
如何在trie中找到最长的单词?

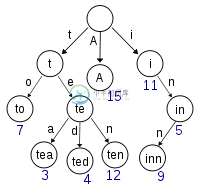
如果我正确地看到了这一点,那么trie中的所有叶节点都将拼写出整个单词,所有父节点都包含最终叶节点之前的字符。因此,如果我有一个名为DigitalTreeNode的类,其定义为
public class DigitalTreeNode {
public boolean isAWord;
public String wordToHere; (compiles all the characters in a word together)
public Map<String, DTN> children;
}
如果我想实现一个返回trie中最长单词的方法,是否只需要在每个叶节点查找最长单词?如何实现方法,例如:
public static String longestWord (DigitalTreeNode d);
我猜它涉及到设置一个最长的字符串变量,递归地遍历每个节点,并检查它是否是一个单词,如果它是一个单词,并且它的长度大于最长的变量,那么lengte=newWordLength。但是,我不确定地图儿童如何适应。我如何使用上面的方法在任何trie中找到最长的单词?
共有1个答案

叶节点通常不包含整个字符串(尽管它们可以),在trie中,叶节点通常只包含一个'$'符号来表示这是字符串的结尾。
要在trie中找到最长的单词,可以在树上使用BFS,首先找到“最后”的叶子。“last leaf”是从BFS队列中弹出的最后一个元素(在它弹出之后,BFS的算法将以空队列停止)。
要从这片叶子中获得实际的单词,您需要从叶子向上返回到树根。本文讨论了如何做到这一点。
这个解决方案是O(S*n),其中S是字符串的平均长度,n是DS中字符串的数目。
如果你能操纵trie DS,我认为它可以做得更好(但这似乎不是这个问题的问题)
伪代码:
findLongest(trie):
//first do a BFS and find the "last node"
queue <- []
queue.add(trie.root)
last <- nil
map <- empty map
while (not queue.empty()):
curr <- queue.pop()
for each son of curr:
queue.add(son)
map.put(son,curr) //marking curr as the parent of son
last <- curr
//in here, last indicate the leaf of the longest word
//Now, go up the trie and find the actual path/string
curr <- last
str = ""
while (curr != nil):
str = curr + str //we go from end to start
curr = map.get(curr)
return str
-
我已经用两个类实现了一个DS Trie:Trie和TrieNode。我需要编写一个函数,返回在O(h)中Trie中最长的字符串。我的TrieNode有一个字段LinkedList,它存储每个节点的子节点。我们还没有了解到BFS或DFS,所以我正在努力思考一些创造性的方法来解决它。 我已经有了一个函数(一个单独的函数),它通过给定的char插入/创建一个新节点:在构建trie时:创建一个节点,该节点
-
我们得到了表格的邻接列表 意味着从U到V有一个成本C的优势。 给定的邻接列表适用于具有N个节点的单连通树,因此包含N-1条边。 给出了一组节点。 现在的问题是,在F中的节点中找到最长路径的最佳方法是什么?可以用O(N)来做吗? 来自F中每个节点的DFS是唯一的选项吗?
-
我有一个简单的Trie,我用它来存储大约80k个长度为2-15的单词。它非常适合检查字符串是否是单词;然而,现在我需要一种获得给定长度的随机单词的方法。换句话说,我需要“getRandomWord(5)”来返回一个5个字母的单词,所有5个字母的单词都有相同的机会被返回。 我能想到的唯一方法是选择一个随机数并遍历树的宽度--首先,直到我通过了所需长度的那么多单词。有没有更好的办法做到这一点? 可能没
-
本文向大家介绍找到字符串中最长的单词,并返回它的长度相关面试题,主要包含被问及找到字符串中最长的单词,并返回它的长度时的应答技巧和注意事项,需要的朋友参考一下 function findLongestWord(str){ // let arr=str.split(" "); let arr=str.replace(/[,|.|;]/," ").split(" "); let longLength=
-
问题内容: 我有一个词表 我想将每个列表项与一个字符串进行比较,并且输出应该是最相似的词。示例:如果是,则是最相似的词。如何在python中执行此操作?通常,我在清单中所用的单词可以很好地区分。 问题答案: 使用difflib: 正如您从仔细阅读源代码可以看到的那样,“接近”匹配项的排序从最佳到最差。
-
问题内容: 我有一个名为5列的表格。 我想使用该列查找要说的行:然后在该列中列出最受欢迎的单词。一个会是,另一个会是,但是我想看看与此相关的其他词。 样本数据: 结果(单字): 问题答案: 您可以通过一些字符串操作来提取单词。假设您有一个数字表,并且单词之间用单个空格分隔: 如果没有数字表,则可以使用子查询手动构造一个表: SQL小提琴(由@GrzegorzAdamKowalski提供)在这里。