《群面攻略》专题
-
使用JAR文件作为DataRicks集群库
我需要安装一个JAR文件作为库,同时设置数据库群集作为Azure发布管道的一部分。到目前为止,我已经完成了以下工作- 使用Azure CLI任务创建群集定义 使用curl命令将JAR文件从Maven仓库下载到管道代理文件夹 在管道代理上设置数据库CLI 使用将JAR文件从本地(管道代理)目录复制到dbfs:/FileStore/jars文件夹 我正在尝试创建一个集群范围的init脚本(bash)脚
-
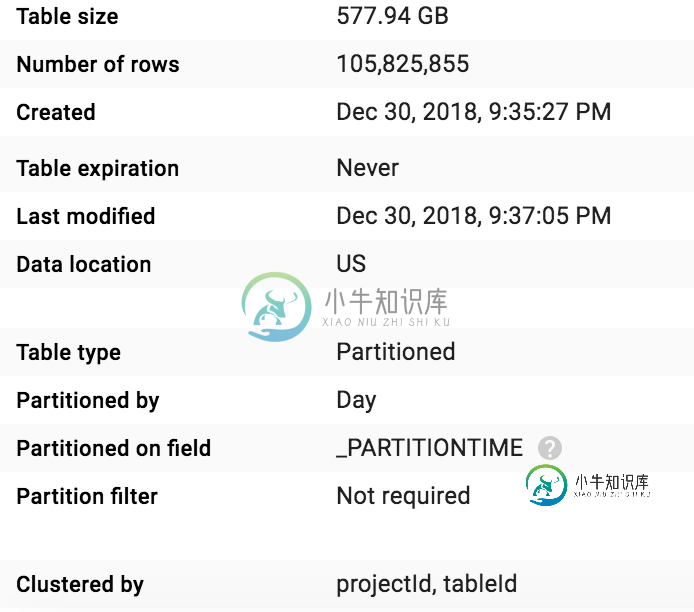 BigQuery群集字段用法/值不清楚
BigQuery群集字段用法/值不清楚我创建了一个包含集群字段的表,但我没有看到任何节省或任何性能改进,这就是我所做的: 我使用以下SQL创建了一个包含3列的目标表:projectId、tableId和schema: 分区字段:默认分区时间群集字段:projectId,tableId 此sql的原始成本为:$2.82 现在,当从新表中进行选择时,我希望 < li >降低成本 < li >获得更好的性能 我正在使用这个SQL 从我的基准
-
使用SASL/PLAIN设置kafka安全集群
我试图通过https://docs.confluent.io/platform/current/security/security_tutorial.htmlSSL密钥和用户名/密码来设置集群,就像描述的那样。 但是未能找到一种合适的方法来设置密钥的dname和代理的参数“super.users” 它被告知创建一个密钥: 稍后配置代理服务器。设置超级用户所需的属性: 因为本教程将代理间安全协议配置
-
如何将local.jar文件传递到集群
我有一个集群,有两个工人和一个主人。为了启动master和workers,我在master计算机中使用和。然后,master UI向我显示奴隶还活着(所以,到目前为止一切正常)。当我想使用时,问题就出现了。 我在本地计算机中执行以下命令: 但是会弹出以下错误: 我一直在研究stack overflow和Spark的文档,似乎应该将命令的指定为“绑定jar的路径,包括应用程序和所有依赖项。URL必须
-
创建豆荚沙箱kubernetes群集失败
我有一个编织网络插件。 我的wave pod正在运行,dns pod也在运行,但是当我想像一个简单的nginx一样运行pod时,wich会拉一个nginx图像pod卡在容器创建中,描述pod给我错误,创建pod沙箱失败。 当我运行journalctl-u kubelet时,我得到以下错误 我的网络插件配置不好吗? 在这不起作用之后,我也尝试了这个命令 我甚至试过法兰绒,这给了我同样的错误。我给ku
-
Hadoop集群设置:连接拒绝错误
下面是我的核心站点。xml: 下面是hdfs-site.xml 下面是mapreduce.xml 谢了。
-
使用zookeeper在集群中调度任务
我们使用Spring来运行调度任务,这在单节点上运行良好。我们希望在由N个节点组成的集群中运行这些计划任务,以便任务在一个时间点由一个节点执行。这是针对企业用例的,我们预计最多会有10到20个节点。 我研究了各种选择: 使用Quartz,这似乎是在集群中运行计划任务的流行选择。缺点:我想避免数据库依赖。 使用zoowatch,并且总是只在领导/主节点上运行计划的任务。缺点:任务执行负载没有分布 在
-
Cassandra如何在表中添加集群键?
