
Dataflow Bigquery Bigquery管道在较小的数据上执行,但不在大型生产数据集上执行

这里的数据流有点新手,但是已经成功地创建了一个运行良好的pipleine。
pipleine从BigQuery读入查询,应用ParDo(NLP函数),然后将数据写入新的BigQuery表。
我试图处理的数据集大约为500GB,有4600万条记录。
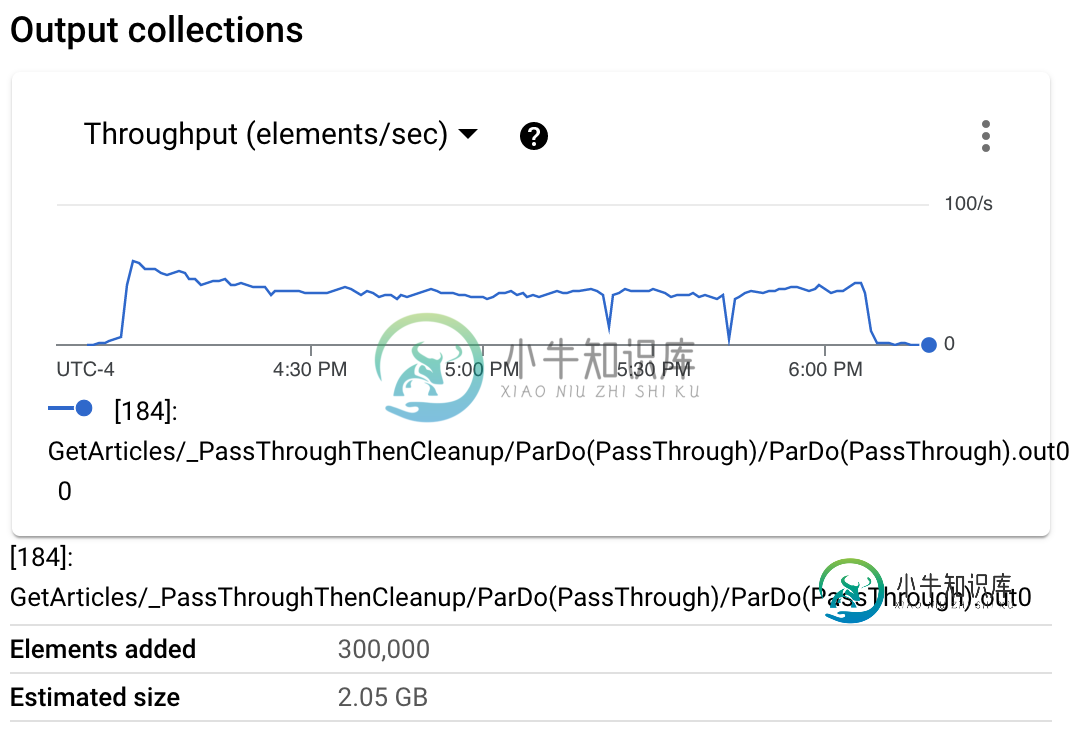
当我试着用完整的数据集运行它时,它开始的速度非常快,但随后逐渐变慢,最终失败。此时,作业失败,添加了约900k个元素,约为6-7GB,然后元素计数实际上开始减少。
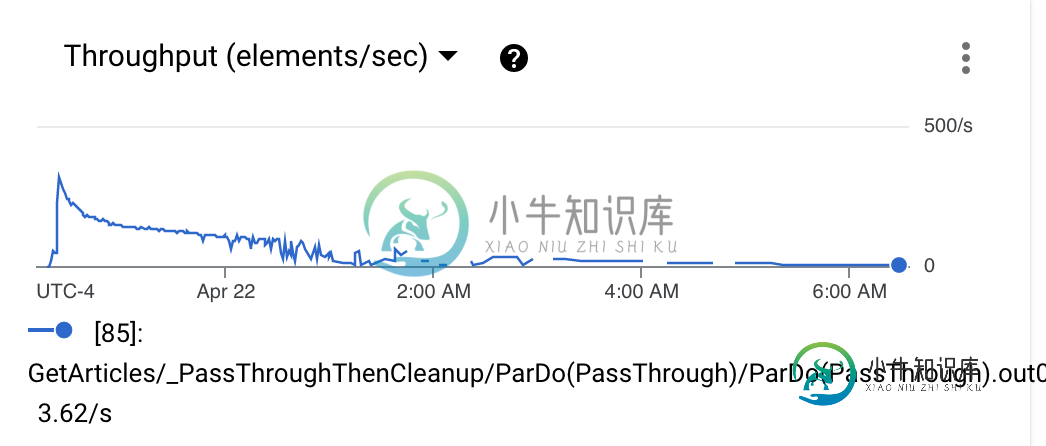
我使用250名工人和n1-highmem-6机器类型
在工作日志中,我得到了其中的一些(大约10个):
Info
2021-04-22 06:29:38.236 EDTRefreshing due to a 401 (attempt 1/2)
这是最后的警告之一:
2021-04-22 06:29:32.392 EDTS08:[85]: GetArticles/Read+[85]: GetArticles/_PassThroughThenCleanup/ParDo(PassThrough)/ParDo(PassThrough)+[85]: ExtractEntity+[85]: WriteToBigQuery/BigQueryBatchFileLoads/RewindowIntoGlobal+[85]: WriteToBigQuery/BigQueryBatchFileLoads/AppendDestination+[85]: WriteToBigQuery/BigQueryBatchFileLoads/ParDo(WriteRecordsToFile)/ParDo(WriteRecordsToFile)/ParDo(WriteRecordsToFile)+[85]: WriteToBigQuery/BigQueryBatchFileLoads/IdentityWorkaround+[85]: WriteToBigQuery/BigQueryBatchFileLoads/GroupFilesByTableDestinations/Reify+[85]: WriteToBigQuery/BigQueryBatchFileLoads/GroupFilesByTableDestinations/Write+[85]: WriteToBigQuery/BigQueryBatchFileLoads/ParDo(_ShardDestinations)+[85]: WriteToBigQuery/BigQueryBatchFileLoads/GroupShardedRows/Reify+[85]: WriteToBigQuery/BigQueryBatchFileLoads/GroupShardedRows/Write failed.
在执行细节中有很多这样的细节:
2021-04-22 06:29:40.202 EDTOperation ongoing for over 413.09 seconds in state process-msecs in step s6 . Current Traceback: File "/usr/local/lib/python3.7/runpy.py", line 193, in _run_module_as_main "__main__", mod_spec) File "/usr/local/lib/python3.7/runpy.py", line 85, in _run_code exec(code, run_globals) File "/usr/local/lib/python3.7/site-packages/dataflow_worker/start.py", line 144, in <module> main() File "/usr/local/lib/python3.7/site-packages/dataflow_worker/start.py", line 140, in main batchworker.BatchWorker(properties, sdk_pipeline_options).run() File "/usr/local/lib/python3.7/site-packages/dataflow_worker/batchworker.py", line 844, in run deferred_exception_details=deferred_exception_details) File "/usr/local/lib/python3.7/site-packages/dataflow_worker/batchworker.py", line 649, in do_work work_executor.execute() File "/usr/local/lib/python3.7/site-packages/dataflow_worker/executor.py", line 179, in execute op.start() File "<ipython-input-81-df441d984b0a>", line 194, in process File "<ipython-input-81-df441d984b0a>", line 173, in extract_entities File "<ipython-input-81-df441d984b0a>", line 95, in get_company_sentences
我假设这些是来自数据集中可能需要一段时间才能处理的较大文本,所以在处理了一点之后,这些项目就开始了下一个项目。
其中也有一些:
2021-04-22 06:29:40.202 EDTOperation ongoing for over 413.09 seconds in state process-msecs in step s6 . Current Traceback: File "/usr/local/lib/python3.7/runpy.py", line 193, in _run_module_as_main "__main__", mod_spec) File "/usr/local/lib/python3.7/runpy.py", line 85, in _run_code exec(code, run_globals) File "/usr/local/lib/python3.7/site-packages/dataflow_worker/start.py", line 144, in <module> main() File "/usr/local/lib/python3.7/site-packages/dataflow_worker/start.py", line 140, in main batchworker.BatchWorker(properties, sdk_pipeline_options).run() File "/usr/local/lib/python3.7/site-packages/dataflow_worker/batchworker.py", line 844, in run deferred_exception_details=deferred_exception_details) File "/usr/local/lib/python3.7/site-packages/dataflow_worker/batchworker.py", line 649, in do_work work_executor.execute() File "/usr/local/lib/python3.7/site-packages/dataflow_worker/executor.py", line 179, in execute op.start() File "<ipython-input-81-df441d984b0a>", line 194, in process File "<ipython-input-81-df441d984b0a>", line 173, in extract_entities File "<ipython-input-81-df441d984b0a>", line 95, in get_company_sentences
所有这些对我来说都有点困惑,而且不完全是直观的——尽管它工作时的服务非常棒。
我正在从Jupyter noteboook执行作业(不使用交互式运行程序,只执行脚本)。
主要管道如下:
p = beam.Pipeline()
#Create a collection from Bigquery
articles = p | "GetArticles" >> beam.io.ReadFromBigQuery(query='SELECT id,uuid, company_id_id, title, full_text, FROM `MY TABLE` ', gcs_location=dataflow_gcs_location, project='my_project',use_standard_sql=True)
#Extract entities with NLP
entities = articles | "ExtractEntity" >> beam.ParDo(EntityExtraction())
