《大数据测试》专题
-
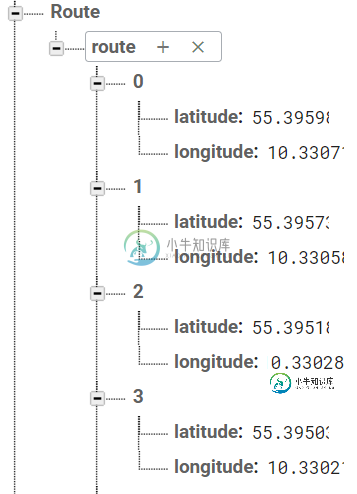 从Firebase数据库中检索数据
从Firebase数据库中检索数据我正在两个标记之间画一条路线,我想保存那条路线。为此,我将包含lat和lng的ArrayList保存在Firebase数据库中。但我在取回航路点时遇到了问题。我是这样插入的: 在检索数据时,我尝试执行以下操作:
-
在数据库中插入blob数据
我想我在这段代码中遇到了一点问题:当我试图在数据库中插入值时,我遇到了一个错误。
-
无法将数据插入数据库
事情是这样的 我不知道发生了什么,如果有人能帮忙,我会非常感激的。THX!
-
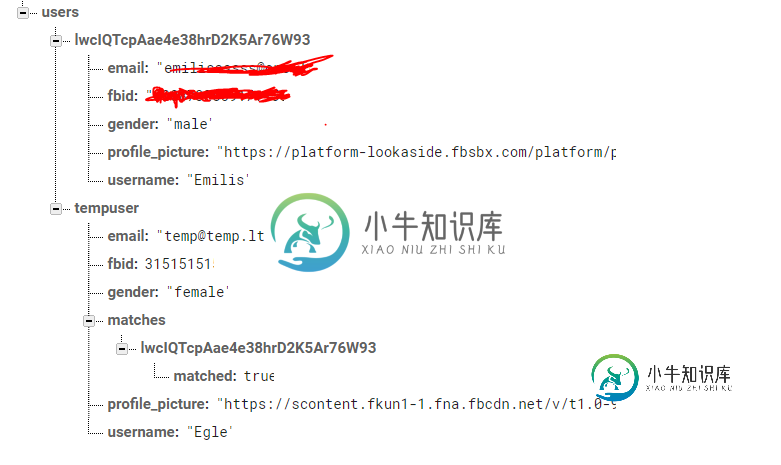 Firebase实时数据库过滤数据
Firebase实时数据库过滤数据所以我正在制作约会应用程序,现在我需要为用户创建一个匹配的人员列表。 因此,我需要一个firebase查询来查看性别,并检查是否已经匹配,如果匹配,则不应将其包括在列表中。 我试着按性别过滤数据。如何编辑此查询以检查它们是否已匹配?匹配项显示在用户/{userID}/Matches/{matchedUserID}中 这是我尝试的:
-
数据类 - 复制一个数据类
如果我们使用不可修改的对象,就像我们之前讲过的,假如我们需要修改这个对象状态,必须要创建一个新的一个或者多个属性被修改的实例。这个任务是非常重复且不简洁的。 举个例子,如果我们需要修改Forecast中的temperature(温度),我们可以这么做: val f1 = Forecast(Date(), 27.5f, "Shiny day") val f2 = f1.copy(temperatur
-
数据模块 - 数据导入导出
数据的导入、导出任务一旦成功建立,结果将以邮件的形式发送到创建任务的用户邮箱里。 数据导出 接口 POST https://cloud.minapp.com/userve/v1/table/:table_id/export/ 其中 table_id 是数据表的 ID 请求参数 参数 类型 必填 说明 file_type String 是 导出文件的格式,支持 csv、json 格式 mode St
-
数据模块 - 数据导入导出
数据的导入、导出任务一旦成功建立,结果将以邮件的形式发送到创建任务的用户邮箱里。 数据导出 接口 POST https://cloud.minapp.com/oserve/v1/table/:table_id/export/ 其中 table_id 是数据表的 ID 请求参数 参数 类型 必填 说明 file_type String 是 导出文件的格式,支持 csv、json 格式 mode St
-
db.insert 向数据库中新增数据
###问题 如何向数据加新增数据? ###解决办法 在 0.3 中,数据库连接如下: db = web.database(dbn='postgres', db='mydata', user='dbuser', pw='') 数据库连接写好以后,“insert” 操作如下: # 向 'mytable' 表中插入一条数据 sequence_id = db.insert('mytable', firs
-
 携程数据笔试
