《群面攻略》专题
-
Kafka消费群体命令发布
我运行这个命令: kafka使用者组--引导服务器localhost:9092--组我的使用者组--重置偏移量--最早--执行--主题my-topic-1 它给出了错误: 命令的语法不正确。 根据此命令的帮助结果,我键入的内容似乎是正确的。 我在这里犯了什么错误?
-
春云流-消费群体绑定
我的使用者绑定到匿名使用者组,而不是我指定的使用者组。 我的春靴应用 我的输入输出通道接口 我的控制台日志-- :在3.233秒内启动ConsumerApplication(JVM运行于4.004):[使用者Clientid=Consumer-3,Groupid=Anonymous.0D0C87D6-EF39-4BFE-B475-4491C40CAF6D]发现组协调器Singh:9092(ID:2
-
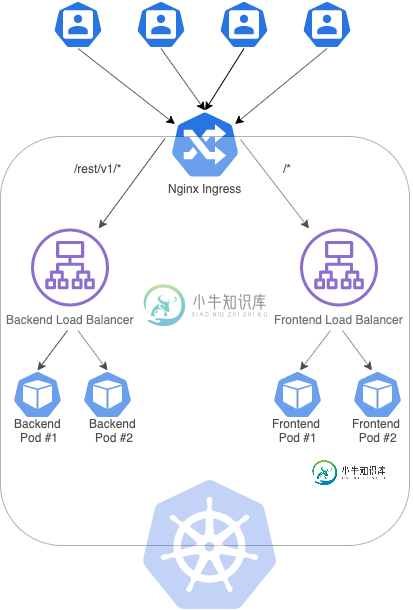 Kubernetes群集上的粘性会话
Kubernetes群集上的粘性会话目前,我正在尝试在Google云上创建一个Kubernetes集群,其中包含两个负载平衡器:一个用于后端(在Spring boot中),另一个用于前端(在Angular中),其中每个服务(负载平衡器)与两个副本(POD)通信。为了实现这一点,我创建了以下入口: 上面提到的入口可以使前端应用程序与后端应用程序提供的REST API进行通信。但是,我必须创建粘性会话,以便每个用户都与同一个POD进行通
-
如何监控 Elasticsearch 集群状态?
本文向大家介绍如何监控 Elasticsearch 集群状态?相关面试题,主要包含被问及如何监控 Elasticsearch 集群状态?时的应答技巧和注意事项,需要的朋友参考一下 Marvel 让你可以很简单的通过 Kibana 监控 Elasticsearch。你可以实时查看你的集群健康状态和性能,也可以分析过去的集群、索引和节点指标。
-
 详解centos下搭建redis集群
详解centos下搭建redis集群本文向大家介绍详解centos下搭建redis集群,包括了详解centos下搭建redis集群的使用技巧和注意事项,需要的朋友参考一下 必备的工具: redis-3.0.0.tar redis-3.0.0.gem (ruby和redis接口) 分析: 首先,集群数需要基数,这里搭建一个简单的redis集群(6个redis实例进行集群)。 在一台服务器上操作,因此仅需要6个不同的端口号即可。分别是:
-
在Heroku上的Puma集群配置
在RoR4 Heroku应用程序上配置Puma(多线程多核服务器)时,我需要一些帮助。那上面的Heroku文档不是最新的。我遵循了这一条:配置的并发性和数据库连接,其中没有提到集群的配置,因此我必须同时使用这两种类型(线程和多核)。 我目前的配置: /程序文件 ./config/puma.rb 问题: a) 我是否需要像Unicorn中那样的before\u fork/after\u fork配置
-
Apache Spark+Ignite集群瘦客户端
我正在尝试使用apache-spark读取和写入Ignite集群,我可以使用JDBC瘦客户机,但不是本机方法,正如几个spark+Ignite示例中提到的那样。 现在,所有的spark+ignite示例都启动了一个本地ignite集群,但我希望我的代码作为客户端连接到已经存在的集群。 完整代码:-(sparkDSLExample)函数无法使用thin连接ignite远程群集 示例-default.
