《群面攻略》专题
-
Jenkins部署到K8集群
问题内容: 我正在尝试第一次将docker映像部署到kubernetes集群中,我有两个节点master和worker节点都处于启动和运行状态。 我创建了namesapace预发布环境,以在jenkins构建过程中部署我的更改,但我遇到了错误。 詹金斯舞台 你能请人帮我吗? 问题答案: 原因是上下文在您的kubeconfig文件中不存在。您可以运行以检查当前上下文并使用该上下文。
-
云中的Elastic search集群
问题内容: 我有2个Linux VM(都在Cloud Provider的同一数据中心):Elastic1和Elastic2(其中Elastic 2是Elastic 1的克隆)。两者都具有相同的版本centos,相同的群集名称和相同的ES,再次-Elastic2是一个克隆。 我使用服务包装器在启动时自动启动它们,并将彼此的ip引入各自的iptables文件,因此现在我可以在节点之间成功ping。 我
-
如何建立ES集群?
问题内容: 假设我要在5台计算机上运行Elasticsearch集群,并且它们都连接到共享驱动器。我将Elasticsearch的一个副本放到了该共享驱动器上,以便所有三个都可以看到它。我是否只是在我所有机器上的共享驱动器上启动Elasticsearch,并且集群将自动发挥作用?还是我必须配置特定设置以使Elasticsearch意识到它可以在5台计算机上运行?如果是这样,相关的设置是什么?我应该
-
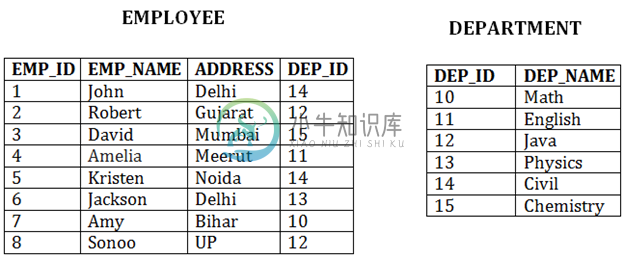 DBMS群集文件组织
DBMS群集文件组织当两个或多个记录存储在同一文件中时,它称为群集。 这些文件在同一数据块中有两个或多个表,并且用于将这些表映射到一起的键属性仅存储一次。 该方法降低了在不同文件中搜索各种记录的成本。 当经常需要以相同条件连接表时,将使用群集文件组织。这些连接只会从两个表中提供几条记录。 在给定的示例中,仅检索指定部门的记录。此方法不能用于检索整个部门的记录。 在这种方法中,可以直接插入,更新或删除任何记录。 数据根
-
Kafka费者群组示例
消费者群组是来自Kafka主题的多线程或多机器消费。 消费者群组 消费者可以通过使用加入一个组。 一个组的最大并行度是该组中的消费者的数量 ← 分区的数量。 Kafka将一个主题的分区分配给组中的使用者,以便每个分区仅由组中的一位消费者使用。 Kafka保证只有群组中的单个消费者阅读消息。 消费者可以按照存储在日志中的顺序查看消息。 重新平衡消费者 添加更多流程/线程将导致Kafka重新平衡。 如
-
 Kafka群集体系结构
Kafka群集体系结构有关Kafka群集体系结构,请看下面的结构图。 它显示了Kafka的集群图。 下表描述了上图中显示的每个组件。 Broker - Kafka集群通常由多个代理组成,以保持负载平衡。 Kafka经纪人是无状态的,所以他们使用ZooKeeper维护他们的集群状态。 一个Kafka代理实例可以处理每秒数十万次的读写操作,每个Broker都可以处理TB消息,而不会影响性能。 Kafka经纪人的领导人选举可
-
无状态EJB和集群
场景:EjbA和EjbB都是远程无状态会话bean。 对b的这些方法调用中的任何一个都可以发生在集群环境中的不同节点/VM上,这是否正确? 甚至连对method1的调用? 我的意思是,如果一些客户端调用方法foo,是否会发生这样的情况:在这个事务中,在node1上调用方法1,下一个对方法1的调用,在同样的foo()调用期间,转到node2上的Ejb实例? 解释下面引用的"Enterprise Ja
-
AWS Aurora群集endpoint用法
如果我使用带有2个读取副本的AWS Aurora MYSQL数据库,我需要使用不同的连接字符串进行读写,还是由集群endpoint为我路由流量?如果是这样的话,对于一个写得更少的应用程序来说,让读副本成为比主副本更大的实例(更强大)是否明智,因为它几乎不会被使用? 提前道谢。
-
Java正则表达式群
有谁能让我睡着吗? 我不知道为什么这段代码现在不工作了。 甚至几个小时前它还能工作!! 请让我知道是什么问题。 输入:300+25 预期输出: 300 + 25 + 输出: null null null 通知PLZ
-
Spark独立集群调优
应用程序不是那么占用内存,有两个连接和写数据集到目录。同样的代码在spark-shell上运行没有任何失败。 寻找群集调优或任何配置设置,这将减少执行器被杀死。
-
HBase 集群环境搭建
一、集群规划 这里搭建一个 3 节点的 HBase 集群,其中三台主机上均为 Regin Server。同时为了保证高可用,除了在 hadoop001 上部署主 Master 服务外,还在 hadoop002 上部署备用的 Master 服务。Master 服务由 Zookeeper 集群进行协调管理,如果主 Master 不可用,则备用 Master 会成为新的主 Master。 二、前置条件
-
Storm 集群环境搭建
一、集群规划 这里搭建一个 3 节点的 Storm 集群:三台主机上均部署 Supervisor 和 LogViewer 服务。同时为了保证高可用,除了在 hadoop001 上部署主 Nimbus 服务外,还在 hadoop002 上部署备用的 Nimbus 服务。Nimbus 服务由 Zookeeper 集群进行协调管理,如果主 Nimbus 不可用,则备用 Nimbus 会成为新的主 Nim
-
Hadoop 集群环境搭建
一、集群规划 这里搭建一个 3 节点的 Hadoop 集群,其中三台主机均部署 DataNode 和 NodeManager 服务,但只有 hadoop001 上部署 NameNode 和 ResourceManager 服务。 二、前置条件 Hadoop 的运行依赖 JDK,需要预先安装。其安装步骤单独整理至: Linux 下 JDK 的安装 三、配置免密登录 3.1 生成密匙 在每台主机上使用
-
1.3.4.3 行为分析分群
用户分群是一种用户运营和用户分析手段,通过对特定用户进行定向投放实现精细化运营,通过对某一个用户群体分析发现不同用户的特征以及偏好。HubbleData的分群区别于传统的标签体系,支持产品策划或者运营人员通过行为数据指定用户,具体使用场景包括: 策划,交互或者视觉同事,通过对比不同分群用户对产品的使用,发现用户特征以优化产品设计 运营通过用户分群定向投放,实现用户的精细化运营 HubbleData
-
操作etcd集群 - 版本
注: 内容翻译自 Versioning 服务版本 etcd 使用 semantic versioning。新的小版本可能增加额外功能到API。 使用 etcdctl 获取运行中的 etcd 集群的版本: ETCDCTL_API=3 etcdctl --endpoints=127.0.0.1:2379 endpoint status API 版本 在 3.0.0 发布值偶 v3 API 应答将不会更