《大数据求职》专题
-
MySQL错误1153-收到的数据包大于'max_allowed_packet'字节
问题内容: 我正在导入MySQL转储,并收到以下错误。 显然,数据库中存在附件,这使得插入量非常大。 这是在我的本地计算机上,一台从MySQL软件包安装了MySQL 5的Mac。 我在哪里更改才能导入转储? 还有什么我应该设置的吗? 只是运行会导致相同的错误。 问题答案: 您可能必须为客户端(您正在运行以执行导入)和正在运行并接受导入的守护程序mysqld进行更改。 对于客户端,可以在命令行上指定
-
批量加载一个巨大的数据集来训练pytorch
我正在训练一个LSTM,以便将时间序列数据分类为2类(0和1)。我在驱动器上有巨大的数据集,其中0类和1类数据位于不同的文件夹中。我试图通过创建一个Dataset类并将DataLoader包装在它周围来批量使用LSTM。我必须做整形等预处理。这是我的密码 ' `我在运行此代码时遇到此错误 RuntimeError:Traceback(最后一次调用):文件“/usr/local/lib/python
-
Kafka源和接收器连接器不适用于大数据
我正在使用Kafka源和接收器连接器创建一个数据管道。源连接器从SQL数据库消费并发布到主题,而接收器连接器订阅主题并放入其他SQL数据库。表有16 GB的数据。现在的问题是,数据不能从一个数据库传输到另一个数据库。但是,如果表的大小很小,比如1000行,那么数据可以成功传输。 源连接器配置: 源连接器日志: 有人能指导我如何调整Kafka源连接器以传输大数据吗?
-
 北京大数据研究院:Java后端实习 技术+hr
北京大数据研究院:Java后端实习 技术+hr9月22,腾讯会议,两个面试官 面试时长:35min 面试官1:技术官 自我介绍 1、String类的常用方法 2、用过StringUtil工具类吗 3、常用集合 4、hashmap的put流程 5、set转list怎么转 6、说一下我的高并发项目 7、nginx的负载均衡算法 8、springcloud主要使用 9、Linux常用命令 10、docker常用命令,Jenkins怎么使用的 11、
-
 Mysql提升大数据表拷贝效率的解决方案
Mysql提升大数据表拷贝效率的解决方案本文向大家介绍Mysql提升大数据表拷贝效率的解决方案,包括了Mysql提升大数据表拷贝效率的解决方案的使用技巧和注意事项,需要的朋友参考一下 前言 本文主要给大家介绍了关于Mysql提升大数据表拷贝效率的相关内容,分享出来供大家参考学习,我们大家在工作上会经常遇到量级比较大的数据表 ; 场景: 该数据表需要进行alter操作 比如增加一个字段,减少一个字段. 这个在一个几万级别数据量的数据表可
-
java导出大批量(百万以上)数据的excel文件
本文向大家介绍java导出大批量(百万以上)数据的excel文件,包括了java导出大批量(百万以上)数据的excel文件的使用技巧和注意事项,需要的朋友参考一下 本文实例为大家分享了java导出百万以上数据的excel文件,供大家参考,具体内容如下 1.传统的导出方式会消耗大量的内存,2003每个sheet页最多65536条数据,2007每个sheet页可以达到100万条数据以上,2007会在生
-
asp.net实现Postgresql快速写入/读取大量数据实例
本文向大家介绍asp.net实现Postgresql快速写入/读取大量数据实例,包括了asp.net实现Postgresql快速写入/读取大量数据实例的使用技巧和注意事项,需要的朋友参考一下 最近因为一些项目需要大量插入数据,研究了下asp.net实现Postgresql快速写入/读取大量数据,所以留个笔记 环境及测试 使用.net驱动npgsql连接post数据库。配置:win10 x64, i
-
大熊猫:在多列上合并(合并)两个数据框
问题内容: 我正在尝试使用两列来连接两个熊猫数据框: 但出现以下错误: 任何想法应该是正确的方法吗?谢谢! 问题答案: 尝试这个 https://pandas.pydata.org/pandas- docs/stable/reference/api/pandas.DataFrame.merge.html left_on:要在左侧DataFrame中加入的标签或列表或类似数组的字段名称。可以是Dat
-
PySpark获取具有最大日期的数据框列的值
我需要在pyspark数据框中使用窗口上的max date行中的列值创建一个新列。鉴于下面的数据框架,我需要根据最近日期的调整系数为每个资产的每个记录设置一个名为max_adj_factor的新列。
-
python实时绘制串口数据有很大的滞后性
我正在尝试从串行端口读取数据,并使用matplot在图形中绘制数据。下面是我的代码:我看到由于绘图,有巨大的延迟(队列中的数据高达10000字节),因此我看不到实时绘图。如果我做错了什么,你能帮我一下吗。
-
数据库(最大)字段长度是否会影响性能?
问题内容: 在我的公司中,我们有一个包含各种表的遗留数据库,因此包含许多字段。 许多字段似乎都有从未达到的大限制(例如:)。 是否将字段的最大宽度设置为最大宽度或比通常输入的字段大2到3倍会对性能产生负面影响? 一个应如何在性能与字段长度之间取得平衡?有平衡吗? 问题答案: 这个问题有两个部分: 在VARCHAR上使用NVARCHAR是否会损害性能?是的,将数据存储在unicode字段中会使存储需
-
从3个表中提取MySQL数据-联接和最大值
问题内容: 我有三个mysql表,我想从中提取一些信息,这些表是: 视频-代表带有分数的视频。 标签-包含标签的全局列表。 VideoTags在视频和标签之间创建关联。 我想做的就是找到每个标签的得分最高的视频。有许多具有相同标签的视频,但是我的结果集将具有与标签相同的行数。最终目标是为每个唯一标签(标签是主题加上哈希值)提供最佳视频列表(按得分)。 我的SQL noob尝试实现此目标的方法如下:
-
为什么SQL Server备份比数据库文件大得多?
问题内容: 我有一个带有1.6Gb日志文件的大约13Gb的SQL Server数据库。但是,当我备份它时,它将创建一个50Gb .bak文件!这是为什么? 我在这里阅读了一些有关事务日志的评论,但是我的数据库在笔记本电脑上运行,并且在备份期间没有数据库活动。(仅需5分钟)。 我的备份类型为“完全”,我的恢复类型为“完全”,并且正在执行“仅复制”备份。有任何想法吗?非常感激! 我正在使用SQL 20
-
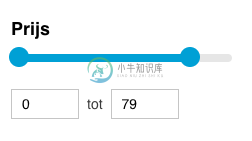 Searchkit范围筛选器数据的最小值和最大值
Searchkit范围筛选器数据的最小值和最大值我在让范围过滤器更具动态性方面遇到了问题。 过滤代码: 而不是硬编码的最小值0和最大值100,我想得到字段verkoopprijs的最小值和最大值。 搜索结果如下所示: 然而我不知道如何得到最小值和最大值。
-
JDBC 结果集获取大型数据集的内部机制
JDBC结果集是否在一次SQL查询的网络调用中提取所有数据?考虑查询< code > select * from table where timestamp