#Write to bigquery
entities | 'WriteToBigQuery' >> beam.io.WriteToBigQuery('myproject:dataset.table', schema = schema,custom_gcs_temp_location=dataflow_gcs_location, create_disposition="CREATE_IF_NEEDED",write_disposition="WRITE_APPEND") ```
我做错了什么?这是记忆问题吗?我不应该像这样读写BigQuery,而是输出到一个文件并从中创建一个表吗?会需要一些帮助,并为长的帖子感到抱歉,希望提供尽可能多的背景。
共有2个答案

我发现数据流对于像这样的大型NLP批处理作业不是很好。我解决这个问题的方法是将较大的作业分为较小的作业,这些作业可以可靠地运行。因此,如果您能够可靠地运行10万个文档,只需运行500个作业即可。

也许聚会迟到了,但是我在一个包含7.7M行的BigQuery表上做了一些测试,这些行包含大约350个单词的字符串。
我运行的管道与您相同:
- 从BigQuery读取数据
- 使用python
stringlibrary - 使用Spacy
fr\u core\u news\u lg模型,获取字符串的柠檬化部分 - 将数据写回BigQuery(在不同的表中)
一开始,我遇到了和你一样的问题,元素/秒的数量随着时间的推移而下降。
我意识到这是RAM的问题。我将machine\u type从custom-1-3072更改为custom-1-15360-ext,并从与您相同的配置文件更改为此配置文件:
我认为Dataflow可以使用NLP模型处理大量的行,但您必须确保为工作人员提供足够的RAM。
此外,使用number\u of_worker\u harnese\u threads=1确保数据流不会产生多个线程(从而将ram拆分为线程)也很重要。
你也可以看看这个堆栈线程,最初的问题是一样的。
这也是缺乏内存的标志。
编辑:我运行了我的管道,使用与您相同的数据量规模,以确保我的测试没有偏见,结果是一样的:内存的数量似乎是使作业顺利运行的关键:
-
我想在谷歌数据流上运行一个管道,该管道取决于另一个管道的输出。现在,我正在本地使用DirectRunner依次运行两条管道: 我的问题如下: DataflowRunner是否保证第二个仅在第一个管道完成后启动
-
问题内容: 我有一个名为“ df”的熊猫数据集。 我该如何做以下事情? 谢谢。 对于那些了解R的人,有一个名为sqldf的库,您可以在R中执行SQL代码,我的问题基本上是,是否在python中有像sqldf这样的库 问题答案: 这不应该做,您可以看一下包(与R中的一样) 更新2020-07-10 更新
-
我的问题与上一个问题相关,即如何有效地连接大型pyspark数据帧和小型python列表,以获得数据块上的一些NLP结果。 我已经解决了一部分,现在被另一个问题卡住了。 我有一个小型pyspark数据帧,比如: 它只有不到 100 行,而且非常小。每个术语在“术语权重”列中都有一个术语权重值。 我还有另一个大型 pyspark 数据帧 (50 GB),如下所示: 对于df2中的每一行,我需要在所有
-
我正在eclipse中使用模拟器。我在模拟器中提取了大约2200条文本消息/data/data/com.android.providers.telephony/databases/mmssms。从emulator中读取db,并在其中看到文本消息 SQLiteDatabase smsDB=SQLiteDatabase.openDatabase("/data/data/com.android.prov
-
问题内容: 我正在尝试调整SQL查询以检查服务器上每个数据库中存在的特定字段中存在的值。 有100个单独的数据库,我想检查每个数据库的特定记录。 答案可能是使用下面的命令,但是我很难适应它。 我在下面的链接上获得了更大的成功; https://stackoverflow.com/a/18462734/3461845 我需要能够执行以下查询: 并且还为返回的每一行拉回数据库的名称; 任何帮助是极大的
-
我正在移植一个为使用Jenkins的声明性管道而构建的系统。一切都进行得很顺利,但在我目前正在运行的管道中,我看到了一些意想不到的奇怪现象。管道设置为在远程代理系统上执行所有阶段和步骤。管道具有并行阶段,在3个代理的6-8个执行者之间产生大量工作。这一切都很好。 但由于某些原因,当管道执行时,主节点上消耗的执行器似乎“镜像”了一个正在运行的远程执行器。它似乎没有做任何工作(主机上的CPU使用率非常