-
Redis群集实时硬盘故障
我们在生产环境中广泛使用redis集群。我们目前有一个30个节点的集群(15个主服务器,15个从服务器)我们正在尝试增加集群,为此我们创建了新的服务器 接下来-我们试图重新加载插槽到新的主人。我们编写了一个脚本来实现这一点,使用命令。 但是-迁移中途失败(但距离开始不远),出现以下错误:
-
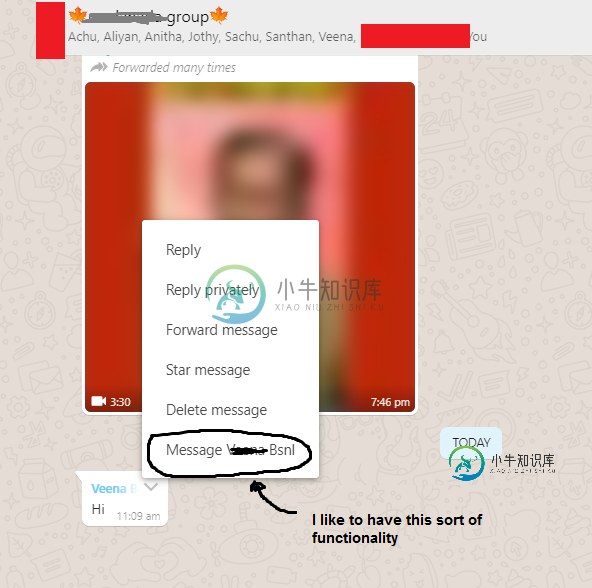 群聊转私聊Whatsapp类功能
群聊转私聊Whatsapp类功能 -
Redis服务器群集不工作
在src目录下,我运行下面的命令 但得到以下错误。 创建集群[ERR]抱歉,无法连接到节点127.0.0.1:7000 但是,如果我使用命令“redis server redis.conf”在7000处启动节点,其中redis.conf在下面 端口7000群集已启用是群集配置文件nodes.conf群集节点超时10群集从属有效性系数0 appendonly是 同样,我成功地在所有端口启动了redi
-
Kubernetes回滚整个群集状态
例如,如果我更改了服务中的一些端口或更改了一个基于secrets的环境变量(然后重新启动我的pods),我可能会破坏一些东西,并希望将配置回滚到以前的版本。 我怎样才能最容易地做到这一点?
-
Kafka只流一次消费群体
当我只打开一次处理时,我会得到以下错误。注意:我们的应用程序非常安全,我们只允许Kafka用户和消费者访问他们明确需要的资源。 只有一次处理kafka流是否在所有流任务中使用每个流任务的消费者组而不是消费者组?
-
集群ActiveMQ中的负载平衡
假设我在一个集群中有3个ActiveMQ Artemis代理: 经纪人_01 在给定的时间点,我有每个经纪人的消费者数量: 经纪人有50名消费者 让我们假设在这个给定的时间点,有70条消息要发送到集群中的一个队列。 我们期望集群完成负载平衡,以便Broker_01将接收50条消息,Broker_0210条消息,Broker_0310条消息,但目前我们正在经历70条消息通过所有3个代理随机分发。 是
-
关于Ignite中的群集配置
现在我在复制的缓存上使用SQL select语句。现在这些缓存的写入同步模式是FULL_SYNC。 现在,我们只能在一个DC中工作客户端节点,而不能同时在两个DC中工作。假设我们有两个客户在DC1。 因此,节点总数为6个(在DC1中有2个客户端节点和2个服务器节点,在DC2中有2个服务器节点)。 我们的用例是这样一种方式… 2个客户端应该只查询DC1中的2个服务器节点,而不是DC2中的其他2个服务
-
Java.lang.OutOfMemoryError:ignite集群上的Java堆空间
我们正在将web应用程序从内存缓存中的临时解决方案迁移到apache ignite集群,其中运行webapp的jboss作为客户端节点工作,两个外部vm作为ignite服务器节点工作。 当用一个客户机节点和一个服务器节点测试性能时,一切正常。但在集群中使用一个客户端节点和两个服务器节点进行测试时,服务器节点会出现OutOfMemoryError崩溃。