《数据产品》专题
-
从Android4.2中的资产中复制sqlite数据库时出现“无法打开数据库”错误
我的代码在Android2.3上运行良好,但我不知道为什么在Android4.2上不运行 我的异常日志在这里 我的mainactivity.java 我的DatabaseHelper.java
-
获取WooCommerce中可变产品的“库存”产品变化的计数
我正在尝试为函数编写一个代码段。php文件,该文件仅显示所选变体的一个价格,因此忽略了在单个产品页面上随变体价格一起显示的价格范围。我正在使用以下代码: 问题是,例如,当您有两个单一产品的变体,而其中一个缺货时,此脚本会在单一产品页面上隐藏剩余变体的价格。我在想,也许每个产品都有一些可用的变体,并使用IF来使用标准的单一产品模板来显示它们。或者你有更好的办法解决这个问题?
-
数据库元数据
表元数据 下面这些方法用于获取表信息: 列出数据库的所有表 $this->db->list_tables(); 该方法返回一个包含你当前连接的数据库的所有表名称的数组。例如: $tables = $this->db->list_tables(); foreach ($tables as $table) { echo $table; } 检测表是否存在 $this->db->table_
-
Kafka-生产商批次数
有没有办法确定Kafka制作人为一组特定消息创建的批次数?例如,如果我在一个循环中发送10K条消息,有没有办法检查发送了多少批?我将“batch.size”设置为一个高值,我的期望是消息将被缓冲,并且在我的消费者中看到消息时会有延迟。然而,这似乎是打印几乎立即在我的消费者计划。 批处理时的默认值。尺寸是16384。这是字节数吗?
-
3.8 随机数产生器
下面要介绍一个在模拟事件和游戏的程序中常用的组件。本节和下节开发一个结构良好、包括多个函数的游戏程序。程序中要使用前面介绍的大多数控制结构。 在赌场上,人人都关心的一个问题就是机会元素(element of chance),也就是赢钱的运气。这个机会元素可以用标准库中的rand函数引入计算机应用程序中。 考虑下列语句: i=rand(); rand 函数产生O到RAND_MAX之间的整数(这是<s
-
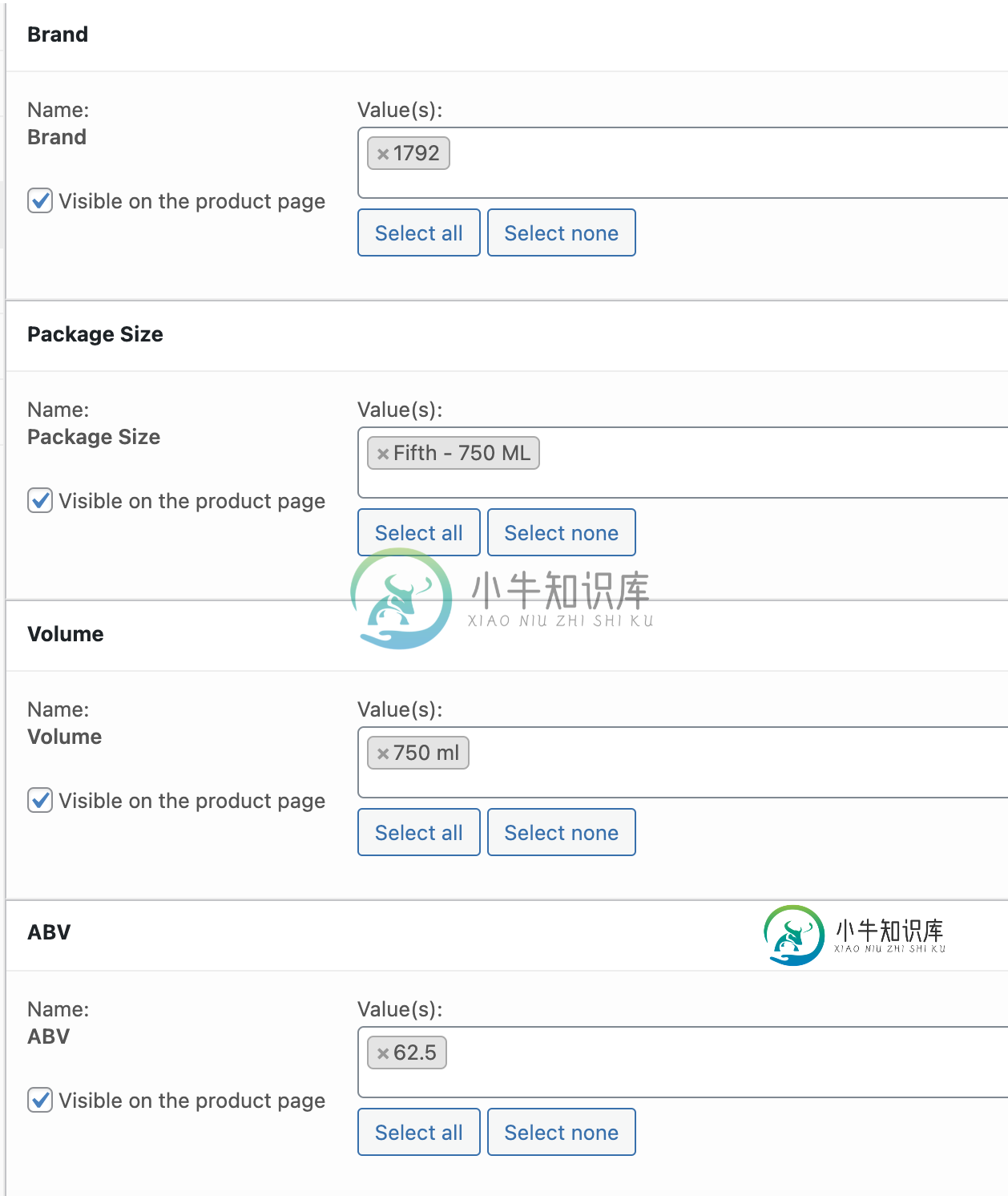 WooCommerce产品属性数组没有值
WooCommerce产品属性数组没有值当我试图获得所有产品属性时,它们没有任何值。 回应- 阵列([pa_品牌]= 但它在后端显示值
-
 龙湖数科产品经理(一面)
龙湖数科产品经理(一面)自我介绍 产品设计过程中需要注意的点? 你认为产品经理需要掌握哪些技能知识? 认为实习公司的产品有哪些部分可以改进?当时有向领导反馈吗? 实习工作的亮点是什么? 面对压力你是如何做的? 为什么选择龙湖? 总体来说面试体验很好,反问环节问面试官我问了自己在面试过程中可以提升的点时,面试官也很认真地给了建议。 但是本人表现有点差😭。还是要好好总结和梳理自己的实习内容以及各种项目。 #面经##龙湖数科
-
 龙湖数科产品一面凉经
龙湖数科产品一面凉经1.自我介绍(这次真的太仓促了,自我介绍还用的是之前的介绍,复盘应该结合简历的产品再包装一下的) 2.为什么做产品(简历写了我做过运营,研发和产品) 3.从产品实习中学到了什么(答得太糟了,明明有产品经历的,应该结合star写的) 4.硕士专业和做产品有什么关系 5.了解其他互联网吗(完全不了解。。) 6.了解龙湖的其他岗位吗(感觉之前的答得不太好,面试官想快点走流程结束了) 7.反问:龙湖的产品
