《元气森林》专题
-
R语言随机森林
主要内容:安装R包 - randomForest,语法,示例在随机森林方法中,创建了大量的决策树。每个观察结果都被送入每个决策树。 每个观察结果最常用作最终输出。对所有决策树进行新的观察,并对每个分类模型进行多数投票。 对于在构建树时未使用的情况进行错误估计。 这被称为OOB(Out-of-bag)错误估计,以百分比表示。 R中的软件包用于创建随机林。 安装R包 - randomForest 在R控制台中使用以下命令安装软件包,还必须安装其它依赖软件包(如
-
组合树 - 随机森林
1 Bagging Bagging采用自助采样法(bootstrap sampling)采样数据。给定包含m个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集,使得下次采样时,样本仍可能被选中, 这样,经过m次随机采样操作,我们得到包含m个样本的采样集。 按照此方式,我们可以采样出T个含m个训练样本的采样集,然后基于每个采样集训练出一个基本学习器,再将这些基本学习
-
森林火花斯卡拉
我尝试使用I forest https://github.com/titicaca/spark-iforest,的scala实现,但是当我构建时(就像README中报告的< code>mvn clean package),它给我这些错误: 有人知道为什么吗?谢谢 scala版本2.11.12 火花版本2.4.0 maven版本3.5.2 我修改了pom.xml,调整了scala、spark和mav
-
泰森多边形
Voronoi布局对于无形的交互地区尤其有用,在Nate Vack’s Voronoi picking例子中被证实,看Tovi Grossman’s关于 bubble cursors的论文,以了解相关内容。 Voronoi picking:http://bl.ocks.org/njvack/1405439 d3.geom.() 创建一个带默认访问器的Voronoi布局。 voronoi(data)
-
 北森云计算
北森云计算测试开发实习生 4.17投递 做测评 5.16接电话 约面 5.18一面 主要问了项目,与c++基础,手写代码 一小时十分钟 被告知公司语言是C# 5.19没接到电话 5.21约二面 5.22二面 主要问了个人情况 与项目,手写代码 一小时二十分钟 面试体验还是不错的~与面试官有交流的感觉。
-
 腾讯云面经(已恢复元气,继续感恩)
腾讯云面经(已恢复元气,继续感恩)背包重量:0 offer 凌晨还收到美的的感谢信,全A也挂了,*******,问了身边同学也都挂了,别让我在河道逮到你,你看我给不给你上强度就完事了,小美子。 今天上午元气也还没恢复,头疼的一,忘记录音了,到现在也实在想不起来问了什么,面试官没有开摄像头,也没有算法题,自己也答得很差,但是面试官人很好,感恩。 1、非常大的代码量,编译运行一段时间、发现CPU占用率很高 2、mysqlB+树说一下,
-
随机森林变量选择
我有一个随机森林,目前建立在100个不同的变量之上。我希望能够只选择“最重要”的变量来构建我的随机森林,以尝试提高性能,但我不知道从哪里开始,除了从rf$重要性中获得重要性。 我的数据只是由数字变量组成,这些变量都经过了缩放。 以下是我的射频代码:
-
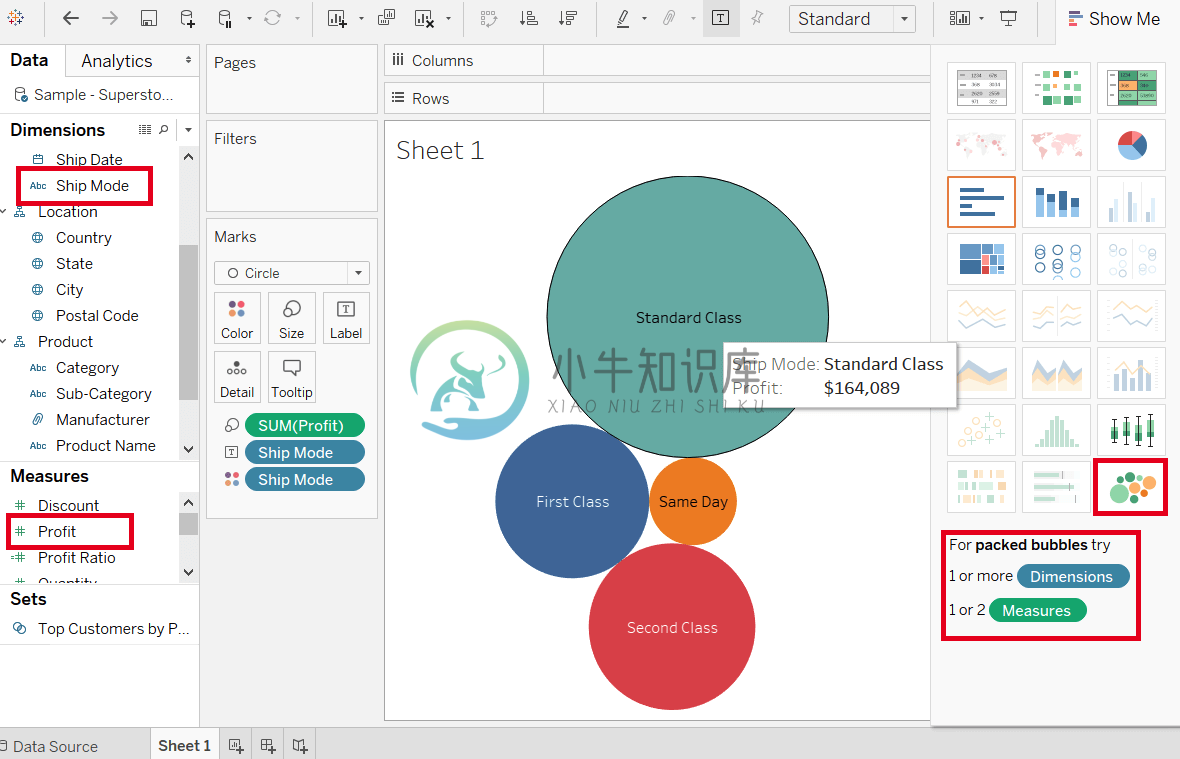 Tableau气泡图
Tableau气泡图气泡图以气泡的形式可视化度量和维度。 气泡图是一组圆圈。维度字段的每个值表示圆圈,度量值表示这些圆圈的大小。 设置气泡的颜色以区分维度中存在的成员。以下是创建气泡图的步骤。 例如,考虑数据源(如样本超市),以及是否要查找不同出货模式的利润。然后, 第1步:拖动度量利润(Profit)并拖放到“大小(Size)”窗格中。 第2步:拖动维度Ship Mode并放入“Labels”窗格。 第3步:同时将
