《群面攻略》专题
-
集群计算与网格计算之间的区别
本文向大家介绍集群计算与网格计算之间的区别,包括了集群计算与网格计算之间的区别的使用技巧和注意事项,需要的朋友参考一下 集群计算 群集计算机是指目标是作为同一单元工作的相同类型计算机的网络。当资源匮乏的任务需要较高的计算能力或内存时,可以使用这种网络。将两个或更多相同类型的计算机组合在一起以组成集群并执行任务。 网格计算 网格计算是指由相同或不同类型的计算机组成的网络,其目标是提供一种环境,在该环
-
 Python脚本实现集群检测和管理功能
Python脚本实现集群检测和管理功能本文向大家介绍Python脚本实现集群检测和管理功能,包括了Python脚本实现集群检测和管理功能的使用技巧和注意事项,需要的朋友参考一下 场景是这样的:一个生产机房,会有很多的测试机器和生产机器(也就是30台左右吧),由于管理较为混乱导致了哪台机器有人用、哪台机器没人用都不清楚,从而产生了一个想法--利用一台机器来管理所有的机器,记录设备责任人、设备使用状态等等信息....那么,为什么选择pyt
-
SPARK独立群集模式下的工作线程数
如何确定spark独立群集模式上的工作线程数?在独立群集模式下添加工作线程时,持续时间将缩短。 例如,对于我的输入数据3.5 G,WordCount需要3.8分钟。但是,在我添加了一个内存为4 G的工作器后,需要2.6分钟。 增加调谐火花的工人可以吗?我正在考虑这方面的风险。 我的环境设置如下:, 内存128克,16个CPU,用于9个虚拟机 输入数据信息 HDFS中的3.5 G数据文件
-
redis在消费者群体内进行有序处理
我将python(aioredis)与redis streams一起使用。 我有一个一个生产者-多个(分组)消费者的场景,并希望确保消费者以有序的方式处理发送到流的(批量)消息,这意味着:当第一条消息完成时,处理流中的下一条消息,依此类推。这也意味着消费者组中的消费者在某一时间正在处理,而其他消费者将等待。 我还希望依赖于第二、第三等消费群体中的有序处理——所有这些都依赖于发送到一个流的相同消息。
-
Qpid客户端连接工厂连接到ArtemisMQ集群
我正在尝试使用Apache Camel和Qpid JMS客户端连接到在两个不同节点(VM)中运行的ActiveMQ Artemis主动-主动集群。我正在使用ActiveMQ Artemis 2.17.0。 我正在试图找出我的组织的远程URI配置应该是什么。阿帕奇。qpid。jms。JmsConnectionFactory实例。使用<代码>ampq://host1:5672,ampq://host2
-
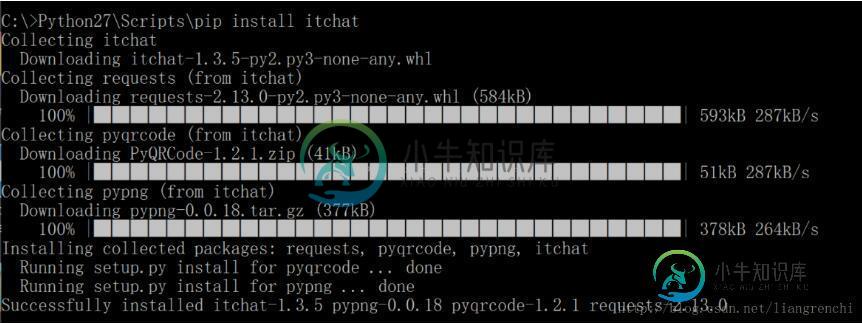 利用python实现在微信群刷屏的方法
利用python实现在微信群刷屏的方法本文向大家介绍利用python实现在微信群刷屏的方法,包括了利用python实现在微信群刷屏的方法的使用技巧和注意事项,需要的朋友参考一下 hello,我是小小炽,这是我写的第一篇博客,写博客一直都想在写,但是苦于能力尚浅,在各位大牛面前那既然是关公面前耍大刀了,但是其实想来每一个大牛不也是从一个小白慢慢进步学习从而达到一定的高度的吗,而且写博客的意义但不在于炫耀你的成果,而在于分享,听取他人的建
-
Docker 使用docker-machine和VirtualBox在Linux上创建集群
本文向大家介绍Docker 使用docker-machine和VirtualBox在Linux上创建集群,包括了Docker 使用docker-machine和VirtualBox在Linux上创建集群的使用技巧和注意事项,需要的朋友参考一下 示例