卡桑德拉有一张桌子 如何在“排序”列中添加聚类键。不重新创建表
-
融合模式注册表群集模式
我使用来自Confluent的Kafka Connect来使用Kafka流并以拼花格式写入HDFS。我正在1个节点中使用架构注册表服务,它运行良好。现在我想将模式注册表分发到集群模式以处理故障转移。关于如何实现这一点的任何链接或片段都将非常有用。
-
使用prometheus jmxexporter获取spark2集群度量
我们正试图用普罗米修斯来获取火花指标。我们使用jmx导出器jmx_prometheus_javaagent-0.12.0.jar。 ./spark-submit--监督--部署模式集群--conf'spark.driver.extrajavaoptions=-javaagent:jars/jmx_prometheus_javaagent-0.12.0.jar=8060:/conf/spark.ym
-
用ActiveMQ Artemis解决集群测试问题
我有两个ActiveMQ Artemis实例,只需使用命令/.Artemis创建Artemis/server1和 /.Artemis创建Artemis/server2 以下是服务器1的broker.xml: 下面是服务器2的broker.xml: 同样在server2中,Bootstrap.xml中的更改更改了web绑定端口 我正在用StaticClusteredQueueExample和这个示例
-
Apache ActiveMQ Artemis集群中的消息顺序
我试图在Apache Artemis集群中实现消息排序。连接到集群的生产者/消费者实现了高可用性。因此,在某个时间点,将有两个相同应用程序的实例连接到主题或队列。到目前为止,我可以发现以下两种方法可用于在Red Hat AMQ/Artemis集群中实现排序: 消息组(根据文档,只有当集群中每个节点有一个使用者时才是可靠的) 独占队列(仅在单个节点上保留消息顺序)。 我完全理解使用集群和期望消息排序
-
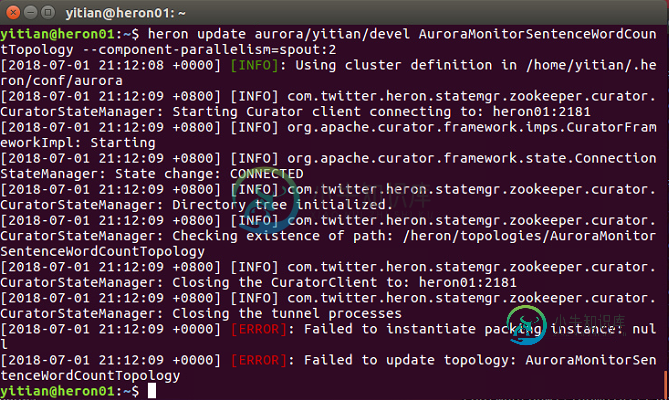 在Heron集群中更新拓扑失败
在Heron集群中更新拓扑失败这个拓扑运行正常,不知道是什么原因导致这个问题。
-
RabbitMQ多个集群上的镜像队列
可以通过多个RabbitMQ集群使用RabbitMQ HA吗? 这是我的要求: 我们有2个RabbitMQ集群(每个集群有4个节点)。两个集群中的所有节点都将使用相同的Erlang cookie。因此,尽管这两个群集在物理上位于不同的位置,但将作为一个包含8个节点的群集。 我们计划使用HAProxy来负载平衡两个集群(8个节点)。发布者和消费者都将使用此代理连接到代理。 我们希望为HA使用镜像队列
-
Kafka在代理集群前支持ELB吗?
我有一个关于AWS上Kafka经纪人集群的问题。现在集群前面有一个AWS ELB,但当我将生产者或消费者的“bootstrap.servers”属性设置为ELB的“A”记录(以及正确的端口号)时,生产者和消费者都无法分别生成和使用消息。我已经关闭了我的代理上的所有SSL,并通过明文9092端口进行连接,我的ELB将端口1234转发到9092。例如,在我的Producer配置属性中,我将。。。 bo