《留学生》专题
-
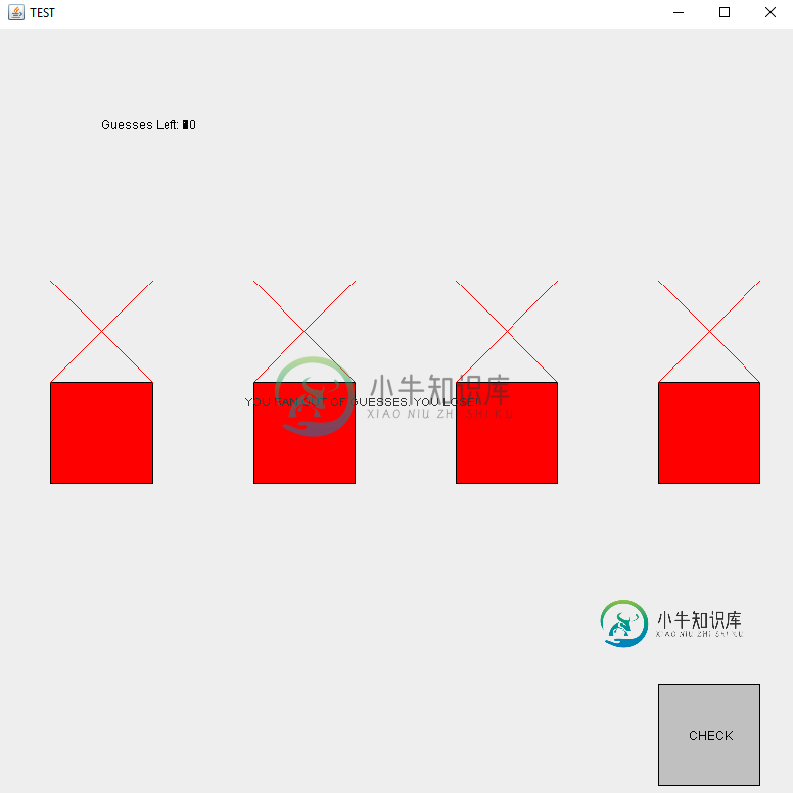 JPanel抽绳留绳
JPanel抽绳留绳我这里有一个JPanel,我想跟踪我给玩家的一些猜测。 每次调用PaintComponent时都会显示猜测。这是代码: 所发生的事情是,从先前调用repaint()来调用此方法的字符串不会消失。 这意味着“猜测剩余:”之后的数字在数字开始堆积之后变得不可读(从10开始,在调用方法之前下降一次)。 我看不出为什么这应该是一个问题。我遇到的一个类似问题是,当停止布尔值为真时,它应该退出该方法,而不是绘
-
Kafka保留政策
假设我有一个多代理(运行在同一主机上)的Kafka设置,其中有3个代理和50个主题,每个主题配置为有7个分区和3个复制因子。 我有50GB的内存要用于kafka,并确保kafka日志永远不会超过这个内存数量,因此我想配置我的保留策略以防止这种情况。 我已设置删除清理策略: 我应该如何配置上述参数,以便每7天删除一次数据,并确保如果需要,可以在较短的窗口中删除数据,这样我就不会耗尽内存?
