《市场营销人求职交流聚集地》专题
-
称职的区别
问题内容: 从和从调用mapreduce作业有什么区别?当我们说主类说时,如果仅通过main方法对作业进行简单的操作,我们将获得哪些额外的特权呢?谢谢。 问题答案: 没有额外的特权,但是您的命令行选项是通过GenericOptionsParser运行的,它将允许您提取某些配置属性并从中配置Configuration对象: http://hadoop.apache.org/common/docs/r
-
 面经 | 唯品会海外达人运营(一面)
面经 | 唯品会海外达人运营(一面)注:此岗位为实习岗位 一、一面 面试形式:hr加v,语音通话 1.用英文自我介绍 2.因为与海外达人有时差,所以会加班,能接受吗? 3.看到你人在外地,唯品会租房无房补,能接受吗? 面完即收到二面通知,二面见下一篇笔记。#运营人求职交流聚集地#
-
 面经 | 唯品会海外达人运营(二面)
面经 | 唯品会海外达人运营(二面)注:该岗位为实习岗位 一、面试形式: 3个候选人,1个面试官,3v1 二、以下为二面面经: 1.3个人轮流自我介绍 2.面试官对3个人轮流简历深挖 3.如何寻找合适的海外达人? 4.如何劝服达人与我们合作? 5.如何保证达人在规定的时间内完成我们的合作视频并发布? 6.如何在与达人的合作中,保证商品的转化率? 7.轮流问了3个人一个英文问题,问了我在自己的创业经历上花了多少时间 8.由于跟海外达人
-
 面经:人保信息科技运营管理岗
面经:人保信息科技运营管理岗1.自我介绍 2.现场阅读材料,回答问题 3.一道应急应变题 4.针对简历亮点提问一道题 PS:看了牛客之前的面经说面试官是很nice的小姐姐且问了对岗位的理解,职业规划等正常题目(当然没说是什么岗位),怎么到我这就成了八个面试官有的面试官黑屏,有的面试官闭麦,有的面试官一脸疲惫地盯着屏幕(露脸的都是中年人),提前体验了一把公务员面试的感觉,准备的都没用上,全靠糟糕的临场发挥硬撑着而且人保科技刚成
-
如何在codeception中使用saveSessionSnapshot()销毁会话集?
即使在注销后,会话仍保持活动状态。 这是我的登录文件。 公共函数loginAsAdmin($wpUserName,$wpPassword){ } 细节 代码欺骗版本: 2.2.10 PHP版本:操作系统: OS X安装类型:作曲家安装包列表(作曲家显示)我正在使用Lucatume/wp浏览器包进行代码欺骗 这是我的套件配置: class_name:AcceptanceTester模块: 这很好,我
-
从字符串中解析来源城市/目的地城市
问题内容: 我有一个pandas数据框,其中一列是一串带有某些旅行细节的字符串。我的目标是解析每个字符串以提取始发城市和目的地城市(我希望最终有两个新列分别为“起源”和“目的地”)。 数据: 这应导致: 到目前为止,我已经尝试了:各种NLTK方法,但是让我最接近的是使用该方法来标记字符串中的每个单词。结果是带有每个单词和相关标签的元组列表。这是一个例子 我停留在这个阶段,不确定如何最好地实现这一点
-
分别写出数组的交集、并集、差集、补集这四个方法
本文向大家介绍分别写出数组的交集、并集、差集、补集这四个方法相关面试题,主要包含被问及分别写出数组的交集、并集、差集、补集这四个方法时的应答技巧和注意事项,需要的朋友参考一下 这几个方法全是 O(n2) 的复杂度…性能很差
-
公证人签署后,发起人无法将状态提交给vault_linear_states
我有一个基于UUID检索未消费州的查询。 问题陈述:在 Corda 3.0 上,使用 Postgres。查询保管库时,同一 UUID 的多个/缺少未使用状态。由 2 个参与者、借款人和贷款人组成的义务状态,从不同的交易过渡到不同的生命周期。但在某些时候 当借款人查询其保险库以查找该uuid的未使用状态时,它返回了2条记录。 当贷方查询其保管库以查找该uuid的未使用状态时,它返回了0条记录。 在公
-
Maven-用于聚集的“全部”或“父”项目?
