《大数据测试》专题
-
元数据
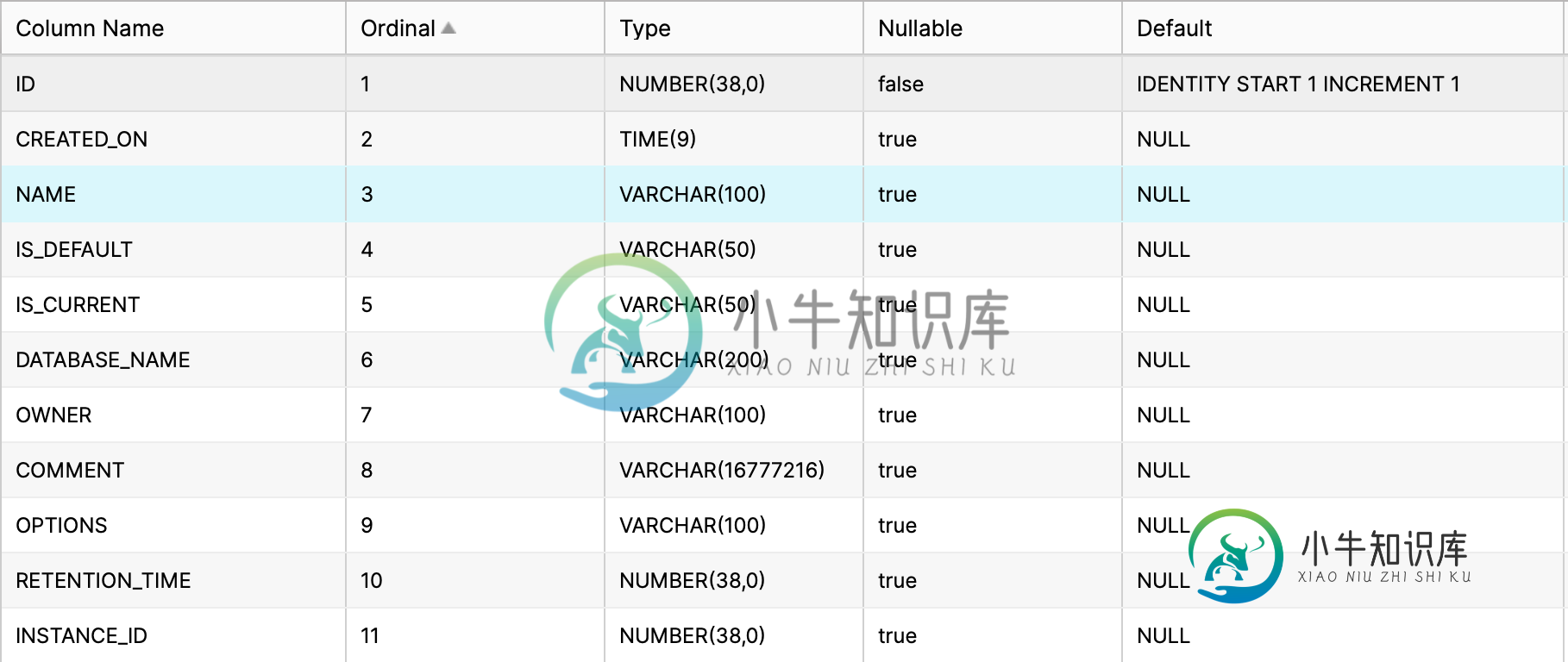
本部分验证元数据缓存功能。 测试数据库初始化 本部分使用 mariadb。创建数据库,用户 $ mysql -u root -p CREATE DATABASE accounts; USE accounts; CREATE USER jdv_user@'%' IDENTIFIED BY 'jdv_pass'; GRANT ALL PRIVILEGES ON accounts.* to jdv_
-
数据库
web 开发离不开数据库。最常见的的数据库是mariadb或者mysql。 为了使用数据库,需要下载访问数据库的库。对mariadb而言,即MariaDB Connector/J。 下载该库,将其安装至/usr/local/nginx/java中。修改/etc/profile.d/jdk.sh中的CLASSPATH,添加该库: export CLASSPATH=/usr/local/nginx/
-
数据列
数据列配置是 Highcharts 最复杂也是最灵活的配置,如果说 Highcharts 是灵活多变,细节可定制的话,那么数据列配置就是这个重要特性的核心 一、什么是数据列 数据列是一组数据集合,例如一条线,一组柱形等。图表中所有点的数据都来自数据列对象,数据列的基本构造是: series : [{ name : '', data : [] }] 提示:数据列配置是个数组,也就
-
 尝试使用SQLAlchemy将数据插入Snowflake数据库表
尝试使用SQLAlchemy将数据插入Snowflake数据库表我创建了一个模型使用在sql炼金术如下所示。 然后我将同一个模型移植到Snowflake数据库。 该模型有一个字段,声明为和。当我尝试插入数据到表使用雪花控制台。我必须提供,否则它不会插入数据并返回错误。 查询(成功执行,其中提供了)- 查询(当我完全忽略列时成功执行)- 查询(执行失败,其中为空)- 它返回了一个错误- 此方法的任务是将数据插入上述数据库表中。 来自SQLAlChemy的错误-
-