-
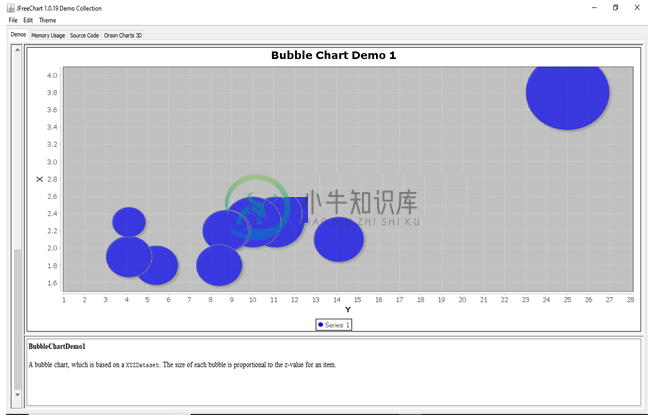 JFreeChart 气泡图
JFreeChart 气泡图主要内容:什么是JFreeChart 气泡图,JFreeChart 气泡图的示例什么是JFreeChart 气泡图 气泡图以三维方式表示信息。此图表是散点图(XY 图表)的变体,其中数据点由气泡替换,数据的附加维度(z 值)以气泡的大小表示。 下图显示了 JFreeChart 库中包含的气泡图的一些演示版本: JFreeChart 气泡图的示例 让我们考虑以下气泡图的示例数据。 国家 汽车 公交车 卡车 印度 40 65 70 美国 30 20 50 中国 80 50 80
-
 寒气逼人
寒气逼人深圳锐明技术 Java实习 面试技术+hr(30分钟) 自我介绍 项目的登录是怎么实现的 项目用redis是干什么的 说说Spring、SpringMVC、SpringBoot的关系 有一个业务场景,需要把excel表的数据存到数据库然后又渲染到前端,说说你的实现思路 怎么创建和启动一个线程 ......忘记了一些 诗悦网络 游戏服务端开发岗位 笔试 选择题+编程题 难度不高 一面(26分钟) 数
-
Highcharts 气泡图
本章节我们将为大家介绍 Highcharts 的气泡图。 我们在前面的章节已经了解了 Highcharts 配置语法。接下来让我们来看下 Highcharts 的其他配置。 配置 chart 配置 配置 chart 的 type 为 'bubble' 。chart.type 描述了图表类型。默认值为 "line"。 chart.zoomType 属性可配置图表放大 ,通过拖动鼠标进行缩放,沿x轴或
-
知雨天气
1.本软件为安卓平台软件 2.通过高德地图定位获取当前的地理信息,通过地理信息获取天气信息和PM2.5信息 3.主要功能,当日天气,近期天气预报,当日空气质量,24小时天气预报 .
-
卢森。net GetFieldQuery与TermQuery
使用Lucene的标准分析仪。有问题的标题字段未存储、已分析。查询如下: 在Luke中,此查询被正确地重新编写为: 我以为Lucene.net版本是: 但是,没有返回任何结果。 然后我试着: 这一切都如期而至! 这两个查询都是通过:_searcher执行的。搜索([查询对象],[排序对象]) 有人能给我指出正确的方向,看看TermQuery和_解析器之间的区别吗。GetFieldQuery()是什
-
1.5.3.2.11.2 泰森多边形
泰森多边形是荷兰气候学家 A.H.Thiessen 提出的一种根据离散分布的气象站的降雨量来计算平均降雨量的方法,即将所有相邻气象站连成三角形,作这些三角形各边的垂直平分线,于是每个气象站周围的若干垂直平分线便围成一个多边形。用这个多边形内所包含的一个唯一气象站的降雨强度来表示这个多边形区域内的降雨强度,并称这个多边形为泰森多边形。泰森多边形又称为 Voronoi 图,是由一组连接两邻点直线的垂直
-
随机森林和 GBDT 的区别?
本文向大家介绍随机森林和 GBDT 的区别?相关面试题,主要包含被问及随机森林和 GBDT 的区别?时的应答技巧和注意事项,需要的朋友参考一下 参考回答: 1)随机森林采用的bagging思想,而GBDT采用的boosting思想。这两种方法都是Bootstrap思想的应用,Bootstrap是一种有放回的抽样方法思想。虽然都是有放回的抽样,但二者的区别在于:Bagging采用有放回的均匀取样,而