携程数据笔试1.驼峰转换 标志位判断是否下一位字母是否大写 2.判断素数 类型为long,只判断奇数,偶数直接返回 3.将长度为 n 的数组分成 m 个非空子数组,使得每个子数组的最大公约数 的和最大 dp[i][j] 表示前 i 个元素分成 j 个子数组的最大 GCD 和 更新前要递归计算gcd 4.每个套餐春夏秋冬的平均评分,三张表 临时表:先关联套餐表和互动表,用if判断月份来打标tag .计算coun
-
我想根据测试用例Id而不是测试用例摘要来执行测试用例
我已经将Selenium代码与jenkins集成在一起,通过以下步骤执行测试用例: https://wiki.jenkins.io/display/JENKINS/ZephyrJira测试管理插件 现在,我必须根据项目结构讲述我的测试用例。示例:PackageName。类名。MethodName不是正确的方法。 请告诉我是否有任何其他方法可以使用Test ID识别测试用例
-
 大厂运营/数分面试凉经
大厂运营/数分面试凉经滴滴-数据运营实习生 一面-业务面 1.自我介绍 2.询问实习经历 3.如何看待数据运营和数据分析?还是问的数据运营和我之前的战略分析有什么不同 3.异动分析,春节期间代驾订单量变少,会如何分析 4.sql题 5.反问 二面-非业务面 1.主要深挖了实习经历,有没有相关数据处理,怎么做的市场调研,怎么输出 2.一些问题: 未来想从事的工作方向 职场上最不能接受的工作? 如何平衡工作和学习? 还问我
-
如何在数组大小大于1的postgres中获取数组
问题内容: 我有一个看起来像这样的表: 我想做的是返回一组行,其中值按’val’分组,并带有fkeys数组,但仅在fkeys数组大于1的情况下。因此,在上面的示例中,返回值将是看起来像: 我有以下查询聚合数组: 但这返回类似: 最好的方法是什么?我猜可能是将现有查询用作子查询,并对它进行求和/计数,但这似乎效率很低。任何反馈都将真正有帮助! 问题答案: Use子句过滤具有以下内容的组
-
最小堆中确定最大数目的最大比较次数
最小堆由 2047 个元素组成,确定最大元素数所需的最大比较数为 _。 对于这个,我使用了方法,因为这是一个最小堆,最小元素将在根节点中。所以要找到最大值,我们必须一直到树的末尾,直到叶节点级别,并且必须与所有值进行比较。所以比较将是n-1,但ans不是2046,而是1043。有人能给我解释一下吗?
-
为什么 Java 数组的最大大小是整数.MAX值/7?
我有点惊讶地看到为什么在我的机器上,数组的最大大小是整数.MAX_VALUE/7 我知道数组是由整数索引的,所以数组大小不能大于整数.MAX_VALUE。我还阅读了一些堆栈溢出讨论,我发现它在JVM上有所不同,并且JVM使用了一些(5-8咬)。 在这种情况下,最大值也应为。 和 之间的任何值都会给我错误: 这是我可以分配给机器上数组的最大值。具体原因是什么? 更新:我正在运行eclipse中的代码
-
如何在春季测试的@Test方法之前仅填充一次数据库?
问题内容: 我用junit4测试spring服务层的下一个问题是:如何调用仅在所有@Test方法之前填充数据库一次的脚本:我想在所有@Tests之前执行一次此脚本: 我试图在我的GenericServiceTest类(由测试类扩展)上使用@PostConstruct。原来,@PostConstruct每次在每个@Test方法之前都被调用。有趣的是,甚至在每个@Test方法之前都调用了Generic