《快手数据研发》专题
-
 快手Java开发一面
快手Java开发一面秋招第一个面试 80分钟面试内容总结: 1 上来一个算法题 重合区间合并,例如输入{{1,3},{2,5},{8,9}},结果是{{1,5}}. 2 说一下比较自信的项目 3 实习都是干的啥 4 讲一讲kafka的组成。如果kafka消息推送失败怎么办。 5 MySQL的index,Redis的数据类型 6 MongoDB的优势以及跟其他NoSQL的区别 7 多线程 线程池设计 如果线程满了任务队
-
 快手java开发三面
快手java开发三面快手三面 感觉有点像交叉面,因为比二面面试官年轻,hhh,总体体验还可以问的不是很难。 1、上来自我介绍,然后闲扯优点是什么?缺点是什么?为什么转行,职业规划是怎么样的? 2、了不了解我们部门,是特意去了解的还是面试官主动给你介绍的? 3、聊实习,结合实习问到了消息通道的使用,如何去做负载均衡? 4、实习的过程当中遇到的最大困难是什么?怎么解决的 5、学习的过程当中遇到的最大困难是什么?是怎么解决
-
 快手 Java 开发一面
快手 Java 开发一面拷打实习经历,介绍一下你实习中 SQL 注入漏洞的解决? SQL 注入漏洞有哪些? 服务注册发现是怎么实现的? 动态配置是怎么实现的? 注册中心的底层实现是什么? 服务限流是怎么实现的? 详细讲一下漏桶算法和令牌桶算法? Java 中集合的类型有哪些? HashMap 的键值对可以重复吗? Set 是如何保证唯一性的? HashSet 的底层实习是什么? HashMap 为什么不是线程安全的? T
-
 快手Java开发 面经
快手Java开发 面经8月26日 网申 9月10日 一面 自我介绍 项目拷打 Mybatis SQL注入 Elasticsearch 如何设计数据库表 mysql存储引擎 总结项目 手撕(easy) 反问 主问项目,八股都是从项目中延申。面试体验十分nice,好评。 部门做的内容很喜欢,希望可以收到二面。 打破了我对快手的偏见。 #快手##快手面试#
-
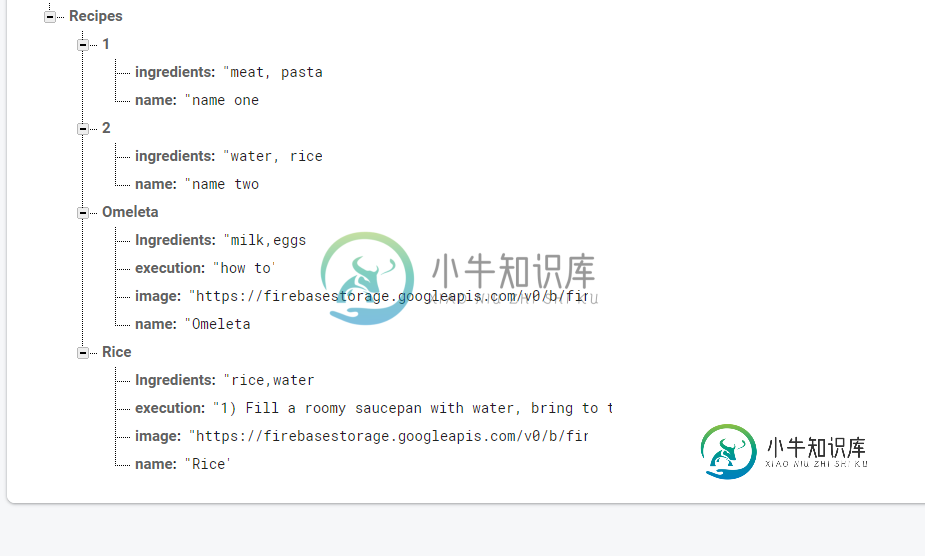 从firebase数据库快照读取数据
从firebase数据库快照读取数据因此,我尝试拍摄数据库的快照,并添加带有子项的数组字符串中的项。 我的set和get java文件如下所示 但是,当我的程序到达dataQuery方法并尝试获取和设置名称和成分时,它会崩溃。有人能解释一下我做错了什么,以及是否有更好的方法来使用数据库快照来做到这一点吗? 进程:in.tvac.akshayejh.firebasesearch,PID:24798java.lang.NullPoint
-
 快手平台产品商业化-产品经理(数据业务)
快手平台产品商业化-产品经理(数据业务)1.自我介绍 2. 深挖实习经历 3. 第一个问题就是关于数据分析相关的工作,工作内容,数据报表的形式 4. 需求是基于什么提出的?之前实习中PRD需求前的调研以及分析工作都如何做的?什么流程什么形势 5. 与数据产品合作时候,如何做的项目,你的主要工作是什么? 6. 需求上线后会不会复盘业务的数据? 7. 你的职业偏向:两个track 功能产品和数据产品 8. 原型图画得怎么样,sql hive
-
 携程 数开 校招 数据研发工程师 凉经
携程 数开 校招 数据研发工程师 凉经一面(2023.9.15) 11点开始,11点41分结束 面试官很和蔼,不过周围有点吵。(面试官叫王xx,我不太记得了,人挺好的) 自我介绍 实习项目介绍(我这真是面出经验了,只要你项目他不感兴趣,接下来就是八股时间) 学校里有什么课程 八股问的多到离谱,总共就30分钟不到,全八股。 int和Integer有什么区别? Integer(200) new 两次,他们是一样的吗? valueOf方法介
-
FireBase查询。数据快照