-
在Mesos群集上以泊坞方式设置Mesos-DNS
问题内容: 我在尝试在mesos集群上运行dockerized的mesos-dns时遇到了一些麻烦。 我已经在Windows 8.1主机上使用ubuntu trusty设置了2个虚拟机。我的虚拟机称为 docker-vm 和 docker-sl- vm ;其中第一个运行mesos-master,第二个运行mesos-slave。 VM有2个网卡;一个运行NAT以便通过主机访问Internet,另一
-
使用Kubeadm在CentOS7.2上部署Kubernetes集群的方法
本文向大家介绍使用Kubeadm在CentOS7.2上部署Kubernetes集群的方法,包括了使用Kubeadm在CentOS7.2上部署Kubernetes集群的方法的使用技巧和注意事项,需要的朋友参考一下 本文参考kubernetes官网文章Installing Kubernetes on Linux with kubeadm在CentOS7.2使用Kubeadm部署Kuebernetes集
-
3节点群集情况下的Hazelcast高可用性
我们使用Hazelcast IMDG作为内存网格。我们集群中的节点数是三个,我们有一个同步备份,并且集群是分区感知的。在这种情况下,我希望分布式映射将均匀分布在3个节点上(或多或少)。如果节点发生故障,领导层应转移到健康的节点(该节点具有丢失数据的同步备份)。如果对这个新分配的leader节点有写请求,那么应该将相同的分区同步复制到一个活动节点。这是否意味着在节点故障的情况下,应该复制大约三分之一
-
一个Kafka话题能搞定多少消费群体?
假设我有一个Kafka主题,大约有10个分区,我知道每个消费群体应该有10个消费者在任何给定的时间阅读该主题,以实现最大的平行性。 然而,我想知道,对于一个主题在任何给定时间点可以处理的消费者群体的数量,是否也有任何直接规则。(我最近在一次采访中被问及这一点)。据我所知,这取决于代理的配置,以便在任何给定的时间点可以处理多少个连接。 然而,我只是想知道在给定的时间点可以扩展多少个最大消费群体(每个
-
Kafka:多个实例中的单一消费者群体
null null 使用简单消费者或低级消费者可以控制分区,但如果一个实例宕机,其他三个实例将不会处理来自第一个实例中使用的分区的消息
-
在kafka集群节点间分配数据套接字
如有任何帮助,不胜感激。
-
单个集群中的AWS ALB入口和Nginx入口
我有一个关于库伯内特斯·安格拉斯的简短问题。我在单个集群中拥有Nginx入口控制器和AWS ALB入口控制器以及Nginx和AWS ALB入口资源。这两个入口资源都指向单个服务和部署文件,这意味着这两个入口资源都指向相同的服务。然而,当我点击Nginx入口URL时,我能够看到所需的页面,但是使用AWS ALB入口,我只能看到apache默认页面。我知道这听起来不太实际,但我正在尝试用这两种入口资源
-
Tomcat的群集/会话复制无法正确复制
问题内容: 我正在本地计算机上的Tomcat 7上设置群集/复制,以评估它是否可与我的环境/代码库一起使用。 建立 我在不同端口上运行的同级目录中有两个相同的tomcat服务器。我已经在其他两个端口上监听了httpd,并作为VirtualHosts连接到了两个tomcat实例。我可以在配置的端口上访问两种环境并与之交互。一切都按预期进行。 Tomcat服务器在server.xml中启用了集群功能: