《群面攻略》专题
-
如何从Kafka的两个不同集群消费?
我有两个Kafka集群说A和B,B是A的复制品。仅当 A 关闭且相反,我才希望使用来自集群 B 的消息。然而,使用来自两个集群的消息会导致重复的消息。那么,有什么办法可以将我的 kafka 使用者配置为仅从一个集群接收消息。 谢谢-
-
Kafka集群增加副本因子不起作用
嗨,在执行本文档中的步骤时,我遇到了一个增加Kafka的复制因子的奇怪问题:https://kafka.apache.org/documentation/#basic_ops_increase_replication_factor 症状看起来复制因子增加根本不起作用。 请帮帮忙 我的Kafka设置是 Kafka版本:kafka_2.12-2.1.0 服务器: 主机名服务器-0 (192.168.0
-
GlassFish群集实例中的JMS队列未同步
我在CLUSTERED Glassfish 3.1.1中使用消息驱动bean时遇到问题。问题在于Glassfish中的队列,队列在实例之间不同步。我正在尽力解释下面的情况。 我在GlassFish集群中创建了2个实例,创建了一个JMS QueueConnectionFactory,创建了一个JMS队列。他们的目标对准了集群。然后,我在集群中部署了web应用程序和MessageDrivenBean模
-
hazelcast jet是否从集群发送/接收数据
我们在一台服务器上托管了一个Hazelcast集群,在同一地区的不同服务器上的不同应用程序使用Hazelcast Jet客户端实例使用管道聚合来自Kafka源的数据。 在这个设置中,Jet client实例是否发送它从Kafka源Hazelcast集群接收的数据,这将涉及大量的IO?或者当我们创建管道时,Hazelcast集群本身创建到Kafka的连接,这个连接来自Jet集群而不是客户端应用程序?
-
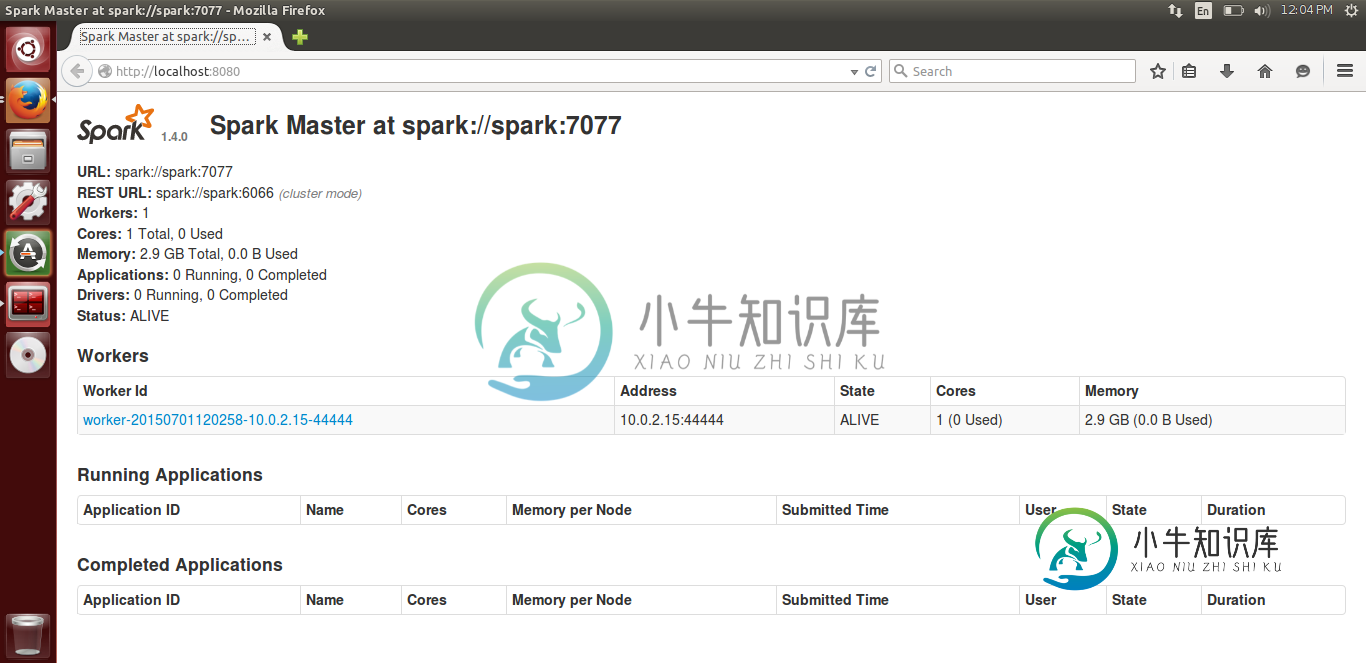 Spark独立集群-从机未连接到主机
Spark独立集群-从机未连接到主机我正试图按照官方文档设置一个Spark独立集群。 我的主人在一个运行ubuntu的本地vm上,我也有一个工作人员在同一台机器上运行。它是连接的,我能够在大师的WebUI中看到它的地位。 以下是WebUi图像- 我已经在两台机器上的/etc/hosts中添加了主IP地址和从IP地址。我遵循了SPARK+独立集群中给出的所有解决方案:无法从另一台机器启动worker,但它们对我不起作用。 我在两台机器
-
在无spark UI的AWS EMR中监控spark集群
我正在AWS EMR上运行一个火花集群。如何在不使用spark UI的情况下获得在AWS EMR上运行的作业和执行器的所有细节。我打算用它来监视和优化。
-
在Spark集群模式下设置环境变量
-
使用spark在Spring创建Redis群集客户端
