCP零窗口,零窗口探测,零窗口违例 TCP零窗口发生于接收方在TCP头部的window字段广播接收窗口零
-
 及策实时分析平台帮助文档
及策实时分析平台帮助文档实时分析用户在微信小程序中的每一个互动行为,了解用户行为轨迹,结合用户设置的微信属性全面分析用户价值,结合场景的统计分析,提升小程序的使用效率,通过数据驱动用户的增长。
-
JS小数转换为整数的方法分析
本文向大家介绍JS小数转换为整数的方法分析,包括了JS小数转换为整数的方法分析的使用技巧和注意事项,需要的朋友参考一下 本文实例讲述了JS小数转换为整数的方法。分享给大家供大家参考,具体如下: 一、小数转为整数 floor:下退 Math.floor(12.9999) = 12 ceil:上进 Math.ceil(12.1) = 13; round: 四舍五入 Math.round(12.5) =
-
旋转整数数组的递归方法分析
在LeetCode上解决数组旋转时,我编写了一个递归算法来解决这个问题: 给定一个数组,将数组向右旋转k步,其中k为非负。 例1: 输入: Nums=[1,2,3,4,5,6,7], k=3输出:[5,6,7,1,2,3,4]说明:向右旋转1步:[7,1,2,3,4,5,6]向右旋转2步:[6,7,1,2,3,4,5]旋转3步向右:[5,6,7,1,2,3,4] 例2: 输入:nums=[-1,-
-
实例学习: 宝物猎人
实例学习: 宝物猎人 我要告诉你你现在已经拥有了全部的技能去开始制作一款游戏。什么?你不相信我?让我为你证明它!让我们来做一个简单的对象收集和躲避的敌人的游戏叫:宝藏猎人。(你能在examples文件夹中找到它。) 宝藏猎手是一个简单的完整的游戏的例子,它能让你把目前所学的所有工具都用上。用键盘的方向键可以帮助探险者找到宝藏并带它出去。六只怪物在地牢的地板上上下移动,如果它们碰到了探险者,探险者变
-
美团并行学习实践
简介 TensorFlow是Google研发的第二代人工智能学习系统,能够处理多种深度学习算法模型,以功能强大和高可扩展性而著称。TensorFlow完全开源,所以很多公司都在使用,但是美团点评在使用分布式TensorFlow训练WDL模型时,发现训练速度很慢,难以满足业务需求。 经过对TensorFlow框架和Hadoop的分析定位,发现在数据输入、集群网络和计算内存分配等层面出现性能瓶颈。主要