《打工人》专题
-
 中科曙光 人工智能研发工程师 一面面经
中科曙光 人工智能研发工程师 一面面经总体二十多分钟 1.先问了一下基础情况,然后做自我介绍 2.拷问实习项目,主要问我数据怎么做的、数据分布怎么调整,然后不知道怎么跳到文本分类的样本分布上了,问我文本分类样本不均衡怎么做;然后问我模型训练怎么做的,让我介绍一下deepspeed框架、vllm框架 3.拷问我rag的项目,问我两路召回中这两路有什么区别、rerank的作用、selfrag是什么、模型推理时延 4.拷问我的论文项目,主要
-
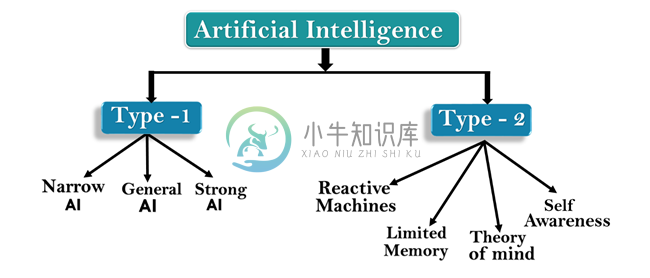 人工智能的类型
人工智能的类型主要内容:AI类型 - 1:基于功能,人工智能类型-2:基于功能人工智能可以分为多种类型,主要有两种类型的主要分类,它们基于能力并基于AI的功能。以下是解释AI类型的流程图。 AI类型 - 1:基于功能 基于能力的人工智能的类型如下 - 1. 弱AI或狭隘AI 狭隘AI是一种能够执行智能专用任务的AI。最常见和当前可用的AI是人工智能领域的狭隘AI。 狭隘的AI不能超出其领域或限制,因为它只针对一项特定任务进行培训。因此它也被称为弱AI。如果超出限制,缩小的A
-
 人工智能的应用
人工智能的应用人工智能在当今社会中具有各种应用。它已成为当今时代的必要条件,因为它可以在多个行业中以有效的方式解决复杂问题,例如医疗保健,娱乐,金融,教育等。AI使我们的日常生活更加舒适和快速。 以下是一些应用人工智能的领域: 1. AI在天文学中应用 人工智能对于解决复杂的宇宙问题非常有用。人工智能技术有助于理解宇宙,例如它的工作原理,起源等。 2. AI在医疗保健领域应用 在过去的五到十年中,人工智能对医疗
-
人工智能(AI)教程
主要内容:前提条件,面向读者,问题反馈在本教程中,讨论了各种流行的主题,如人工智能的历史,人工智能的应用,深度学习,机器学习,自然语言处理,强化学习,Q学习,智能代理,各种搜索算法等。人工智能教程提供了人工智能的介绍,可以帮助您理解人工智能背后的概念。 我们的AI教程是为初级和中级水平的读者而准备的,可以从基本概念到高级概念的完整人工智能教程。 前提条件 在学习人工智能之前,您需要具备以下基本知识,以便可以轻松地理解这些概念。 熟悉任
-
 什么是人工智能
什么是人工智能主要内容:写在前面的话,人工智能应用,人工智能发展简史,机器学习&深度学习很早就想写一门关于 Python“机器学习”的教程,不过碍于自身知识的局限性,不知如何下手。如果写的教程通篇只是探讨代码、数学知识、算法原理,这样的教程读起来必然索然无味。经过冥思苦想,终于突发灵感,可不可以写一部关于“机器学习算法”的入门教程呢?让初学者更容易理解常用的机器学习算法,从而帮助那些想要了解机器学习的人,打开通往人工智能世界的大门。 写在前面的话 机器学习是一门涉及了大量逻辑与算法的
-
蛇游戏人工智能
我正在为iOS开发一个贪吃蛇游戏:https://github.com/ScottBouloutian/Snake 我的目标是让AI以最佳方式完成蛇的游戏(让蛇填满棋盘)。 我正在使用IDA*找到一条从蛇当前位置到食物的路径。这是有效的。然而,该算法没有考虑到它将来可能需要获得更多食物的事实。因此,有时它倾向于把自己框起来。 也就是说,蛇在任何给定时间的目标都是找到食物,而它的目标应该是填满棋盘(
-
码头工人ERR_NAME_NOT_RESOLVED http ajax