基于工作者、核和数据流大小确定最佳火花分区数
Spark-land中有几个类似但不同的概念,围绕着如何将工作分配到不同的节点并并发执行。具体有: Spark驱动程序节点() Spark群集可用的辅助节点数() Spark executors的数量() 所有工作人员/执行人员同时操作的DataFrame() ()中的行数 () ,最后是每个工作节点上可用的CPU核数() 我相信所有的Spark集群都只有一个Spark驱动程序,然后是0+个工作节
-
数据绑定数字输入的最小/最大属性时未触发验证
问题内容: 我有许多数字输入字段,它们的最小值和最大值属性值取决于AngularJS应用中其他地方的逻辑,但是当在这些属性中使用数据绑定时,它们不再由Angular进行验证,但是,HTML 5验证似乎仍然可以选择它们向上。 实时版本:http://jsfiddle.net/kriswillis/bPUVH/2/ 如您所见,由于HTML / CSS(引导程序)在无效时两个字段都变为红色,因此验证仍然
-
maxBy - 根据函数映射每个元素,然后返回数组的最大值
使用提供的函数将每个元素映射到一个值后,然后返回数组的最大值。 使用 Array.map() 将每个元素映射到由fn,然后用 Math.max() 返回的值来获取最大值。 const maxBy = (arr, fn) => Math.max(...arr.map(typeof fn === 'function' ? fn : val => val[fn])); maxBy([{ n: 4 },
-
如何使用csv文件中的不同测试数据集在junit或testng中运行多个测试用例
我希望这个场景有点让我困惑。我想运行一些测试用例使用jUnit或testng与不同的数据集从csv文件。下面给出了我尝试过的代码片段,但它仍然有效, 我的问题是,我需要在不同的测试用例中使用来自每一列的数据,如果csv文件中有多行,我需要再次迭代所有测试用例。我尝试过使用理论和数据点,但它的工作方式是,第一个案例使用csv文件中的所有行运行,它移动到下一个测试案例,然后使用csv文件中的所有行再次
-
如何在没有索引的大熊猫中转置数据框?