问题内容: 我需要有关从此DataSnapshot结果中获取“消息”对象的帮助 我可以通过获取键值,并且也可以作为对象,这是FireBase自动生成的对象名称。而不是听对象本身。如何使用DataSnapshot成员方法浏览低谷,“发送者”或“消息”并获取其值? 问题答案: 我似乎在为具有多个子项的对象添加值侦听器。我猜这是一个查询,但是如果您在问题中包含代码,那将非常有帮助。但是,在您添加它之前,
-
 大数据实验手册
大数据实验手册这是一本关于大数据学习记录的手册,主要针对初学者.做为一个老IT工作者,学习是一件很辛苦的事情.希望这本手册对帮助大家快速的学习与认识大数据(特指Hadoop Spark),为了不让初学者一下接触爆炸式的新概念,我们会以实验先行,概念跟进的方式进行课程学习,这样有利于大家快速进入状态,而不至于一直深陷逻辑概念出不来,但是每个人的学习方式不一样,仁者见仁智者见智吧。
-
 顺丰科技|大数据平台研发|一面
顺丰科技|大数据平台研发|一面了解哪些大数据组件 Shuffle 的作用是什么 Shuffle 中合并的操作有什么用/好处 MapReduce 中出现数据倾斜怎么处理 Yarn 有哪几个比较重要的进程 ResourceManager 主要的作用 ApplicationMaster 主要的作用 任务的监控在哪个进程 ZooKeeper leader选举机制 ZooKeeper 读写一致性具体体现在哪些地方 Spark 宽窄依赖
-
 顺丰(大数据研发):一面+二面,凉经
顺丰(大数据研发):一面+二面,凉经### 一面 自我介绍+实习经历 (31608)### 二面 1. 自我介绍 2. 实习经历,我说了JVM的重用 3. JVM重用的底层原理 4. sql输出排名前七的学生 5. hive处理小文件的方式 6. hive组件,原理 7. hiveSQL转化为mapreduce的执行过程 8. hive执行过程中的优化 9. 为什么使用环形缓冲区 10. HDFS组件 11. secondnamen
-
 招银网络科技数据研发岗一面
招银网络科技数据研发岗一面9.21 自我据介绍(面试官说简历上都是python项目,笔试用c++做的,就问c++。。。) c++容器有哪些?序列容器?关联容器? 函数重载?重写?重定义? 虚函数什么情况下使用?内存有什么不同?虚表大小? 手撕题(链表) 计网问题: 三次握手 粘包?怎么解决?因为开启了什么算法? 怎么排查网络问题? 反问的时候说今年没有专门数据研发岗,是进去之后再分配岗位,后端开发可能要转java 攒人品,
-
 招银网络科技数据研发岗面经
招银网络科技数据研发岗面经一面: 1.自我介绍, 2.询问了实习中的项目具体内容,提出了一个场景,问如何保证准确率 3.sql的执行顺序 4.数据库的索引类型 5.sql题 一道非常简单 还有一道要用到窗口函数 求连续三天登录 6.还有其他问题 有点记不清了 一面结束之后大概是隔天就收到了二面消息 二面: 1.自我介绍 2.问实习期间的项目 问了好几个小问题 3.问之前学习过程遇到的困难 怎么处理的 4.问MySQL和Or
-
 杭州银行总部数据研发一面11.7
杭州银行总部数据研发一面11.7问项目 解释什么是yolo,是什么模型 介绍cnn 池化层有几种 list和元组区别 pass怎么用 怎么处理异常 怎么抛出异常 浅拷贝深拷贝 sql中视图是什么 索引有几类 怎么实现 还有一些记不清了 问的比较基础但杂
-
 阿里 数据研发工程师(实习)面经
阿里 数据研发工程师(实习)面经# 一面4.20 电话面,当时忘了记录,一部分忘了 自我介绍 maxwell我没用过,可以简单介绍一下吗 除了maxwell你还知道哪些数据同步工具 介绍项目整体内容,技术方案和业务内容 数据倾斜的解决方案(讲了join,group by的解决办法,但被问还有没有) Linux查看文件命令 more和less的区别 udf、udaf、udtf的区别 hashmap的原理 进程线程区别 你觉得你的性