《群面攻略》专题
-
如何从外部进行健康检查elasticsearch集群
我想写一个脚本来检查我们的elasticsearch集群(部署在kubernetes上)的运行状况 我进入运行elasticsearch主容器的pod中,运行以下命令: 如您所见,索引计数和运行状况检查命令都成功。但当我从外部运行这些命令时(我给elasticsearch集群一个公共endpoint) 只有index count命令成功,健康检查命令总是产生403禁止错误。 我已经从elastic
-
如何为OAuth2访问令牌指定访问群体?
我感到困惑的是,在向授权服务器发送授权请求时,似乎没有标准的方法来指定访问令牌的受众。 OAuth2将访问令牌指定为不透明字符串;规范中只有一处提到了“观众”,即访问令牌可以是“观众限制的”。许多最近的授权服务器实现似乎产生了JWT访问令牌,JWT指定了受众(aud)声明。 据我所知:-Auth0使用“audience”参数-Connect2id使用“resource”参数-Identity Se
-
K-均值迭代失败处理输出/群集-2
我刚学了几天Hadoop,当我在Hadoop中执行Mahout的示例代码时,我得到了以下错误: 代码段
-
在kubernetes集群上运行API测试的正确IP
我有kubernetes集群和pod,它们是集群IP类型。如果要运行集成测试ip:10.102.222.181或endpoint:10.244.0.157:80,10.249.5.243:80,则哪个ip是正确的ip
-
连接到Redis Sentinel集群时使用redis-py的MasterNotFoundError
当我试图按照以下部署指南连接到主节点时,我面临着MasternotFounderRorr:https://docs.bitnami.com/tutorials/deploy-redis-sentinel-production-cluster/ 连接主Redis Sentinel节点的代码是: 我面对红魔。哨兵。MasternotFounderRorr:没有为“MyMaster”错误找到master
-
Spark:检查集群UI以确保工人已注册
警告TaskSchedulerImpl:初始作业未接受任何资源;检查集群UI以确保工作人员已注册并具有足够的资源 另外,在Spark UI中,我看到了以下内容: 作业持续运行-火花 编辑: 我检查了HistoryServer,这些作业没有显示在那里(即使在不完整的应用程序中)
-
Spark submit是否会自动将jar上传到集群?
我正在尝试从本地机器终端向我的集群提交一个Spark应用程序。我正在使用。我也需要在我的集群上运行驱动程序,而不是在我提交应用程序的机器上,即我的本地机器上 当我提供到本地机器中的应用程序jar的路径时,spark-submit会自动上传到我的集群吗? 我在用 和获取错误
-
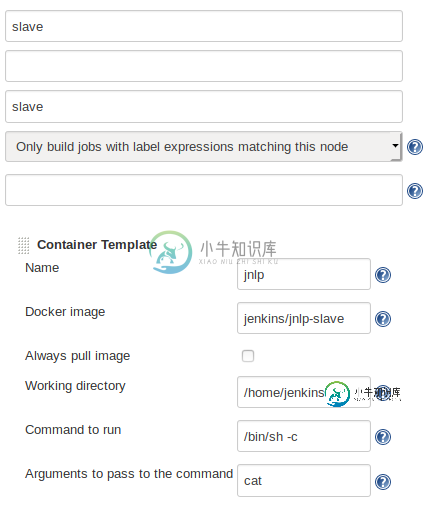 Jenkins jnlp从机不在本地Kubernetes群集上工作
Jenkins jnlp从机不在本地Kubernetes群集上工作我尝试了本地minikube和kubeadm Kubernetes集群,并通过https://github.com/jenkinsci/kubernetes-plugin运行Jenkins服务器,并使用。 以下是了解这个问题的更多细节。
-
Lucene+自定义集群解决方案的ElasticSearch开销
null 哪些管理费用?正如我所知,您可以黑ElasticSearch通过内部TCP API而不是REST与他通信。还有其他管理费用吗?它们只关于复制(您可以关闭初始加载复制)吗?或者关于索引自动合并?也许是由于ElasticSearch试图自动合并索引,并使它们变得如此之大,以至于不能支持FS缓存? 为什么Lucene API更灵活?AFAIK,ElasticSearch有所有相同的索引和其他特
-
如何向远程纱线集群提交Flink作业?
在ResourceManager节点上启动flink作业(查找配置文件) 从ResourceManager下载配置文件到本地。 我想,这两种方式都不太好。如何将作业提交到远程纱线集群。有没有合适的办法?
-
为什么hdfs在Hadoop集群中抛出LeaseExpiredException(AWS EMR)
tail-f/var/log/hadoop-hdfs/hadoop-hdfs-namenode-ip-172-30-2-148.log 2016-09-21 11:54:14,533 INFO BlockStateChange(8020上的IPC Server handler 10):Block*InvalidateBlocks:添加blk_107374750_6677到172.30.2.189:
-
无法在Yarn集群模式下运行Talend作业
我正在使用TOS 7.1和MapR 6.0发行版以及sprak2。2. 流程:主任务- 两份工作1 下面是集群模式的应用程序日志中的错误:线程“main”java中出现异常。lang.NoClassDefFoundError:例程/system/api/TalendJob。 从错误中 请建议。
-
不允许Datanode连接到Hadoop 2.3.0集群中的Namenode
-
Logstash无法连接安全(ssl)弹性搜索集群
在elasticsearch和kibana中启用ssl通信工作良好,但logstash无法连接elasticsearch,但我可以卷曲elasticsearch urlhttps://localhost:9200也没有防火墙阻止,我已经生成了打开的ssl证书和密钥文件并保存在elasticsearch中 弹性搜索配置文件 logstash日志文件
-
部署在Kubernetes集群中的Pod的google云凭据?
这里我可能错了,当我在VM上运行这个python文件时,它可以创建一个新的bucket,而不需要凭据或服务帐户。 如果我将相同的代码Dockere化到flask应用程序中,并将其部署在集群上,那么它是否仍将采用默认的google凭据?我想知道在kubernetes集群上这样做的最佳实践。