《酷狗音乐》专题
-
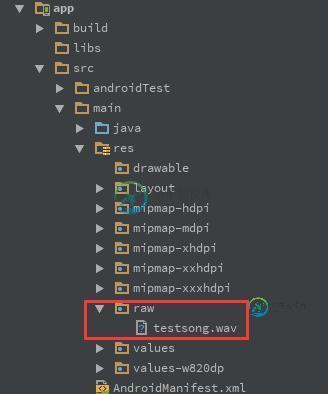 Android如何给按钮添加点击音效
Android如何给按钮添加点击音效本文向大家介绍Android如何给按钮添加点击音效,包括了Android如何给按钮添加点击音效的使用技巧和注意事项,需要的朋友参考一下 有很多制作精良的APP都自带点击音效,那么如何简单的来实现这一效果,这里需要使用到的一个概念叫做SoundPool,这个类主要用于播放一些比较小的音频文件,因为比较方便,通常用在游戏里比较多。 代码 闲话不多说,我们现在需要做一个功能,就是点击某一按钮的时候同时播
-
如何从文字中删除变音符号?
问题内容: 我正在制作瑞典语网站,瑞典语字母是å,ä和ö。 我需要创建一个用户输入的字符串,以使用PHP进行网址安全。 基本上,需要将所有字符都转换为下划线,除以下字符外: 并且所有瑞典语都应该这样转换: “å”到“ a”,“ä”到“ a”,“ö”到“ o”(只需删除上面的点)。 正如我所说,其余的应该成为下划线。 我不太擅长使用正则表达式,因此我非常感谢您的帮助! 谢谢 注意:不是URLENCO
-
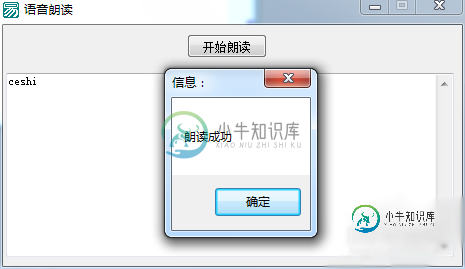 易语言做语音朗读工具方法
易语言做语音朗读工具方法本文向大家介绍易语言做语音朗读工具方法,包括了易语言做语音朗读工具方法的使用技巧和注意事项,需要的朋友参考一下 怎么自己动手做一个语音朗读的小工具呢 1、打开易语言,新建一个易语言窗口程序 2、在右边添加一个媒体播放组件和一个编辑框组件,一个按钮组件。 3、在左边模块菜单添加精易模块 4、在左边属性改下如下属性内容 5、双击启动窗口,写入如下代码 6、双击按钮组件,写入如下代码 7、点击运行,并静
-
 Android仿抖音主页效果实现代码
Android仿抖音主页效果实现代码本文向大家介绍Android仿抖音主页效果实现代码,包括了Android仿抖音主页效果实现代码的使用技巧和注意事项,需要的朋友参考一下 写在前面 各位老铁,我又来啦!既然来了,那肯定又来搞事情啦,话不多说,先上图! “抖音”都玩过吧,是不是很好玩,我反正是天天刷,作为一个非著名的Android低级攻城狮,虽然技术菜的一匹,但是也经常刷着刷着会思考:咦?这玩意是用哪个控件做的?这个效果是咋实现的啊?
-
如何在React&Redux中处理音频播放
问题内容: 我正在制作音频播放器。它具有暂停,倒带和时间搜索功能。如何以及由谁处理音频元素? 我可以把它放在商店旁边。我不能将其直接放在状态上,因为它可能会被克隆。然后,在减速器中,我可以与其进行交互。问题是,如果我需要将时间滑块与音频同步,则需要使用动作不断地轮询商店。从语义上讲,这也没有任何意义。 我可以创建一个自定义的React组件Audio,它可以完成我所说的一切。问题没有解决。如何刷新滑
-
如何将Discord Bot连接到语音频道?