我有一个项目连接到独立的redis,客户端创建为: 用于绝地武士和spring data redis的库版本为: 现在我需要移动到集群redis,并将客户端创建更改为 通过此代码更改,我在群集中找不到可访问的节点,如下所示: } 由于spark-2.1.3中运行了spark应用程序,由于版本依赖性,我需要使用相同的spring data redis。如果没有jedis和spring data re
-
连接到Apache Kafka多节点集群中的Zookeeper
我按照以下说明设置了一个多节点kafka集群。现在,如何连接到动物园管理员?在JAVA中,只连接一个来自生产者/消费者端的动物园管理员可以吗?或者有办法连接所有的动物园管理员节点吗? 设置多节点阿帕奇动物园守护者集群 在集群的每个节点上,将以下行添加到文件kafka/config/zookeeper.properties中 在群集的每个节点上,在由 dataDir 属性表示的文件夹中创建一个名为
-
如何使用Supervisord自动启动Apache Spark集群?
启动Apache Spark集群通常是通过代码库提供的spark-submit shell脚本完成的。但问题是,每次集群关闭并重新启动时,您都需要执行那些shell脚本来启动spark集群。 我也对其他解决方案持开放态度。
-
Corda V1.0公证集群与Gradle的配置问题
我使用下面的配置来构建Notary Cluster并启动它们。我在V14版本中使用了这样的脚本,这没关系。但是在V1中弹出那个错误。请帮我检查一下。 task-deployNodesRAFT(类型:net.corda.plugins.Cordform,依赖于:['jar']){
-
如何在10节点集群上运行Spark Sql
并编写下面的查询,它是只在我的master上运行,还是将所有10个节点都用作worker? 如果不是,我必须做什么才能让我的Spark Sql使用完整的集群?
-
Apache Camel中的集群:多个JVM相同的CamelContext
我有一个我们部署在集群上的应用程序。根据环境,集群可能有2或4个JVM。该应用程序具有相同的CamelContext,我们正在所有JVM上部署该CamelContext。因此,所有JVM都具有相同的路由。对于FTP路由,这很好,因为它使它具有竞争力,而且只有一个JVM获得文件。然而,当使用基于计时器的操作从DB取数时,我看到所有JVM读取相同的记录集并执行相同的工作。我想要的是,如果一条路捡到了,
-
使用Spring Data连接到多节点Cassandra集群
我的第二个问题是:是否需要?我将来可能会添加更多的节点。
-
大查询集群不能降低查询成本
我对BigQuery中的集群表(带有日期分区)有一个问题。我有一个由名为entity_id的列集群的表。问题是,我希望在进行由这些集群列过滤的查询时看到字节读取减少,但根据BigQuery Web UI,它无论如何都在进行全扫描。 例如:<br>从<code>project.usersDataset中选择*。users_cluster其中entity_id='405849241'限制为1000 返