问题内容: 出于教育目的,我设置了一个这样的项目布局(为了更好地配合日食,将其布置为扁平状): 父级包含一个包含核心,优化和全部的汇总项目。Core实现了应用程序的强制性部分。Opt是可选部分。所有人都应该将核心与opt相结合,并将这两个模块列为依赖项。 我现在正在尝试制作以下工件: product-core.jar product-core-src.jar 产品核心与dependencies.j
-
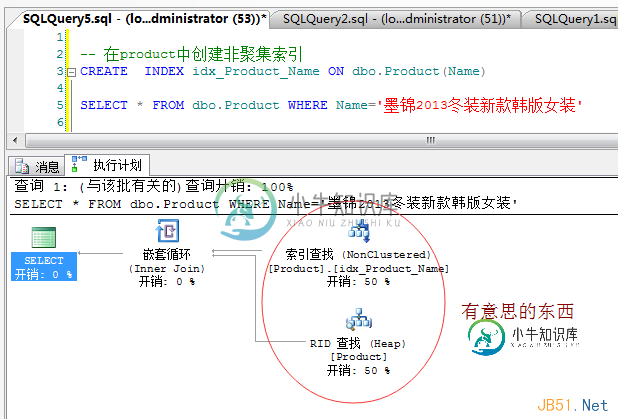 Sql Server中的非聚集索引详细介
Sql Server中的非聚集索引详细介本文向大家介绍Sql Server中的非聚集索引详细介,包括了Sql Server中的非聚集索引详细介的使用技巧和注意事项,需要的朋友参考一下 非聚集索引,这个是大家都非常熟悉的一个东西,有时候我们由于业务原因,sql写的非常复杂,需要join很多张表,然后就泪流满面了。。。这时候就有DBA或者资深的开发给你看这个猥琐的sql,通过执行计划一分析。。。或许就看出了不该有的表扫描。。。万恶之源。
-
SQL Azure无法识别我的聚集索引
问题内容: 当我尝试将行插入到SQL Azure表中时,出现以下错误。 此版本的SQL Server不支持没有聚集索引的表。请创建一个聚集索引,然后重试。 我的问题是我在该表上确实有一个聚集索引。我使用SQL Azure MW生成Azure SQL脚本。 这是我正在使用的: 为什么SQL Azure无法识别我的群集密钥?我的脚本错了吗? 问题答案: 您的脚本只会创建该表(如果该表尚不存在)。也许还
-
是Spring集成聚合器单线程执行
我在应用程序中使用拆分器聚合器模式。我有以下配置- 我的所有通道(CH1、CH2、CH3)都是。Splitter输入通道CH1的源代码是一个文件。 在我的测试中,我观察到即使在CH1通道中添加两个文件,在给定时间也只有一个文件被处理。所以我在我的CH1通道中添加了一个轮询器,现在正在同时处理CH1通道上的多个输入消息。 在聚合器方面,我也注意到执行总是单线程的,即直到第一个线程完成执行,第二个线程
-
TWIML:动词聚集和停顿没有作用
-
对数正态分布中的聚集参数
我想知道是否有可能从一个对数正态分布中得到一个聚合参数。在生态学中,通常使用负二项式中的聚集参数k,该参数度量数据中聚类或聚集或异质性的数量:越小的k意味着更多的异质性。负二项分布的方差为μ+μ2/k,当k变大时,方差接近均值,分布接近泊松分布。在R中,聚合参数称为size参数(Bolker,2008)。 当我在fitdistr中拟合我的数据时,我的数据比负二项式、gamma和Poisson更符合
-
Spring Security SAML中的后台注销请求格式
我正在努力在使用Spring Security SAML扩展时实现单一注销功能。在这种情况下,当从另一个应用程序启动单个注销请求时,必须从身份提供程序(WSO2 身份服务器)向 Spring 安全 SAML 单一注销endpoint发送反向通道请求。问题在于发送到 spring 安全应用程序的反向通道注销请求的格式。我试图以以下[1]和[2]格式发送请求,但分别收到[3]和[4]作为响应。 请帮助