我查看了所有关于将discord机器人连接到语音频道以播放声音的问题,但找不到我需要的答案。我是discord library的新手,没有解决问题的工作原理,所以当我在网站上尝试给出答案时,我经常会遇到如下错误: 我的代码如下: 这只是代码的语音部分,其他发送或事件部分正在工作。
-
NSSpeech合成器在macOS上获得Siri语音
有没有办法获取语音合成器的Siri语音<代码>语音合成器。availableVoices()没有列出它们,但可能有未记录的技巧或其他什么? 我也尝试使用,即使很难,它应该在macOS 10.14上可用,我无法让它大声读出来... 我用了一个游乐场用NSHipster的以下代码测试了这个:
-
 如何在Linux下设置录音笔时间
如何在Linux下设置录音笔时间本文向大家介绍如何在Linux下设置录音笔时间,包括了如何在Linux下设置录音笔时间的使用技巧和注意事项,需要的朋友参考一下 买了一个录音笔,效果比使用笔记本话筒录音好多了还省电。当然啦,我也曾试过使用手机录音,结果是,没能录多久就中断了(Android 就是这么不靠谱)。 我的录音需要记录较为准确的时间信息。录音笔怎么知道现在是什么时间呢?还好它没有跟风,用不着联网! 它带了一个小程序,叫「录
-
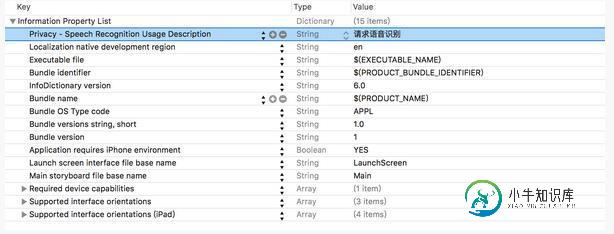 iOS10语音识别框架SpeechFramework应用详解
iOS10语音识别框架SpeechFramework应用详解本文向大家介绍iOS10语音识别框架SpeechFramework应用详解,包括了iOS10语音识别框架SpeechFramework应用详解的使用技巧和注意事项,需要的朋友参考一下 摘要: iOS10语音识别框架SpeechFramework应用 一、引言 iOS10系统是一个较有突破性的系统,其在Message,Notification等方面都开放了很多实用性的开发接口。本篇博
-
PostgreSQL重音不区分大小写的搜索
我正在寻找一种性能良好的方法来支持不区分大小写、不区分重音的搜索。到目前为止,我们使用MSSql server在这方面没有问题,在Oracle上我们必须使用OracleText,现在我们在PostgreSQL上需要它。 我找到了这篇关于它的帖子,但我们需要将它与不区分大小写结合起来。我们还需要使用索引,否则性能可能会受到影响。有没有关于大型数据库的最佳方法的实际经验?
-
不和谐机器人加入语音频道
我希望我的不和谐机器人加入语音频道。但是我遇到了一个问题,每当我想让它加入风投时,什么都不会发生——甚至没有错误。我尝试过SO/Git的其他解决方案,但没有一个适合我(下面有一个)。 编辑:解决了!问题是:没有不和。已安装py[语音]模块。解决方案:
-
录制音频并从nodejs流到客户端
我需要录制音频(我相信使用函数)并将其从nodejs服务器传输到连接的客户端浏览器。我环顾了一些例子,没有什么太明确的内容,并且采用了不同的方法。 我不能使用webrtc。它必须使用服务器向客户端发送流。但是,我可以使用(我相信这是webrtc的一部分)来录制音频并将其发送到nodejs服务器)。 是否有任何资源或示例显示这样的工作方式?
-
从Wowza流直播音频到HTML5客户端?
我有一个现有的应用程序,通过RTMP将实时音频从Flash客户端流到Wowza zerver。。。我能够将Flash客户端连接到该设备,并获得实时、低延迟的音频。 我想在PC、Android和iOS中连接一些基于HTML5的客户端,而不在客户端使用任何Flash。。。RTMP URI通常为“rtmp://myserver/live/mystream“我尝试从HTML5页面连接视频和音频标签,但没有
-
使用node.jssocket.io通过webrtc广播现场音频
我正在尝试使用webrtc和socket通过getUserMedia()获取音频。io将其发送到服务器(socket.io支持音频、视频、二进制数据),然后服务器将其广播到所有连接的客户端。问题是,当流到达连接的客户端时,它会转换为JSON对象,而不是媒体流对象。所以我无法发送音频,我也尝试了套接字。io流模块,但我认为未成功。您能帮我正确捕获音频流并将其发送到所有连接的客户端吗。 下面是发送数据
-
由于背景噪声,语音识别失败
我试图学习和使用语音识别应用程序,搜索了太长时间,找到了许多有用的信息和指南。。 最后我找到并使用了这个项目:这里 它工作得很好,直到我尝试了一些嘈杂的背景样本。。 我试图添加一个自定义语法随着听写,尝试使用自定义语法只,但仍然得到相同的结果(或更糟)... 总是相同的结果:请键入字母你听到它的工作人员... 任何信件总是产生:它的工作人员。 那么,有没有办法降低背景噪音?或者编辑WAV样本? 还