问题内容: 可以肯定,这非常简单。 我正在读取一个csv文件并具有数据框: 我想换位得到 但是,当我执行df.T时, 如何摆脱最上面的索引? 问题答案: 您可以先将索引设置为数据框中的第一列(或通常要用作索引的列),然后再转置该数据框。例如,如果要用作索引的列是,则可以执行以下操作: 要么
-
如何解决phpmyadmin导入数据库文件最大限制2048KB
本文向大家介绍如何解决phpmyadmin导入数据库文件最大限制2048KB,包括了如何解决phpmyadmin导入数据库文件最大限制2048KB的使用技巧和注意事项,需要的朋友参考一下 解决办法如下: 1、打开php.ini。找到 upload_max_filesize 、 memory_limit 、 post_max_size 这三个参数! (在默认的情况下,php只允许最大的上传数据为2M
-
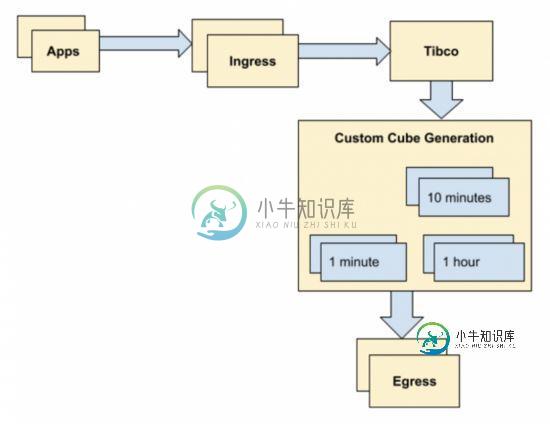 eBay 打造基于 Apache Druid 的大数据实时监控系统
eBay 打造基于 Apache Druid 的大数据实时监控系统本文向大家介绍eBay 打造基于 Apache Druid 的大数据实时监控系统,包括了eBay 打造基于 Apache Druid 的大数据实时监控系统的使用技巧和注意事项,需要的朋友参考一下 首先需要注意的是,本文即将提到的 Druid,并非阿里巴巴的 Druid 数据库连接池,而是另一个大数据场景下的解决方案:Apache Druid。 Apache Druid 是一个用于大数据实时查询和分
-
是否可以限制每个路由的Flask POST数据大小?
问题内容: 我知道可以通过以下方法在Flask中设置请求大小的整体限制: 但是我想确保一个特定的路由将不接受特定大小的POST数据。 问题答案: 你需要检查一下特定路线本身;你可以随时测试内容长度;是一个或整数值: 在访问请求中的表单或文件数据之前,请执行此操作。 你可以将其变成装饰器以供查看: 然后将其用作: 本质上这就是Flask所做的;当你尝试访问请求数据时,在尝试解析请求正文之前,首先检查
-
如何在庞大的数据集(angular.js)上提高ngRepeat的性能?
问题内容: 我有一个巨大的数据集,其中包含数千行,每个行具有大约10个字段,大约2MB的数据。我需要在浏览器中显示它。最简单的方法(获取数据,将其放入,执行其工作)可以很好地工作,但是当它开始将节点插入DOM时,它会使浏览器冻结大约半分钟。我应该如何解决这个问题? 一种选择是将行逐行追加,并等待完成向DOM中插入一个块后再移至下一个。但是AFAIK ngRepeat在完成“重复”操作时不会返回报告
-
流式传输音频时UDP数据包大小/延迟权衡?
我正在构建一个通过udp在线传输实时音频的应用程序,我希望最小化延迟。音频以其生成的速度发送,这意味着生成一秒钟的音频需要一秒钟,发送速度不能超过音频速率。 我最初的想法是发送压缩音频的小数据包,以便客户端可以尽快开始播放。使用Opus编解码器,我应该能够发送5毫秒的音频数据包(最低2.5毫秒),这意味着用户可以很快开始播放,比如说在发送了2个这样的数据包之后。 然而,当使用如此小的分组大小时,会
-
通过意图附加[重复]发送大数据时的异常
在我的应用程序中,我通过extras向我的发送数据。 在我的特定情况下,我下载一个文件,将其内容转换为,并将其作为额外文件发送到我的。大小约为500kB。 我得到了一个。 在这种情况下,哪种方法是绕过此错误的最佳方法?