-
4.3留存分析
留存分析是一种用来了解用户留存情况的分析模型,是衡量产品对用户价值高低的重要指标。产品在经过了拉新和用户流失后,那些依旧留下来持续使用的人就称之为留存。只有做好了留存分析,保证了留存,才能使新用户在注册后不会白白流失。 自定义留存 初始化事件:最好选择用户只触发一次的事件。诸如“注册”、“加入我们”、“上传头像”等等; 回访事件:应设定成用户经常触发,重复激活的行为。诸如“购买”、"评论"、“预订
-
3.3留存分析
3.3 留存分析 留存分析是一种用来了解用户留存情况的分析模型,是衡量产品对用户价值高低的重要指标。产品在经过了拉新和用户流失后,那些依旧留下来持续使用的人就称之为留存。只有做好了留存分析,保证了留存,才能使新用户在注册后不会白白流失。 自定义留存 初始化事件:最好选择用户只触发一次的事件。诸如“注册”、“加入我们”、“上传头像”等等; 回访事件:应设定成用户经常触发,重复激活的行为。诸如“购买”
-
3.3留存分析
3.3 留存分析 留存分析是一种用来了解用户留存情况的分析模型,是衡量产品对用户价值高低的重要指标。产品在经过了拉新和用户流失后,那些依旧留下来持续使用的人就称之为留存。只有做好了留存分析,保证了留存,才能使新用户在注册后不会白白流失。 自定义留存 初始化事件:最好选择用户只触发一次的事件。诸如“注册”、“加入我们”、“上传头像”等等; 回访事件:应设定成用户经常触发,重复激活的行为。诸如“购买”
-
4、留存活跃
4.留存活跃 一、留存活跃 留存可以用作评价用户使用产品的粘性,是非常重要的一个指标。及策提供新增留存和活跃两种评估角度。 二、功能介绍 留存: 可查看今日之前某渠道、推广活动分日、周、月查看1日留存、2日留存……7日留存、14日留存、30日留存占比以及留存激活设备数; 数据导出:根据所选时间范围,CSV格式,命名方式为:留存数据 活跃: 可查看今日之前某渠道、推广活动DAU、MAU; 数据导出:
-
10.7 驻留程序
10.7 驻留程序 驻留程序TSR(Terminate but Stay Resident)是一种特殊应用程序,它在装入内存运行后,其部分代码仍然驻留在内存,当该段代码被激活时,它又进入运行状态。常用的驻留程序是作为某个中断处理程序的一部分,其激活条件就是系统产生了此中断的中断请求。 虽然驻留程序可根据具体的需要有不同的编写方式,但其典型结构包括以下几部分: 1、 保存、修改中断向量表; 2、 程
-
1.3.3.3 留存分析
1. 简介 留存分析是分析用户黏性、活跃度的重要方法。主要用来分析某一群组用户(通常为某批新用户)中再次产生指定行为的人数和比例。随着获客成本逐年递增,留存分析变得越来越重要,做好留存分析,才能为网站带来持续的流量增长。同时对流失用户针对性的调整推广/产品策略,也可以有效提高产品推广的ROI。 2. 使用说明 2.1. 选择初始条件 选择一个事件作为初始条件,点击事件名称前的漏斗图标可以为该事件添
-
留白和格式
空格 vs. 制表符 小技巧 只使用空格,且一次缩进两个空格。 我们使用空格缩进。不要在代码中使用制表符。你应该将编辑器设置成自动将制表符替换成空格。 行宽 尽量让你的代码保持在 80 列之内。 我们深知 Objective-C 是一门繁冗的语言,在某些情况下略超 80 列可能有助于提高可读性,但这也只能是特例而已,不能成为开脱。 如果阅读代码的人认为把把某行行宽保持在 80 列仍然有不失可读性,
-
氧不产生任何留档
这是我的雷克瑟。hpp文件: 一切都很好(这是我的想法),但当我跑的时候
-
数学
转置数字——解决溢出的思路[E] atoi——培养严谨的思路,正负号的处理技巧[E] 回文数字巧解[E] 位运算实现除法[M]
-
数学
Pseudorandom Number Generation 你可以使用内置函数Math.random来生成统一的分布。例如,成介于0和99 (含)的随机整数,可以调Math.floor(Math.random() * 100)。 d3.random.normal([mean, [deviation]]) 返回一个符合正态(高斯)分布normal (Gaussian) distribution的随
-
机器学习:集成学习
“三个臭皮匠顶个诸葛亮”。集成学习就是利用了这样的思想,通过把多分类器组合在一起的方式,构建出一个强分类器;这些被组合的分类器被称为基分类器。事实上,随机森林就属于集成学习的范畴。通常,集成学习具有更强的泛化能力,大量弱分类器的存在降低了分类错误率,也对于数据的噪声有很好的包容性。
-
 动手学深度学习 v1
动手学深度学习 v1本书将全面介绍深度学习从模型构造到模型训练的方方面面,以及它们在计算机视觉和自然语言处理中的应用。
-
 学习敏捷数据科学
学习敏捷数据科学Agile是一种软件开发方法,通过使用1至4周的短迭代,通过增量会话帮助构建软件,从而使开发与不断变化的业务需求保持一致。 敏捷数据科学包括敏捷方法和数据科学的组合。