《长江存储》专题
-
Java HotSpot极长持续时间年轻集合
这是一个长时间运行的服务器应用程序,它创建了很多短期的垃圾,几乎没有任何东西在启动后可以终身使用。大多数时候,年轻一代的收集速度很快,即使是10 gb,它也很快,因为它几乎都是垃圾,但我们偶尔会看到残酷的异常值。作为一个潜在的提示,我们正在一台CPU资源更多但内存少12 gb的机器上以更低的负载运行一台配置类似的服务器。我们在那里没有看到这种模式。 java-xms20g-xmx20g-xlogg
-
TextArea在ScalaFx中扩展场景时不增长
我一直在尝试将我最初用SwingJava编写的一个学校项目转换为ScalaFX的Scala。GUI基本上是一个带有按钮和搜索输入的顶部栏,而栏的底部是一个TextArea,它将显示按钮的输出。这是应用程序启动时的样子。问题是当我用鼠标扩展阶段时,TextArea的大小保持不变。这是一个例子。我试着为ScalaFX查找特定的帮助,但感觉那里的留档相当薄,所以我不得不将我的研究集中在JavaFX上。我
-
垃圾收集有时需要很长时间
在我们的kafka broker设置中,GC平均需要20毫秒,但随机增加到1-2秒。极端情况持续9秒。这种情况的发生频率相当随机。平均每天发生15次。我尝试过使用GCEasy,但没有给出任何见解。我的内存使用率为20%,但进程仍然使用交换,尽管内存可用。感谢您对如何将其最小化的任何意见 JVM选择: GC日志:
-
最大长度小数的正则表达式
我不确定这是否可以使用正则表达式。我会尝试使用正则表达式,但如果不可能,我会切换到双重验证。 我的数据库(postgresql)接受为15,6(最多15位,最多6位小数),因此如果我有10位整数,我可以有5位小数。小数分隔符被忽略。 我目前有一个正则表达式(逗号是小数分隔符): 它不验证总长度,只验证左侧的数字。但由于用户也可以键入点(千位分隔符),我有一个怪物:
-
防止基于长度的消息帧篡改?
对于我的基于TCP的网络应用程序,我使用基于长度的消息帧传输数据。很简单,一个数据包看起来是这样的: Length是一个Int32,告诉我即将到来的原始数据的长度。 用这个来防止磨炼,有什么好办法呢?我可以实现一个大小限制(例如,每个数据包1MB,任何高于这个值的东西都将丢弃客户机并阻止它),但是有没有更多的“标准”解决方案,不会让人觉得那么讨厌呢?
-
无法用长键获取Thymeleaf中的HashMap值
但是,在加载模板时,我得到了以下异常。 我不知道为什么要在键为时将其解析为。有什么方法可以让Thymeleaf将值解析为吗?
-
按长度分解字符串,保留单词
使用javascript,我想将任意长度的字符串拆分为最多80个字符的段。需要注意的是,我不想拆分单词。例如,我目前正在使用下面列出的方法在JavaScript中将大字符串拆分为n大小的块 问题是,一个从第76个字符开始到第84个字符结束的单词将被分成两半。是否有一个光滑的正则表达式或代码来防止这种情况? 为了澄清这一点,我能够编写一个小函数来实现这一点,我只是想知道是否有一种干净、简洁的方法。
-
可变记录长度的Cobol索引文件
我有一个没有COBOL构建的COBOL索引文件。现在我必须创建一个FD来打开和读取COBOL中的记录。 唱片有一个固定长度的键部分。我也有一个数据部分。两个字段的长度可变。此字段的长度存储在记录的其他字段中。 文件描述如下所示: 显然这行不通。有人知道我应该如何配置这个文件来打开它吗? 我应该在文件控件中定义这些可变记录大小吗?
-
在python中使用ffmpeg获取视频时长
我已经在PC上使用pip ffprobe命令安装了ffprobe,并从这里安装了ffmpeg。 然而,我仍然在运行这里列出的代码时遇到麻烦。 我尝试使用下面的代码,但没有成功。 有人知道怎么了吗?我没有正确引用目录吗?是否需要确保和视频文件位于特定位置? 如果这个问题有点基本的话,我很抱歉。所有我需要的是能够迭代一组视频文件,并获得他们的开始时间和结束时间。 谢谢!
-
数组字符串长度的总和列表
如果我有一个< code>ArrayList的单词,比如: 我想计算 4 5 6 3 3 3 作为 中每个字符串的长度之和加上单词之间的 5 个空格。我该怎么做?
-
Android Studio中的长包名称构建错误
我的应用程序包名很长: 这是一个B2B的项目,我现在不能减少他们的包名称,因为它已经修复了。 系统找不到指定的文件。(2). 我认为这个问题必须有一个解决办法。请引导。
-
PHP cURL不能正确设置内容长度
-
从字符串SQL中选择最长的字
假设我有一个有2列的表:name和number。Name是一个字符串,可以有一个或多个单词,我想要一个新的查询选择名称编号,但在Name列,它只有最长的词,原来的表。 SQL中是否有一个函数只从字符串中提取最长的单词?
-
如何使elasticsearch评分考虑字段长度
我创建了一个非常简单的测试索引,由以下5个条目组成: 然后我执行以下查询: 期望在结果中获得以下顺序: 1)“音乐节” 2)《音乐节舞曲》 然而,我得到了以下结果: 它的顺序似乎完全随机,除了最低分只匹配一个词。 是什么导致了这种情况,我可以改变什么(在映射、索引或搜索过程中)来获得预期的顺序? 注意:对于非完美匹配查询也是如此。搜索“音乐舞蹈”仍然应该产生3个单词条目作为第一个结果,所以使用或增
-
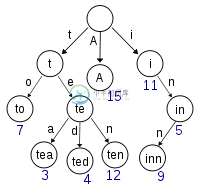 如何在trie中找到最长的单词?
如何在trie中找到最长的单词?如果我正确地看到了这一点,那么trie中的所有叶节点都将拼写出整个单词,所有父节点都包含最终叶节点之前的字符。因此,如果我有一个名为DigitalTreeNode的类,其定义为 如果我想实现一个返回trie中最长单词的方法,是否只需要在每个叶节点查找最长单词?如何实现方法,例如: 我猜它涉及到设置一个最长的字符串变量,递归地遍历每个节点,并检查它是否是一个单词,如果它是一个单词,并且它的长度大于最