-
 卓望数码产品经理一面
卓望数码产品经理一面#非技术2024笔面经# 自我介绍 项目如何展开 详细介绍项目 如何发掘亮点 项目的亮点、如何保证满意 如何满足客户需求 任务完不成,怎么办 技术人员尝试新方案,会带来风险怎么办 出现风险怎么规避 如何保证任务在规定的时间节点完成,如何检查 项目经验怎么总结 人工智能对产品的未来影响 工作的地点选择 问问题 面试官人非常好,一直在引导我正确的回答,面试体验很好
-
 美云智数产品测试面经
美云智数产品测试面经凭心而说,面试并不难,但是我准备不够充分。 面试前一定要背好个人介绍的台词,我为了面试准备的策划里是有个人介绍准备的,但是因为复习知识点没来得及背,临场发挥的挺糟糕的; 其次,是一定一定一定要熟悉自己的所有项目,多问问自己流程+功能+遇到的问题。因为是线上面试,我面试前过了一遍两个岗位相关的项目,还用思维导图的整理了一遍具体展示的流程,想着看着文档演示就是了,所以就没背。这完全是学生项目展示的思维
-
 数字广东产品经理一面
数字广东产品经理一面自我介绍 每段实习工作内容深挖,怎么做的,然后结果怎么样等等 问我对政务了解多少? 会使用哪些产品工具? 怎么去做需求分析? 数据能力怎么样? 你认为你和这个岗位的匹配度? 最后就是反问了 面试总体感觉比较有压力,尤其是实习经历那块儿问的非常非常细!下次在面试一定要狠狠准备! #产品面经#
-
如何通过从资产中销毁和重新加载数据库来迁移机房数据库
清空了我的数据库,我不知道如何从我的文件夹中的数据库重新填充它。也许我可以在fallbackToDestructiveMigration发生时指定一个回调? 如果我添加了一个迁移方法,expected&found之间有太多的差异,再加上我不知道如何将某些列设置为“not null”。
-
从表单获取日期并将其保存到数据库并列出产品
问题内容: 我正在尝试创建一个页面,该页面可以列出保存在数据库中的产品,然后客户可以查看可用产品的列表。我遇到的问题是Java中的日期。 我收到的错误消息是 有人可以告诉我怎么了吗? 问题答案: 更换 通过
-
在WooCommerce中添加产品自定义输入文本作为订单项数据
我想在不购买插件的情况下实现这一点。 不幸的是,我无法通过结帐阶段。 在这里我的步骤: //1属性的创建 //2保存属性 //3在前端显示属性 //4验证属性 //5将属性添加到购物车 //6在购物车中显示属性 因此,客户可以在产品页面中看到该字段,填充该字段并将产品添加到购物车,并在购物车页面中看到自己的自定义文本。直到现在一切都好。 但是,在退房时,我丢失了有关Embroed文本的信息,我无法
-
 base上海 字节跳动 国际化广告产品——数据分析实习生
base上海 字节跳动 国际化广告产品——数据分析实习生一面 面我的是国际化广告产品部:数据科学组的负责人,30来岁,男。人真的超级超级好,超级有耐心,不会嫌弃你一问三不知,而是会努力引导。 主要是4个部分。 一、自我介绍 我自我介绍前,面试官有跟我说希望我在自我介绍的时候能突出“自己与这个岗位的匹配度”! 然后我主要还是按照自己原来准备过的3 part来说: 1)硬核能力(代码+统计知识) 2)业务、商业洞察力(之前实习积累的经验+2次商赛经历) 3