《酷狗音乐》专题
-
pygame音频播放速度
问题内容: 快速提问。 我在Linux下运行pygame只是为了播放一些音频文件。我有一些.wav文件,但在以正确的速度播放它们时遇到了问题。 我用ggogle代码搜索了一些东西,但是每个人似乎都可以使用默认参数调用init函数。其他人可以尝试运行此脚本,看看他们是否得到相同的行为吗?有人知道如何加快速度吗?还是调整每个文件的速度? 谢谢。 问题答案: 我知道了…有一个wave模块http://d
-
iOS文本到语音API
我似乎在这上面找不到任何东西。iOS7中是否有任何Siri类或API允许您进行文本到语音转换?我所要做的就是如下所示: 然后让Siri从我的应用程序中说出来。 看来我们应该有能力做到这一点,不是吗?似乎是一件微不足道的事情。
-
现场音频通过socket.io1.0
从插座上看。io网站 从1.0开始,可以来回发送任何Blob:图像、音频、视频。 我现在想知道,这是否能解决我最近想要实现的目标。 我其实是在寻找一种方法,如何直播音频流从(A-即,麦克风输入...)到所有客户连接到我的网站。像这样的事情可能吗?我一直在摆弄WebRTC(https://www.webrtc-experiment.com/)示例,但我无法为几个连接的客户端管理目标。 我的想法是关于
-
音频短裤到花车
利用JDK~6实现了一种阴基音检测算法 我想在没有javax的Android API 10上实现基音检测。声音YIN使用的样本包。API 10确实有RecordAudio,它可以通过读取(字节/短[]int pos,int size)传递字节或短字符。 什么可以优化性能?A) 将Android 1.5的RecordAudio扩展为A floats to YIN(我的首选方法),或B)从Record
-
g拖缆音频错误
我有一个g流光命令工作得很好 gst-Launst-0.10 v4l2src!视频缩放方法=0!视频/x-raw-yuv,宽度=852,高度=480,帧速率=(分数)24/1!ffmpegColorspace!x264enc pass=pass1线程=0比特率=900曲调=零一致性!flvmux名称=mux!rtmp位置='rtmp://.../live/test'demux。alsasrc!音频
-
使用soundpool获取声音
这是我的全部代码:public class FirstActivity扩展活动{/**在活动首次创建时调用。*/ }
-
如何匹配Unicode元音?
什么字符类或Unicode属性将匹配Perl中的任何Unicode元音? 错误答案:。(此处布道,洗衣清单中的第24项) perluniprops只提到朝鲜文和印度文的元音。 让我们把元音是什么的问题放在一边。是的,
-
三音素绑定过程
本文向大家介绍三音素绑定过程相关面试题,主要包含被问及三音素绑定过程时的应答技巧和注意事项,需要的朋友参考一下 http://pelhans.com/2018/01/15/deepspeech-advanced-decode-triphone/#三音子模型 将那些相似的音素归为一类(Cluster)。最常用的方法是决策树。个决策树的训练也和正常的决策树训练类似,对于每个节点,它会考虑新分支将会给训
-
回音转换字符串
在我的WPML- 例如,我有一个字符串,它具有以下内容: 背景:职业 姓名:武术家 字符串:武术家 法文译本:玛蒂奥艺术Pratiquants d'Arts Martiaux 然后我尝试使用GetText函数__()将字符串添加到短代码的返回值中: 但在页面(mysite/fr/careers/)上,英文名称武术家仍然出现。 在页面上,ICL_语言代码等于“fr”,因此页面知道它应该是法语的。 我
-
关于Android语音识别
我使用RecognizerIntent并实现RecognitionListener,并实现其所有回调方法来执行语音命令。我试着调整参数EXTRA\u SPEECH\u INPUT\u MINIMUM\u LENGTH\u MILLIS、EXTRA\u SPEECH\u INPUT\u mably\u COMPLETE\u SILENCE\u LENGTH\u MILLIS和EXTRA\u SPEE
-
Android离线语音识别
我已经使用HTK(Hidden Markov Model Tool Kit)来识别用于控制Android应用程序的特定命令,但在这种情况下,我需要将一些语音数据传递给服务器,这可能会耗费更多时间。 为了防止这种延迟,我正在考虑使用pocketsphinx通过Android应用程序在本地识别语音数据,这样我就不需要将音频传递给服务器。 如果这是一个好主意,那么从头开始学习pocketsphinx容易
-
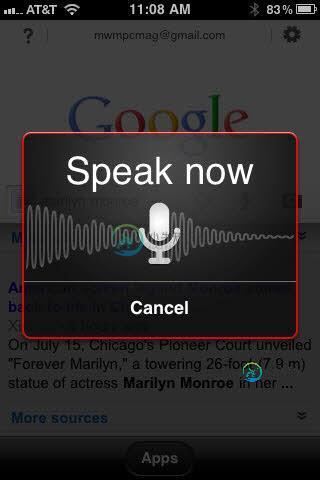 Android语音记录图表
Android语音记录图表我用MediaRecorder开发了语音记录器。我在听最后一段录音。我想要一个录音开始时像Google voice那样的语音图/图表(Google Speak Now图表)
-
 用ffmpeg解码AAC音频
用ffmpeg解码AAC音频我正在尝试解码ADTS容器中的AAC音频流,该音频流来自外部硬件H264编码器。 我分析了ADT,它告诉我我有一个2通道,44100 AAC主配置文件框架。我为ffmpeg解码器设置了额外的数据字节,并成功解码了帧?详情如下: (伪c代码) 设置解码器: 设置额外的数据字节: 然后解码帧: 解码帧: 现在,据我所知,32位原始格式的每个帧每个采样将有4个字节,每个通道将被交错(因此每4个字节是交替
-
录制用户语音android
我正在尝试制作一个应用程序,它应该首先记录用户的声音,然后从记录的文件中计算不同的东西(例如频谱)。我无法播放录制的文件(我找不到该文件-它甚至可以录制吗?)。这是我的代码: 我知道缩进不正确,因为我把代码粘贴得很糟糕……你知道为什么这段代码不能工作吗?它给出了两个错误:“应该已经设置了字幕控制器”,但我读到我不需要介意,“QCMediaPlayer媒体播放器不存在”,我读到这意味着我的平台不支持
-
添加声音java[关闭]
编辑问题以包括所需的行为、特定问题或错误以及重现问题所需的最短代码。这将有助于其他人回答这个问题。 我想在我制作的帧中添加一个声音。我在google上搜索了一下,发现Java不支持mp3,所以我把磁盘中的一首歌转换成了wav文件。导入sun.audio.*后和java.io.*在我的项目中,我在框架构造函数中添加了这些行 但这不管用,我不确定是什么问题,我希望你们中有人能帮我解决。