问题内容: 我有3个简单的微服务(mysql,apirest,gui),我开始使用docker-compose: 在 MySQL的 和 apirest 微服务没有问题可以进行通信(我可以连接到我的数据库 apirest 使用 的MySQL 作为主机名。 但是,当我尝试使用 apirest* 作为主机名执行http请求(角度)时,我在 gui 微服务中收到以下错误: * 无法加载资源:net ::
-
TimeoutError:工人启动失败
我在jupyter笔记本电脑上的conda环境中工作。尝试使用以下过程创建客户端时 出现以下错误 回调(f)827尝试:-- 在结果(self,timeout)237中尝试:-- 提升exc信息(exc信息) 运行(自我)1068其他:- 在启动工人(自我,死亡超时,**kwargs)228个自我工人。移除(w)-- 在init(self、n_-worker、线程/worker、进程、循环、启动、
-
 闲置的火花工人
闲置的火花工人我已经配置了连接到Cassandra集群的独立spark集群,其中有1个主服务器、1个从服务器和Thrift服务器,该服务器用作Tableau应用程序的JDBC连接器。无论怎样,当我启动任何查询时,从属服务器都会出现在工作者列表中。所有工作负载都由主执行器执行。同样在Thrift web控制台中,我观察到只有一个执行器处于活动状态。 基本上,我希望火花集群的两个执行器上的分布式工作负载能够实现更高
-
动态maven人工关节
POM是否可以声明(或至少发布)包含系统属性的?我指的是实际项目的工件,而不是依赖项。 我正在使用maven构建一个scala项目,因此,为了允许为不同的scala版本发布项目,pom.xml我想声明:
-
Heroku工人没有出现
我已经将Python discord机器人部署到Heroku并启用了自动部署,但是当我转到参考资料时,我在任何地方都看不到worker,即使我已经部署了它。此外,我使用的是Github,而不是CLI (据我所知,没有文件)
-
8.3人工模型编辑
添加模型 LSV支持添加gcm,3ds,obj格式的模型,可以通过将其倒入LSV后进行一系列的操作。 首先,通过点击“添加模型”选择所需要添加的模型文件: 之后可以分别对模型的各项参数进行设置,如旋转、缩放以及其空间信息等。 模型操作 对已经加载入LSV的模型,可以通过“模型操作”对模型进行平移、升降、旋转以及缩放等操作。 并可
-
10.3人工模型编辑
添加模型 LSV支持添加gcm,3ds,obj格式的模型,可以通过将其倒入LSV后进行一系列的操作。 首先,通过点击“添加模型”选择所需要添加的模型文件: 之后可以分别对模型的各项参数进行设置,如旋转、缩放以及其空间信息等。 模型操作 对已经加载入LSV的模型,可以通过“模型操作”对模型进行平移、升降、旋转以及缩放等操作。 并可
-
设计模式:工厂与工厂方法与抽象工厂
工厂-创建对象而不向客户机公开实例化逻辑,并通过公共接口引用新创建的对象。是工厂方法的简化版本 工厂方法-定义一个创建对象的接口,但让子类决定实例化哪个类,并通过公共接口引用新创建的对象。 抽象工厂-提供了创建相关对象家族的接口,而无需显式指定它们的类。 null
-
依赖,Android库工程以及多工程设置 - 库工程
4.3 库工程 在上面的多工程配置中,:libraries:lib1 和 :libraries:lib2 可能是Java工程,并且 :app Android工程会用到他们生成的jar报。 但是,如果你想共享访问 Android API 的代码或者使用 Android 的样式资源,那么这个库工程就不能是通常的 Java 工程,而应该是 Android 库工程。 4.3.1 创建一个库工程 一个 An